Chaîne de réflexion incitative : libérez la puissance des modèles de langage à grande échelle avec des exemples

Bienvenue dans ce guide complet sur la chaîne de réflexion incitative ! Si vous vous êtes déjà demandé comment améliorer les capacités de raisonnement des grands modèles de langage, vous êtes au bon endroit. Cette technique révolutionne le domaine de l'apprentissage automatique et du traitement du langage naturel.
Dans cet article, nous plongerons dans ce qu'est la chaîne de réflexion incitative, comment elle fonctionne, ses nombreux avantages et ses applications pratiques. Nous explorerons également comment cette technique est appliquée dans différents contextes tels que Langchain, ChatGPT et Python. Alors, commençons !
Qu'est-ce que la chaîne de réflexion incitative ?
La chaîne de réflexion incitative est une technique qui incite les grands modèles de langage à penser de manière logique et séquentielle. Contrairement aux méthodes de sollicitation traditionnelles, la chaîne de réflexion incitative permet au modèle d'évaluer son raisonnement à chaque étape, ce qui lui permet de basculer vers des méthodes alternatives en cas d'erreur. Cela permet d'obtenir des résultats plus précis et fiables.
Comment ça marche ?
L'idée principale est de fournir au modèle de langage une série de sollicitations qui guident son processus de réflexion. Chaque sollicitation sert de "nœud de réflexion", et le modèle doit évaluer la sortie de chaque nœud avant de passer au suivant. De cette manière, le modèle peut se corriger s'il s'écarte de la bonne voie.
Mettre en œuvre la chaîne de réflexion incitative revient à construire une feuille de route pour votre modèle de langage. Voici comment faire :
- Identifier le problème : Définissez clairement le problème à plusieurs étapes que vous voulez que le modèle de langage résolve.
- Découper le problème : Décomposez le problème en tâches ou questions plus petites qui mènent à la solution finale.
- Créer des sollicitations : Pour chaque tâche plus petite, créez une sollicitation qui guide le modèle de langage.
- Exécuter : Donnez ces sollicitations au modèle de langage dans une séquence, en collectant les sorties à chaque étape.
- Analyser et affiner : Évaluez les sorties et affinez les sollicitations si nécessaire.
Exemple : Disons que vous voulez résoudre un problème mathématique consistant à calculer la vitesse moyenne d'une voiture lors d'un trajet. Au lieu de demander directement au modèle de le résoudre, vous pouvez le découper en étapes :
- Calculer la distance totale parcourue.
- Calculer le temps total pris.
- Calculer la vitesse moyenne en utilisant la formule :
Vitesse moyenne = Distance totale / Temps total
Avantages de l'utilisation de la chaîne de réflexion incitative
Raisonnement et résolution de problèmes améliorés
L'un des avantages les plus convaincants de la chaîne de réflexion incitative est sa capacité à améliorer considérablement les capacités de raisonnement des grands modèles de langage. Les modèles de langage traditionnels atteignent souvent une limite lorsqu'ils sont confrontés à des tâches de raisonnement complexes ou à plusieurs étapes. La chaîne de réflexion incitative abat efficacement cette limite.
- Précision : En découpant un problème en tâches plus petites, le modèle peut se concentrer sur chaque étape, ce qui conduit à des résultats plus précis.
- Tâches complexes : Qu'il s'agisse de résoudre des problèmes mathématiques ou de comprendre des scénarios complexes, la chaîne de réflexion incitative permet aux modèles de langage de les gérer de manière efficace.
La chaîne de réflexion incitative dans ChatGPT
Exemples de chaîne de réflexion incitative
La chaîne de réflexion incitative, ou CoT, est une technique de pointe conçue pour rendre les grands modèles de langage tels que ChatGPT plus articulés dans leur raisonnement. Contrairement aux méthodes de sollicitation traditionnelles, la chaîne de réflexion incitative utilise une série d'"exemples de quelques tirs" qui guident le modèle à travers une séquence logique d'étapes. Cela permet d'obtenir des résultats plus précis et fiables.
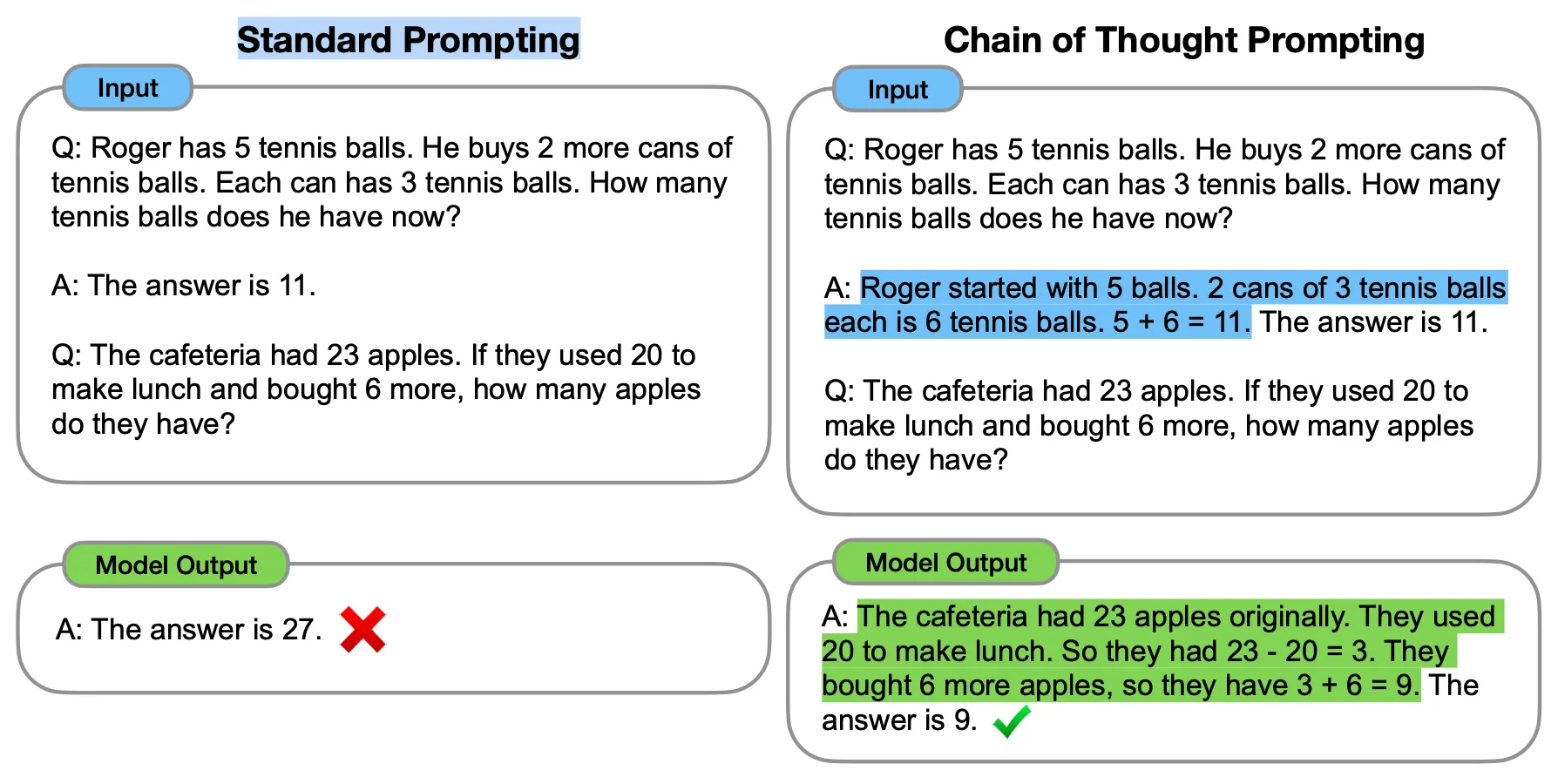
L'idée principale derrière la chaîne de réflexion incitative est d'utiliser ces exemples de quelques tirs pour montrer explicitement le processus de raisonnement. Lorsque le modèle est sollicité de cette manière, il révèle également ses étapes de raisonnement, ce qui conduit à des réponses plus précises et perspicaces.
Bancs d'essai de la chaîne de réflexion incitative
Par exemple, GPT-3 (davinci-003) a été testé avec un simple problème de mots. Initialement, en utilisant la sollicitation traditionnelle, il n'a pas réussi à résoudre le problème. Cependant, lorsque la sollicitation CoT a été appliquée, le modèle a réussi à résoudre le même problème. Cela démontre l'efficacité de la chaîne de réflexion incitative dans l'amélioration des capacités de résolution de problèmes du modèle.
La chaîne de réflexion incitative s'est avérée très efficace pour améliorer les performances des modèles de langage dans différentes tâches, notamment l'arithmétique, le raisonnement de bon sens et le raisonnement symbolique. Plus précisément, les modèles sollicités avec CoT ont atteint une précision de résolution de 57% sur le banc d'essai GSM8K, qui était considéré comme le meilleur à l'époque.
!Bancs d'essai de la chaîne de réflexion incitative](https://raw.githubusercontent.com/lynn-mikami/Images/main/chain-of-thought-prompting-chatgpt-3.webp (opens in a new tab))
Il est bon de noter que la chaîne de réflexion incitative est la plus efficace lorsqu'elle est utilisée avec des modèles plus grands, en particulier ceux qui ont environ 100 milliards de paramètres. Les modèles plus petits ont tendance à produire des chaînes de pensée illogiques, ce qui peut affecter négativement la précision. Par conséquent, les gains de performance de la chaîne de réflexion incitative sont généralement proportionnels à la taille du modèle.
La chaîne de réflexion incitative dans LangChain
Voici comment Langchain utilise la chaîne de réflexion incitative en Python :
from langchain.chains import SequentialChain
# Définir les chaînes
chain1 = ...
chain2 = ...
chain3 = ...
chain4 = ...
# Connecter les chaînes
overall_chain = SequentialChain(chains=[chain1, chain2, chain3, chain4], input_variables=["input", "perfect_factors"], output_variables=["ranked_solutions"], verbose=True)
# Exécuter la chaîne globale
```python
print(ensemble_global({"input": "colonisation humaine de Mars", "facteurs_parfaits": "La distance entre la Terre et Mars est très grande, rendant les ravitaillements réguliers difficiles"}))Ce bout de code montre comment Langchain connecte plusieurs chaînes à l'aide de la classe SequentialChain. La sortie d'une chaîne devient l'entrée de la suivante, permettant ainsi la création d'une chaîne de pensée complexe.
Conclusion
Résumé des points clés
Nous avons exploré le fascinant monde de la Chaîne de pensée incitative (CoT), une technique qui révolutionne le fonctionnement des Modèles de Langage Large (LLM) tels que ChatGPT et Langchain. Contrairement aux méthodes classiques de génération de requêtes, CoT guide le modèle à travers une séquence logique d'étapes, améliorant ainsi sa capacité de raisonnement et de résolution de problèmes. Cela se traduit par des sorties plus précises et fiables, notamment dans les tâches nécessitant un raisonnement complexe.
Pourquoi CoT est une innovation majeure
CoT est bien plus qu'une simple technique nouvelle ; c'est une véritable innovation dans le domaine de l'apprentissage automatique et du traitement du langage naturel. En rendant les modèles plus articulés dans leur raisonnement, CoT ouvre de nouvelles possibilités pour des applications nécessitant une résolution de problèmes complexe et un raisonnement logique. Que ce soit pour des tâches d'arithmétique, de raisonnement de bon sens ou de raisonnement symbolique, CoT s'est avéré grandement améliorer les performances.
FAQ
Qu'est-ce que la chaîne de pensée incitative dans Langchain ?
Dans Langchain, la Chaîne de pensée incitative est mise en œuvre grâce à un algorithme "Tree of Thoughts" (ToT) qui combine les LLM et la recherche heuristique. Elle permet à la plateforme de gérer des tâches de langage plus complexes en guidant le modèle à travers une série d'étapes logiques.
Quelle est la stratégie de la chaîne de pensée incitative ?
La stratégie de la chaîne de pensée incitative consiste à guider le processus de raisonnement d'un modèle à travers une série d'étapes logiques ou de "nœuds de pensée". Chaque nœud sert de requête que le modèle doit évaluer avant de passer au suivant, ce qui lui permet de se corriger en cas de déviation.
Quel est un exemple de chaîne de pensée ?
Un exemple de chaîne de pensée consisterait à décomposer un problème mathématique complexe en tâches plus simples et à les résoudre étape par étape. Par exemple, si le problème consiste à trouver l'aire d'un trapèze, la chaîne de pensée pourrait inclure le calcul de la moyenne des deux côtés parallèles, puis la recherche de la hauteur, et enfin leur multiplication pour obtenir l'aire.
