Récupération-Augmentation de la Génération (RAG): Expliqué Clairement
- Name
- Jennie Rose
Published on
Si vous naviguez dans le paysage complexe des Modèles d'Apprentissage des Langues (LLMs), vous ne pouvez pas ignorer RAG, acronyme de Récupération-Augmentation de la Génération. Cette technique change la donne, offrant une approche nuancée de l'apprentissage automatique et du traitement du langage naturel. Ce guide vise à être votre ressource ultime pour comprendre et implémenter RAG dans les LLMs.
Des scientifiques des données aux novices de l'apprentissage automatique, maîtriser RAG peut être votre arme secrète. Nous couvrirons son architecture, son intégration dans les LLMs, sa comparaison avec l'ajustement fin et son application dans des plateformes comme langChain. Alors, commençons !
Qu'est-ce que RAG ?
Définition de RAG
La Récupération-Augmentation de la Génération (RAG) est un modèle avancé d'apprentissage automatique qui fusionne les capacités de deux types distincts de modèles : un récupérateur et un générateur. En essence, le récupérateur analyse un ensemble de données pour trouver des informations pertinentes, que le générateur utilise ensuite pour construire une réponse détaillée et cohérente.
- Récupérateur : Utilise des algorithmes tels que BM25 ou Récupérateur Dense pour filtrer un corpus et trouver des documents pertinents.
- Générateur : Généralement un modèle basé sur les transformateurs comme BERT, GPT-2 ou GPT-3, qui génère un texte semblable à celui produit par un être humain basé sur les documents récupérés.
Fonctionnement de RAG : Une Analyse Technique Approfondie
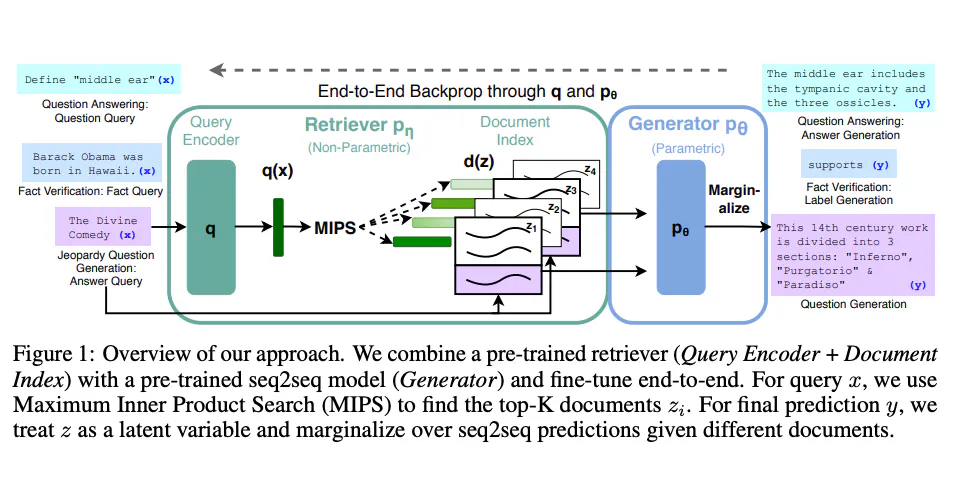
Le modèle RAG fonctionne en deux étapes :
- Étape de Récupération : À partir d'une requête, le récupérateur analyse un corpus et extrait les
Ndocuments les plus pertinents. Cela se fait souvent à l'aide d'une mesure de similarité comme la similarité cosinus.
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
vectorizer = TfidfVectorizer()
tfidf_matrix = vectorizer.fit_transform(corpus)
query_vector = vectorizer.transform([query])
similarity_scores = cosine_similarity(query_vector, tfidf_matrix)- Étape de Génération : Le générateur utilise ces
Ndocuments et la requête initiale pour générer une réponse cohérente.
from transformers import RagTokenizer, RagRetriever, RagTokenForGeneration
tokenizer = RagTokenizer.from_pretrained("facebook/rag-token-base")
retriever = RagRetriever.from_pretrained("facebook/rag-token-base", index_name="exact", use_dummy_dataset=True)
model = RagTokenForGeneration.from_pretrained("facebook/rag-token-base", retriever=retriever)
input_ids = tokenizer(query, return_tensors='pt').input_ids
outputs = model.generate(input_ids)
generated = tokenizer.decode(outputs[0], skip_special_tokens=True)En combinant ces deux étapes, RAG peut répondre à des requêtes complexes avec des réponses détaillées et pertinentes sur le plan contextuel.
Comment Utiliser RAG pour les LLMs
Configuration de RAG pour les LLMs
Pour implémenter RAG dans les LLMs, vous aurez besoin de :
- Un corpus : Celui-ci peut prendre la forme d'une base de données SQL, d'Elasticsearch ou d'un simple fichier JSON.
- Un framework d'apprentissage automatique : TensorFlow ou PyTorch sont couramment utilisés.
- Des ressources informatiques : Une puissance de calcul adéquate pour l'entraînement et l'inférence.
Étapes pour Implémenter RAG dans les LLMs
Voici un guide étape par étape pour implémenter RAG dans votre LLM :
- Préparation des Données : Votre corpus doit être dans un format permettant la recherche. Si vous utilisez Elasticsearch, assurez-vous d'indexer vos données.
curl -X PUT "localhost:9200/my_index"-
Sélection du Modèle : Choisissez vos modèles de récupérateur et de générateur. Vous pouvez utiliser des modèles pré-entraînés ou entraîner les vôtres.
-
Entraînement : Entraînez les modèles de récupérateur et de générateur. Cela est souvent fait séparément.
retriever.train()
generator.train()- Intégration : Combinez les modèles de récupérateur et de générateur entraînés en un seul modèle RAG.
model_rag = ModelRag(retriever, generator)- Test : Validez les performances du modèle en utilisant différentes mesures comme BLEU pour évaluer la qualité de la génération de texte et recall@k pour évaluer l'exactitude de la récupération.
En suivant ces étapes, vous obtiendrez un modèle RAG robuste pouvant être intégré dans divers LLMs pour des performances supérieures.
Fonctions Utilitaires dans RAG pour les LLMs
Pour évaluer votre modèle RAG, vous pouvez utiliser des fonctions utilitaires comme get_retrieval_score() qui évaluent les performances du récupérateur. Cette fonction utilise généralement des mesures telles que la précision@k ou le NDCG pour l'évaluation.
from sklearn.metrics import ndcg_score
ndcg = ndcg_score(y_true, y_score)Cette fonction peut être précieuse pour affiner les performances de votre récupérateur, en veillant à ce qu'il extrait les documents les plus pertinents du corpus.
RAG vs Ajustement Fin
Ce qui différencie RAG de l'ajustement fin ?
Bien que RAG et l'ajustement fin visent tous deux à améliorer les performances des Modèles d'Apprentissage de Langues (LLMs), ils abordent la tâche différemment. L'ajustement fin modifie un modèle pré-entraîné existant pour mieux s'adapter à une tâche ou à un ensemble de données spécifique. RAG, en revanche, combine des mécanismes de récupération et de génération pour répondre à des requêtes complexes.
- Ajustement Fin : Implique d'ajuster les poids d'un modèle pré-entraîné pendant la phase d'entraînement sur un ensemble de données spécifique.
- RAG : Fusionne un récupérateur et un générateur pour extraire des informations pertinentes d'un corpus et ensuite générer une réponse cohérente.
Comparaison Technique : RAG vs Ajustement Fin
- Charge de Calcul :
- RAG : Nécessite plus de ressources de calcul car il implique deux modèles distincts.
- Ajustement Fin : Généralement moins intensif du point de vue du calcul.
- Flexibilité :
- RAG: Hautement flexible, peut s'adapter à différents types de requêtes.
- Fine-Tuning: Limité à la tâche spécifique pour laquelle il a été affiné.
- Exigences en matière de données:
- RAG: Nécessite un corpus bien structuré et volumineux pour la récupération.
- Fine-Tuning: Nécessite un ensemble de données spécifique à la tâche pour l'entraînement.
- Complexité de l'implémentation:
- RAG: Plus complexe en raison de l'intégration de deux modèles.
- Fine-Tuning: Relativement simple.
Code d'exemple: RAG vs Fine-Tuning
Pour RAG:
# Utilisation de la bibliothèque Transformers de Hugging Face
from transformers import RagModel
rag_model = RagModel.from_pretrained("facebook/rag-token-nq")Pour Fine-Tuning:
# Affinage d'un modèle BERT en utilisant PyTorch
from transformers import BertForSequenceClassification
model = BertForSequenceClassification.from_pretrained("bert-base-uncased")
model.train()En comprenant ces différences, vous pouvez faire un choix éclairé sur l'approche qui convient le mieux à votre projet LLM.
Comment utiliser RAG pour les applications LLM
Intégration de RAG dans les LLM existants
Si vous avez déjà un LLM et que vous souhaitez incorporer RAG, suivez ces étapes:
-
Identifier l'utilisation: Déterminez ce que vous voulez réaliser avec RAG, que ce soit une meilleure réponse aux questions, une résumé, ou autre chose.
-
Alignement des données: Assurez-vous que votre corpus existant est compatible avec le récupérateur que vous prévoyez d'utiliser dans RAG.
-
Intégration du modèle: Intégrez le modèle RAG dans l'architecture de votre LLM existant.
# Exemple en utilisant PyTorch
class MyLLMAvecRAG(nn.Module):
def __init__(self, mon_llm, rag_model):
super(MyLLMAvecRAG, self).__init__()
self.mon_llm = mon_llm
self.rag_model = rag_model- Tests et validation: Effectuez des tests pour valider que le modèle RAG améliore les performances de votre LLM.
Pièges courants et comment les éviter
- Corpus inadéquat: Assurez-vous que votre corpus est suffisamment grand et diversifié pour que le récupérateur puisse trouver des documents pertinents.
- Incompatibilité des modèles: Le récupérateur et le générateur doivent être compatibles en termes de types de données et de dimensions.
En intégrant soigneusement RAG dans vos applications LLM, vous pouvez améliorer considérablement leurs capacités et leurs performances.
Comment utiliser RAG avec langChain
Qu'est-ce que langChain ?
langChain est une plateforme décentralisée pour les modèles de langage. Elle permet l'intégration de divers modèles d'apprentissage automatique, y compris RAG, pour offrir des services de traitement du langage naturel améliorés.
Étapes pour mettre en œuvre RAG dans langChain
-
Installation: Installez le SDK de langChain et configurez votre environnement de développement.
-
Téléchargement du modèle: Chargez votre modèle RAG pré-entraîné sur la plateforme langChain.
langChain upload --model mon_modele_rag- Intégration de l'API: Utilisez l'API de langChain pour intégrer le modèle RAG dans votre application.
from langChain import RagService
rag_service = RagService(api_key="votre_cle_api")- Exécution des requêtes: Exécutez des requêtes via la plateforme langChain, qui utilisera votre modèle RAG pour générer des réponses.
response = rag_service.query("Quelle est la signification de la vie ?")En suivant ces étapes, vous pouvez intégrer RAG de manière transparente dans langChain, en exploitant ainsi l'architecture décentralisée de la plateforme pour des performances et une évolutivité améliorées.
Conclusion
RAG est un outil puissant qui peut considérablement améliorer les capacités des modèles d'apprentissage automatique du langage. Que vous souhaitiez l'intégrer dans des LLM existants, le comparer aux méthodes d'affinage, ou même l'utiliser dans des plateformes décentralisées comme langChain, comprendre RAG peut vous donner un avantage distinct. Avec ses mécanismes de récupération et de génération, RAG offre une approche nuancée pour les requêtes complexes, ce qui en fait un atout précieux dans le domaine de l'apprentissage automatique et du traitement du langage naturel.
FAQ
Qu'est-ce que RAG dans les LLM ?
RAG, ou Retrieval-Augmented Generation, est une technique qui combine un récupérateur et un générateur pour répondre à des requêtes complexes dans les modèles d'apprentissage automatique du langage.
Quelle est la différence entre RAG et LLM ?
RAG est une technique spécifique utilisée pour améliorer les capacités des LLM. Ce n'est pas un modèle autonome, mais plutôt un composant qui peut être intégré dans des LLM existants.
Comment évalue-t-on un LLM RAG ?
Des métriques d'évaluation telles que BLEU pour la qualité de la génération de texte et recall@k pour l'exactitude de la récupération sont couramment utilisées.
Quelle est la différence entre RAG et l'affinage ?
RAG combine des mécanismes de récupération et de génération, tandis que l'affinage consiste à modifier un modèle existant pour l'adapter à une tâche spécifique.
Quels sont les avantages des LLM RAG ?
RAG permet des réponses plus nuancées et contextuellement pertinentes, ce qui le rend très efficace pour les requêtes complexes.
