リトリーバル拡張生成(RAG):わかりやすく説明します
- Name
- Jennie Rose
Published on
言語学習モデル(LLM)の複雑な領域をナビゲートする場合、リトリーバル拡張生成(RAG)を見落とすことは許されません。この技術はゲームチェンジャーであり、機械学習と自然言語処理に対して繊細なアプローチを提供します。このガイドは、LLM内でのRAGの理解と実装における究極のリソースとなることを目指しています。
データサイエンティストから機械学習初心者まで、RAGをマスターすることはあなたの秘密の武器となります。私たちはアーキテクチャ、LLMへの統合、ファインチューニングとの比較、langChainのようなプラットフォームでの応用についてカバーします。さあ、始めましょう!
RAGとは?
RAGの定義
リトリーバル拡張生成(RAG)は、リトリーバとジェネレータという2つの異なるタイプのモデルの能力をマージした、高度な機械学習モデルです。要するに、リトリーバはデータセットをスキャンして関連情報を見つけ、ジェネレータはその情報を使用して詳細で一貫した応答を構築します。
- リトリーバ: BM25やDense Retrieverなどのアルゴリズムを使用して、コーパスをスキャンして関連するドキュメントを見つけます。
- ジェネレータ: BERT、GPT-2、またはGPT-3のようなtransformerベースのモデルであり、取得したドキュメントに基づいて人間らしいテキストを生成します。
RAGの動作:技術的な深堀り
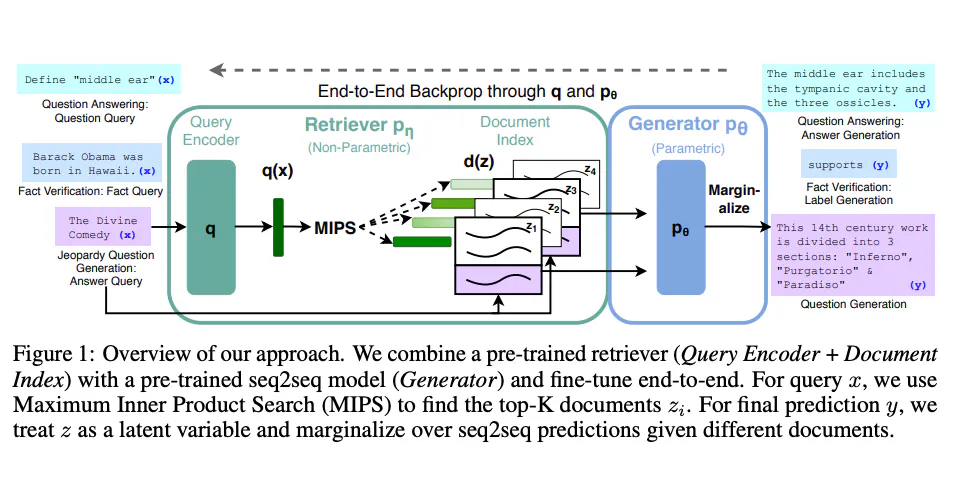
RAGモデルは次の2つのステップで動作します。
-
リトリーバルステップ: クエリが与えられると、リトリーバはコーパスをスキャンし、
N個の最も関連性が高いドキュメントを取得します。これは通常、コサイン類似性のような類似度尺度を使用して行われます。from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.metrics.pairwise import cosine_similarity vectorizer = TfidfVectorizer() tfidf_matrix = vectorizer.fit_transform(corpus) query_vector = vectorizer.transform([query]) similarity_scores = cosine_similarity(query_vector, tfidf_matrix) -
ジェネレーションステップ: ジェネレータはこれらの
N個のドキュメントと元のクエリを受け取り、一貫した応答を生成します。from transformers import RagTokenizer, RagRetriever, RagTokenForGeneration tokenizer = RagTokenizer.from_pretrained("facebook/rag-token-base") retriever = RagRetriever.from_pretrained("facebook/rag-token-base", index_name="exact", use_dummy_dataset=True) model = RagTokenForGeneration.from_pretrained("facebook/rag-token-base", retriever=retriever) input_ids = tokenizer(query, return_tensors="pt").input_ids outputs = model.generate(input_ids) generated = tokenizer.decode(outputs[0], skip_special_tokens=True)
これらの2つのステップを組み合わせることで、RAGは複雑なクエリに対して詳細で文脈に即した応答を行うことができます。
LLMにおけるRAGの使用方法
LLMへのRAGのセットアップ
LLMにRAGを実装するには、以下が必要です。
- コーパス:これはSQLデータベース、Elasticsearch、または単純なJSONファイル形式のいずれかになります。
- 機械学習フレームワーク:TensorFlowまたはPyTorchが一般的に使用されます。
- コンピューティングリソース:トレーニングおよび推論に適した適切なCPU/GPU。
LLMにRAGを実装する手順
LLMにRAGを実装するためのステップバイステップガイドは次のとおりです。
-
データの準備: コーパスは検索可能な形式にする必要があります。Elasticsearchを使用する場合は、データをインデックス化しておく必要があります。
curl -X PUT "localhost:9200/my_index" -
モデルの選択: リトリーバとジェネレータのモデルを選択します。事前に学習済みのモデルを使用するか、独自にトレーニングすることができます。
-
トレーニング: リトリーバとジェネレータのモデルをトレーニングします。これは通常、別々に行われます。
retriever.train() generator.train() -
統合: トレーニングされたリトリーバとジェネレータを単一のRAGモデルに統合します。
rag_model = RagModel(retriever, generator) -
テスト: BLEUなどのテキスト生成品質指標やリコール@kなどの検索精度などのさまざまなメトリクスを使用して、モデルのパフォーマンスを検証します。
これらのステップに従うことで、優れたパフォーマンスを発揮するさまざまなLLMにRAGモデルを統合することができます。
LLMにおけるRAGのユーティリティ関数
RAGモデルを評価するために、get_retrieval_score()のようなユーティリティ関数を使用することができます。この関数は通常、評価のためにPresicion@kやNDCGなどのメトリクスを使用します。
from sklearn.metrics import ndcg_score
ndcg = ndcg_score(y_true, y_score)この関数は、リトリーバのパフォーマンスをファインチューニングする際に非常に役立ちます。これにより、コーパスから最も関連性の高いドキュメントを取得できるようになります。
RAGとファインチューニングの比較
RAGとファインチューニングの違いは何ですか?
RAGとファインチューニングは、言語学習モデル(LLM)のパフォーマンスを向上させることを目的としていますが、タスクに対するアプローチが異なります。ファインチューニングは、既存の事前学習済みモデルを特定のタスクやデータセットに適応するために重みを調整します。一方、RAGはリトリーバとジェネレーションのメカニズムを組み合わせて複雑なクエリに応えます。
- ファインチューニング: トレーニングフェーズで既存の事前学習済みモデルの重みを調整することです。
- RAG: リトリーバとジェネレータを組み合わせて、コーパスから関連情報を取得し、一貫した応答を生成します。
技術的な比較:RAG vs ファインチューニング
-
計算負荷:
- RAG: 2つの別々のモデルが関与するため、より多くの計算リソースを必要とします。
- ファインチューニング: 一般的に計算負荷が少ないです。
-
柔軟性:
- RAG: 高い柔軟性があり、さまざまな種類のクエリに対応できます。
- Fine-Tuning: 特定のタスクに限定されます。
-
データの要件:
- RAG: 検索のために大規模かつよく構造化されたコーパスが必要です。
- Fine-Tuning: トレーニング用のタスク固有のデータセットが必要です。
-
実装の複雑さ:
- RAG: 2つのモデルを統合するため、より複雑です。
- Fine-Tuning: 比較的簡単です。
サンプルコード: RAG vs Fine-Tuning
RAGの場合:
# Hugging FaceのTransformersライブラリを使用
from transformers import RagModel
rag_model = RagModel.from_pretrained("facebook/rag-token-nq")Fine-Tuningの場合:
# PyTorchを使用してBERTモデルをFine-Tuningする
from transformers import BertForSequenceClassification
model = BertForSequenceClassification.from_pretrained("bert-base-uncased")
model.train()これらの違いを理解することで、LLMプロジェクトに最適なアプローチを選択できます。
LLMアプリケーションでのRAGの使用方法
既存のLLMにRAGを組み込む方法
既存のLLMにRAGを組み込む場合は、以下の手順に従ってください:
-
ユースケースの特定: RAGで達成したいことを決定します - 質問応答の改善、要約の改善など。
-
データの整合性: 使用するRAGのリトリーバーと互換性のある既存のコーパスを確認します。
-
モデルの統合: RAGモデルを既存のLLMアーキテクチャに統合します。
# PyTorchを使った例 class MyLLMWithRAG(nn.Module): def __init__(self, my_llm, rag_model): super(MyLLMWithRAG, self).__init__() self.my_llm = my_llm self.rag_model = rag_model -
テストと検証: RAGモデルがLLMのパフォーマンスを向上させているかどうかを検証するためにテストを実行します。
よくある問題と回避方法
- 不適切なコーパス: リトリーバーが関連するドキュメントを見つけるためにコーパスが十分に大規模かつ多様であることを確認してください。
- モデルの不一致: リトリーバーとジェネレーターはデータのタイプや次元の面で互換性がある必要があります。
RAGをLLMアプリケーションに注意深く統合することで、その機能とパフォーマンスを大幅に向上させることができます。
langChainでのRAGの使用方法
langChainとは何ですか?
langChainは言語モデルのための分散型プラットフォームです。RAGを含むさまざまな機械学習モデルを統合し、高度な自然言語処理のサービスを提供します。
langChainにRAGを実装する手順
-
インストール: langChain SDKをインストールし、開発環境を設定します。
-
モデルのアップロード: 事前学習済みのRAGモデルをlangChainプラットフォームにアップロードします。
langChain upload --model my_rag_model -
APIの統合: langChainのAPIを使用してRAGモデルをアプリケーションに統合します。
from langChain import RagService rag_service = RagService(api_key="your_api_key") -
クエリの実行: langChainプラットフォームを介してクエリを実行し、RAGモデルを使用して応答を生成します。
response = rag_service.query("人生の意味は何ですか?")
これらの手順に従うことで、langChainにRAGをシームレスに統合し、プラットフォームの分散アーキテクチャを活用してパフォーマンスとスケーラビリティを向上させることができます。
結論
RAGは言語学習モデルの能力を大幅に向上させる強力なツールです。既存のLLMに組み込む、Fine-Tuningの手法と比較する、またはlangChainのような分散プラットフォームで使用するなど、RAGを理解することで明確な優位性を得ることができます。検索と生成の二つのメカニズムを持つRAGは複雑なクエリに対して洞察力のあるアプローチを提供し、機械学習と自然言語処理の分野で貴重な資産となります。
よくある質問
LLMにおけるRAGとは何ですか?
RAG(Retrieval-Augmented Generation)は、リトリーバーとジェネレーターを組み合わせて言語学習モデルで複雑なクエリに答える技術です。
ragとLLMの違いは何ですか?
RAGはLLMの能力を向上させるための具体的な技術です。単体のモデルではなく、既存のLLMに組み込むためのコンポーネントです。
ragのLLMを評価する方法はありますか?
テキスト生成の品質に対するBLEUやリトリーバーの精度に対するrecall@kなどの評価指標が一般的に使用されます。
ragとFine-Tuningの違いは何ですか?
RAGはリトリーバーとジェネレーションのメカニズムを組み合わせたものであり、Fine-Tuningは既存のモデルを特定のタスクに適応させることを意味します。
rag LLMの利点は何ですか?
RAGはより洞察力のある文脈に即した応答を可能にし、複雑なクエリに対して非常に効果的です。
