Retrieval-Augmented Generation (RAG): Clearly Explained
- Name
- Jennie Rose
Published on
If you're navigating the intricate landscape of Language Learning Models (LLMs), you can't afford to overlook RAG, short for Retrieval-Augmented Generation. This technique is a game-changer, offering a nuanced approach to machine learning and natural language processing. This guide aims to be your ultimate resource for understanding and implementing RAG in LLMs.
From data scientists to machine learning newbies, mastering RAG can be your secret weapon. We'll cover its architecture, its integration into LLMs, its comparison with fine-tuning, and its application in platforms like langChain. So, let's get started!
What is RAG?
Definition of RAG
Retrieval-Augmented Generation (RAG) is an advanced machine learning model that merges the capabilities of two distinct types of models: a retriever and a generator. In essence, the retriever scans a dataset to find relevant information, which the generator then uses to construct a detailed and coherent response.
- Retriever: Utilizes algorithms like BM25 or Dense Retriever to sift through a corpus and find relevant documents.
- Generator: Typically a transformer-based model like BERT, GPT-2, or GPT-3 that generates human-like text based on the retrieved documents.
How RAG Works: A Technical Deep Dive
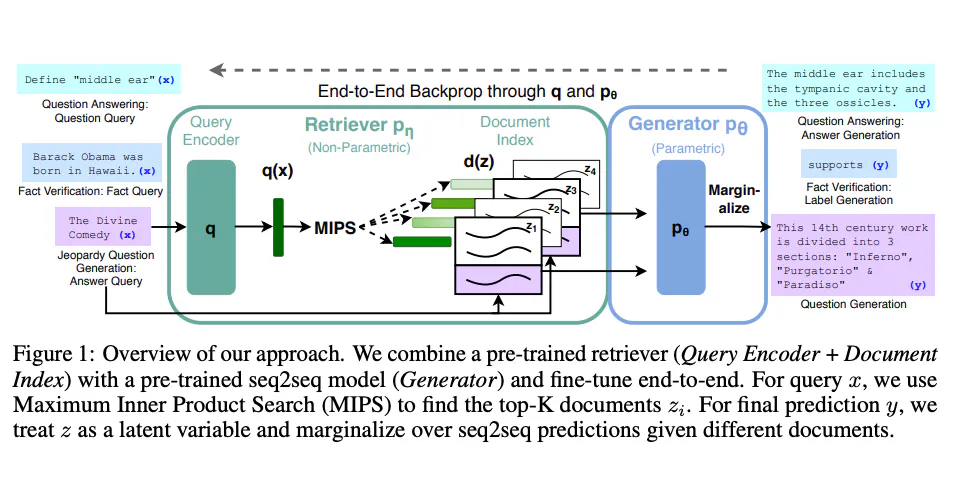
The RAG model operates in a two-step process:
-
Retrieval Step: Given a query, the retriever scans the corpus and retrieves
Nmost relevant documents. This is often done using a similarity metric like cosine similarity.from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.metrics.pairwise import cosine_similarity vectorizer = TfidfVectorizer() tfidf_matrix = vectorizer.fit_transform(corpus) query_vector = vectorizer.transform([query]) similarity_scores = cosine_similarity(query_vector, tfidf_matrix) -
Generation Step: The generator takes these
Ndocuments and the original query to generate a coherent response.from transformers import RagTokenizer, RagRetriever, RagTokenForGeneration tokenizer = RagTokenizer.from_pretrained("facebook/rag-token-base") retriever = RagRetriever.from_pretrained("facebook/rag-token-base", index_name="exact", use_dummy_dataset=True) model = RagTokenForGeneration.from_pretrained("facebook/rag-token-base", retriever=retriever) input_ids = tokenizer(query, return_tensors="pt").input_ids outputs = model.generate(input_ids) generated = tokenizer.decode(outputs[0], skip_special_tokens=True)
By combining these two steps, RAG can answer complex queries with detailed, contextually relevant responses.
How to Use RAG for LLMs
Setting Up RAG for LLMs
To implement RAG in LLMs, you'll need:
- A corpus: This could be in the form of a SQL database, Elasticsearch, or a simple JSON file.
- A machine learning framework: TensorFlow or PyTorch are commonly used.
- Computing resources: Adequate CPU/GPU for training and inference.
Steps to Implement RAG in LLMs
Here's a step-by-step guide to implementing RAG in your LLM:
-
Data Preparation: Your corpus needs to be in a searchable format. If you're using Elasticsearch, make sure to index your data.
curl -X PUT "localhost:9200/my_index" -
Model Selection: Choose your retriever and generator models. You can use pre-trained models or train your own.
-
Training: Train the retriever and generator models. This is often done separately.
retriever.train() generator.train() -
Integration: Combine the trained retriever and generator into a single RAG model.
rag_model = RagModel(retriever, generator) -
Testing: Validate the model's performance using various metrics like BLEU for text generation quality and recall@k for retrieval accuracy.
By following these steps, you'll have a robust RAG model that can be integrated into various LLMs for superior performance.
Utility Functions in RAG for LLMs
To evaluate your RAG model, you can use utility functions like get_retrieval_score() that assess how well the retriever is performing. This function typically uses metrics like Precision@k or NDCG for evaluation.
from sklearn.metrics import ndcg_score
ndcg = ndcg_score(y_true, y_score)This function can be invaluable for fine-tuning your retriever's performance, ensuring that it fetches the most relevant documents from the corpus.
RAG vs Fine-Tuning
What Sets RAG and Fine-Tuning Apart?
While both RAG and fine-tuning aim to enhance the performance of Language Learning Models (LLMs), they approach the task differently. Fine-tuning modifies an existing pre-trained model to better adapt to a specific task or dataset. RAG, on the other hand, combines retrieval and generation mechanisms to answer complex queries.
- Fine-Tuning: Involves adjusting the weights of a pre-trained model during the training phase on a specific dataset.
- RAG: Merges a retriever and a generator to pull relevant information from a corpus and then generate a coherent response.
Technical Comparison: RAG vs Fine-Tuning
-
Computational Load:
- RAG: Requires more computational resources as it involves two separate models.
- Fine-Tuning: Generally less computationally intensive.
-
Flexibility:
- RAG: Highly flexible, can adapt to various types of queries.
- Fine-Tuning: Limited to the specific task it was fine-tuned for.
-
Data Requirements:
- RAG: Requires a large, well-structured corpus for retrieval.
- Fine-Tuning: Needs a task-specific dataset for training.
-
Implementation Complexity:
- RAG: More complex due to the integration of two models.
- Fine-Tuning: Relatively straightforward.
Sample Code: RAG vs Fine-Tuning
For RAG:
# Using Hugging Face's Transformers library
from transformers import RagModel
rag_model = RagModel.from_pretrained("facebook/rag-token-nq")For Fine-Tuning:
# Fine-tuning a BERT model using PyTorch
from transformers import BertForSequenceClassification
model = BertForSequenceClassification.from_pretrained("bert-base-uncased")
model.train()By understanding these differences, you can make an informed choice about which approach best suits your LLM project.
How to Use RAG for LLM Applications
Incorporating RAG into Existing LLMs
If you already have an LLM and want to incorporate RAG, follow these steps:
-
Identify the Use-Case: Determine what you want to achieve with RAG—whether it's better question-answering, summarization, or something else.
-
Data Alignment: Make sure your existing corpus is compatible with the retriever you plan to use in RAG.
-
Model Integration: Integrate the RAG model into your existing LLM architecture.
# Example using PyTorch class MyLLMWithRAG(nn.Module): def __init__(self, my_llm, rag_model): super(MyLLMWithRAG, self).__init__() self.my_llm = my_llm self.rag_model = rag_model -
Testing and Validation: Run tests to validate that the RAG model is improving your LLM's performance.
Common Pitfalls and How to Avoid Them
- Inadequate Corpus: Ensure your corpus is large and diverse enough for the retriever to find relevant documents.
- Mismatched Models: The retriever and generator should be compatible in terms of data types and dimensions.
By carefully integrating RAG into your LLM applications, you can significantly enhance their capabilities and performance.
How to Use RAG with langChain
What is langChain?
langChain is a decentralized platform for language models. It allows for the integration of various machine learning models, including RAG, to offer enhanced natural language processing services.
Steps to Implement RAG in langChain
-
Installation: Install the langChain SDK and set up your development environment.
-
Model Upload: Upload your pre-trained RAG model to the langChain platform.
langChain upload --model my_rag_model -
API Integration: Use langChain's API to integrate the RAG model into your application.
from langChain import RagService rag_service = RagService(api_key="your_api_key") -
Query Execution: Execute queries through the langChain platform, which will utilize your RAG model for generating responses.
response = rag_service.query("What is the meaning of life?")
By following these steps, you can seamlessly integrate RAG into langChain, thereby leveraging the platform's decentralized architecture for enhanced performance and scalability.
Conclusion
RAG is a powerful tool that can significantly elevate the capabilities of Language Learning Models. Whether you're looking to integrate it into existing LLMs, compare it with fine-tuning methods, or even use it in decentralized platforms like langChain, understanding RAG can give you a distinct edge. With its dual mechanisms of retrieval and generation, RAG offers a nuanced approach to complex queries, making it an invaluable asset in the field of machine learning and natural language processing.
FAQs
What is RAG in LLM?
RAG, or Retrieval-Augmented Generation, is a technique that combines a retriever and a generator to answer complex queries in Language Learning Models.
What is the difference between rag and LLM?
RAG is a specific technique used to enhance the capabilities of LLMs. It is not a standalone model but rather a component that can be integrated into existing LLMs.
How do you evaluate a rag LLM?
Evaluation metrics like BLEU for text generation quality and recall@k for retrieval accuracy are commonly used.
What is rag vs fine-tuning?
RAG combines retrieval and generation mechanisms, while fine-tuning involves modifying an existing model to adapt to a specific task.
What are the benefits of rag LLM?
RAG allows for more nuanced and contextually relevant responses, making it highly effective for complex queries.
