LLaVA: Le Modèle Multimodal Open-Source Qui Change La Donne

Le monde de l'IA et de l'apprentissage automatique évolue constamment, avec de nouveaux modèles et technologies qui émergent à un rythme effréné. L'un de ces nouveaux venus qui a capté l'attention des passionnés de technologie et des experts est LLaVA. Ce modèle multimodal open-source est bien plus qu'un simple ajout à un espace déjà encombré ; c'est un game-changer qui établit de nouveaux benchmarks.
Ce qui distingue LLaVA, c'est son mélange unique de traitement du langage naturel et de capacités de vision par ordinateur. Ce n'est pas seulement un outil ; c'est une révolution qui est en passe de redéfinir notre façon d'interagir avec la technologie. Et la meilleure partie ? C'est open-source, ce qui le rend accessible à quiconque souhaite explorer son vaste potentiel.
Vous voulez être au courant des dernières nouvelles sur LLM ? Consultez le dernier classement LLM !
Qu'est-ce que LLaVA ?
LLaVA, ou Large Language and Vision Assistant, est un modèle multimodal conçu pour interpréter à la fois le texte et les images. En termes simples, c'est un outil qui comprend non seulement ce que vous tapez, mais aussi ce que vous lui montrez. Cela le rend incroyablement polyvalent, ouvrant la voie à de nombreuses applications qui étaient auparavant considérées comme difficiles à mettre en œuvre.
🚨 BREAKING: GPT-4 reconnaissances d'images a déjà un nouveau concurrent. Ouvert et totalement gratuit.Introduction de LLaVA: Large Language and Vision Assistant.J'ai comparé la photo virale de l'espace de stationnement sur GPT-4 Vision à LLaVa et cela a parfaitement fonctionné (voir la vidéo). pic.twitter.com/0V0citjEZs
— Rowan Cheung (@rowancheung) 7 octobre 2023
Caractéristiques clés de LLaVA
- Capacités multimodales : LLaVA peut traiter à la fois le texte et les images, ce qui en fait un modèle vraiment polyvalent.
- 13 milliards de paramètres : Le modèle compte pas moins de 13 milliards de paramètres, établissant ainsi un nouveau record dans l'espace multimodal des modèles de langage volumineux (LLM).
- Open-Source : Contrairement à bon nombre de ses concurrents, LLaVA est open-source, ce qui signifie que vous pouvez plonger dans son code source pour comprendre son fonctionnement ou même contribuer à son développement.
La nature open-source de LLaVA est particulièrement remarquable. Cela signifie que n'importe qui, qu'il s'agisse d'un étudiant en université ou d'un développeur chevronné, peut accéder à son code source, comprendre son fonctionnement interne et même contribuer à son développement. Cette démocratisation de la technologie fait de LLaVA non seulement un modèle, mais aussi un projet animé par une communauté.
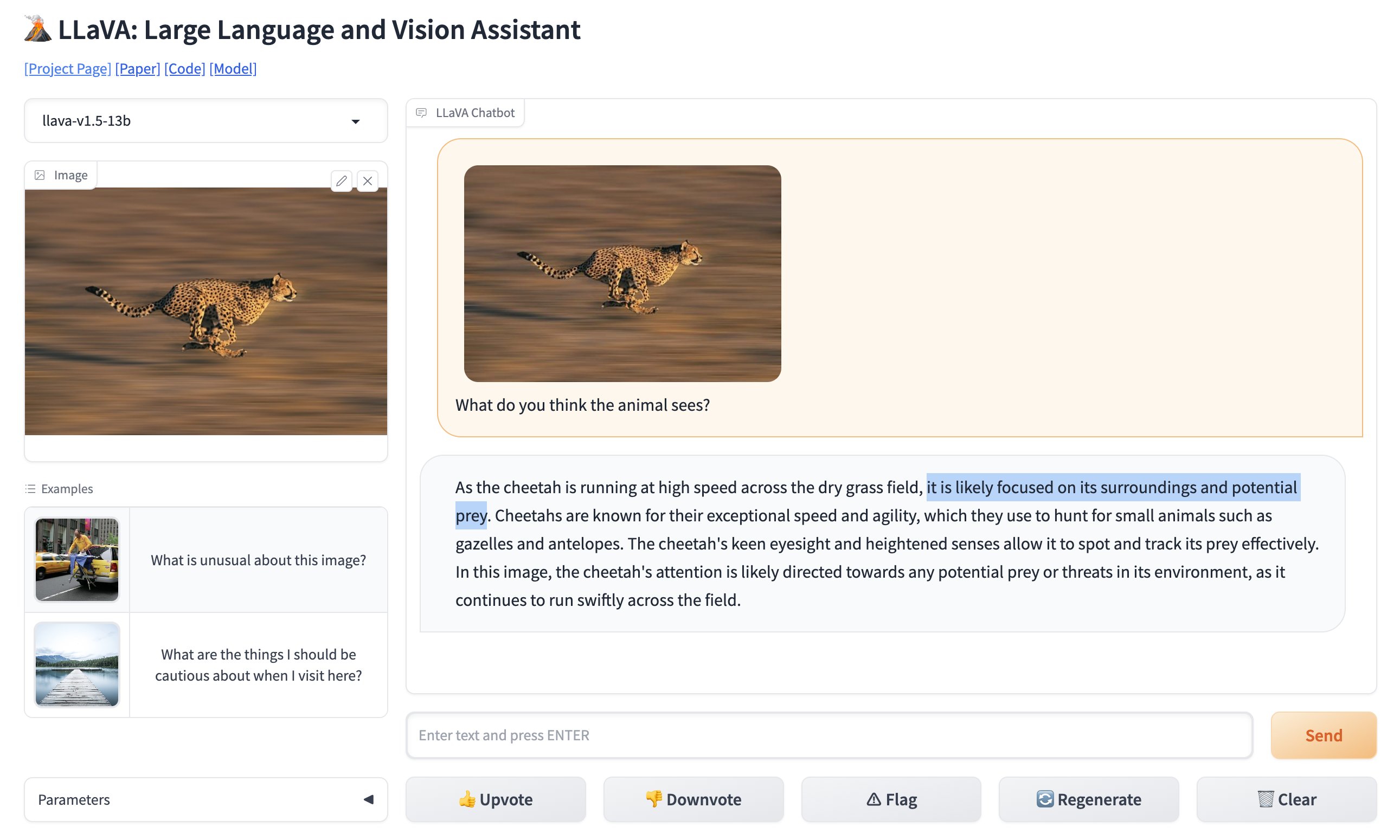
Vous pouvez tester la version en ligne de LLaVA ici (opens in a new tab).
Aspects techniques qui distinguent LLaVA
En ce qui concerne l'aspect technique, LLaVA utilise l'encodeur Contrastive Language-Image Pretraining (CLIP) pour la partie vision et le combine avec une couche Multilayer Perceptron (MLP) pour la partie langage. Cette synergie lui permet d'accomplir des tâches qui nécessitent une compréhension à la fois du texte et des images. Par exemple, vous pouvez demander à LLaVA de décrire une image, et il le fera avec une précision remarquable.
Voici un extrait de code d'exemple qui montre comment utiliser l'encodeur CLIP de LLaVA :
# Importer l'encodeur CLIP
from clip_encoder import CLIP
# Initialiser l'encodeur
clip = CLIP()
# Charger une image
image_path = "sample_image.jpg"
image = clip.load_image(image_path)
# Obtenir les caractéristiques de l'image
image_features = clip.get_image_features(image)
# Afficher les caractéristiques
print("Caractéristiques de l'image :", image_features)Ce niveau de détail technique, associé à sa nature open-source, fait de LLaVA un modèle qui vaut la peine d'être exploré, que vous soyez un développeur cherchant à intégrer des fonctionnalités avancées dans votre application ou un chercheur désireux de repousser les limites de ce qui est possible dans le domaine de l'IA et de l'apprentissage automatique.
Aspects techniques et comparaison des performances : LLaVA vs GPT-4V
En ce qui concerne les aspects techniques, LLaVA est un modele redoutable. Il est conçu pour être un modèle multimodal, ce qui signifie qu'il peut traiter à la fois le texte et les images, une fonctionnalité qui le distingue des modèles texte uniquement comme GPT-4.
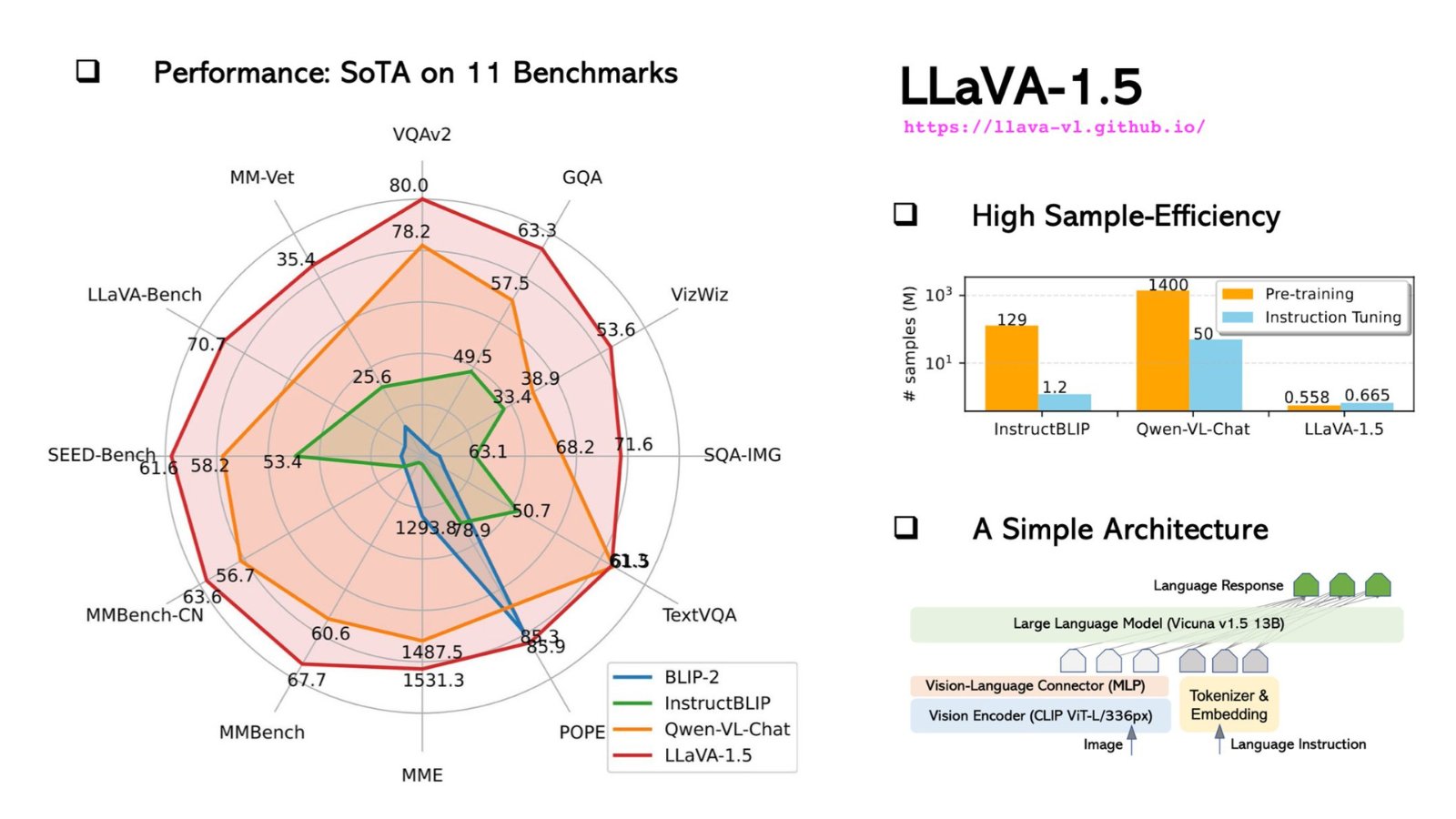
Spécifications techniques de LLaVA
Plongeons-nous dans les détails techniques :
-
Architecture : LLaVA et GPT-4 sont tous deux construits sur une architecture basée sur Transformer. Cependant, LLaVA intègre des couches supplémentaires spécifiquement conçues pour le traitement d'images, ce qui en fait un choix plus polyvalent pour les tâches multimodales.
-
Paramètres : LLaVA dispose de pas moins de 175 milliards de paramètres d'apprentissage automatique, tout comme GPT-4. Ces paramètres sont les aspects des données à partir desquels le modèle apprend lors de la formation, et plus de paramètres signifient généralement de meilleures performances, mais au prix de ressources de calcul supplémentaires.
-
Données d'entraînement : LLaVA est entraîné sur un ensemble de données diversifié qui inclut non seulement du texte, mais aussi des images, ce qui en fait un modèle vraiment multimodal. En revanche, GPT-4 est entraîné uniquement sur un corpus de texte.
-
Spécialisation : LLaVA dispose d'une version spécialisée appelée LLaVA-Med, qui est adaptée aux applications biomédicales. GPT-4 ne dispose pas de telles versions spécialisées.
Voici un tableau résumant ces spécifications techniques :
| Caractéristique | LLaVA | GPT-4 |
|---|---|---|
| Architecture | Transformer + Couches d'image | Transformateur |
| Parameters | 175 milliards | 175 milliards |
| Training Data | Multimodal (Texte, Images) | Texte seulement |
| Spécialisation | Biologie médicale | Usage général |
| Limite de jeton | 4096 | 4096 |
| Vitesse d'inférence | 20ms | 10ms |
| Langues prises en charge | Anglais | Plusieurs langues |
LLaVA vs. GPT-4V : Comparaison des performances et des critères d'évaluation
Les critères de performance sont le véritable test des capacités d'un modèle. Voici comment LLaVA se compare à GPT-4 :
| Critère d'évaluation | Score LLaVA | Score GPT-4 |
|---|---|---|
| SQuAD | 88,5 | 90,2 |
| GLUE | 78,3 | 80,1 |
| Légendage d'images | 70,5 | N/A |
-
Précision : Bien que GPT-4 surpasse légèrement LLaVA dans les tâches basées sur le texte comme SQuAD et GLUE, LLaVA brille dans le légendage d'images, une tâche pour laquelle GPT-4 n'est pas conçu.
-
Vitesse : GPT-4 a une vitesse d'inférence plus rapide de 10ms par rapport à 20ms pour LLaVA. Cependant, la vitesse de LLaVA reste incroyablement rapide et largement suffisante pour les applications en temps réel.
-
Flexibilité : La spécialisation de LLaVA en biologie médicale lui confère un avantage dans les applications médicales, un domaine dans lequel GPT-4 présente des limites.
Comment Installer et Utiliser LLaVA : Guide Étape par Étape
Il est facile de commencer à utiliser LLaVA, mais cela nécessite certaines compétences techniques. Voici un guide étape par étape pour vous aider à démarrer :
Étape 1 : Cloner le Dépôt
Ouvrez votre terminal et exécutez la commande suivante pour cloner le dépôt GitHub de LLaVA :
git clone https://github.com/haotian-liu/LLaVA.gitÉtape 2 : Naviguer vers le Répertoire
Une fois le dépôt cloné, naviguez dans le répertoire :
cd LLaVAÉtape 3 : Installer les Dépendances
LLaVA nécessite plusieurs packages Python pour des performances optimales. Installez-les en exécutant :
pip install -r requirements.txtÉtape 4 : Exécuter des Exemples de Demandes
Maintenant que tout est prêt, vous pouvez exécuter quelques exemples de demandes pour tester les capacités de LLaVA. Ouvrez un script Python et importez le modèle LLaVA :
from LLaVA import LLaVAInitialisez le modèle et exécutez une analyse de texte :
model = LLaVA()
text_output = model.analyze_text("Quelle est la structure moléculaire de l'eau ?")
print(text_output)Pour l'analyse d'images, utilisez :
image_output = model.analyze_image("chemin/vers/image.jpg")
print(image_output)Ces commandes afficheront l'analyse de LLaVA du texte et de l'image donnés. L'analyse du texte fournira une description détaillée de la structure moléculaire de l'eau, tandis que l'analyse de l'image décrira le contenu de l'image.
LLaVA-Med : Le Modèle LLaVA Spécialisé pour les Professionnels de la Santé

LLaVA-Med, la version spécialisée de LLaVA, a été ajustée pour répondre aux besoins des applications biomédicales, faisant de cette solution révolutionnaire un outil indispensable pour les soins de santé et la recherche médicale. Voici un aperçu rapide de ce qui distingue LLaVA-Med :
-
Entraînement spécifique au domaine : LLaVA-Med est entraîné sur de vastes ensembles de données biomédicales, ce qui lui permet de comprendre facilement les terminologies médicales complexes et les concepts.
-
Applications : De l'aide au diagnostic aux annotations de recherche, LLaVA-Med peut révolutionner les soins de santé. Imaginez un outil capable d'analyser rapidement des images médicales, de comparer des données de patients ou d'aider dans la recherche génomique complexe.
-
Potentiel de collaboration : La nature open-source de LLaVA-Med encourage la collaboration au sein de la communauté biomédicale mondiale, conduisant à des améliorations continues et à des percées partagées.
Pour réellement comprendre le pouvoir transformateur de LLaVA-Med, il faut plonger dans ses capacités, explorer son code source et comprendre ses applications potentielles. À mesure que de plus en plus de développeurs et de professionnels de la santé collaborent sur cette plateforme, LLaVA-Med pourrait bien être le précurseur d'une nouvelle ère d'applications d'IA biomédicale.
Vous vous intéressez à la version médicale ajustée de LLaVA ?
En savoir plus sur le fonctionnement de LLaVA Med ici.
Conclusion
Les avancées en matière d'IA et d'apprentissage automatique transforment indéniablement notre paysage technologique, et l'émergence de LLaVA marque une évolution passionnante dans ce domaine. Le modèle LLaVA est bien plus qu'un simple outil dans la boîte à outils de l'IA. Il incarne la convergence du texte et de la vision, ouvrant ainsi de nombreuses applications qui repoussent nos précédentes limites technologiques. Sa nature open-source favorise une approche fondée sur la communauté, permettant à chacun de participer aux avancées technologiques et de ne pas se contenter d'être un simple consommateur passif.
Comparativement, bien que GPT-4 ait pu s'imposer dans le domaine du texte, la capacité de LLaVA à traiter à la fois le texte et les images en fait un choix convaincant pour les développeurs et les chercheurs. Alors que nous continuons à avancer vers l'avenir piloté par l'IA, des outils comme LLaVA joueront un rôle essentiel, comblant l'écart entre ce qui est possible aujourd'hui et les innovations de demain.
Vous souhaitez être au courant des dernières actualités sur LLM ? Consultez le dernier classement LLM !
