LlamaIndex: l'alternative LangChain qui échelonne les LLN

Introduction : Qu'est-ce que LlamaIndex ?
LlamaIndex est un outil d'indexation hautes performances spécifiquement conçu pour augmenter les capacités des modèles linguistiques volumineux (LLN). Ce n'est pas seulement un optimiseur de requêtes ; c'est un cadre complet qui offre des fonctionnalités avancées telles que la synthèse de réponses, la composition et le stockage efficace des données. Si vous traitez avec des requêtes complexes et avez besoin de réponses de haute qualité contextuellement pertinentes, LlamaIndex est la solution idéale.
Dans cet article, nous plongerons techniquement dans LlamaIndex, en explorant ses composants principaux, ses fonctionnalités avancées et comment l'implémenter efficacement dans vos projets. Nous le comparerons également à des outils similaires tels que LangChain pour vous donner une compréhension complète de ses capacités.
Vous voulez connaître les dernières actualités sur les LLN ? Consultez le dernier classement des LLN !
Qu'est-ce que LlamaIndex, en fait ?
LlamaIndex est un outil spécialisé conçu pour améliorer les fonctionnalités des modèles linguistiques volumineux (LLN). Il constitue une solution complète pour des interactions spécifiques avec les LLN, excellant notamment dans les scénarios qui exigent des requêtes précises et des réponses de haute qualité.
Requêtes : Optimisé pour une récupération rapide des données, idéal pour les applications sensibles à la vitesse. Synthèse de réponses : Rationalisée pour produire des réponses concises et contextuellement pertinentes. Composition : Permet de construire des requêtes et des flux de travail complexes en utilisant des composants modulaires et réutilisables.
Maintenant, entrons dans les détails sur LlamaIndex, voulez-vous ?
Qu'est-ce que les index dans LlamaIndex ?
Les index constituent le cœur de LlamaIndex, servant de structures de données qui contiennent les informations à interroger. LlamaIndex propose plusieurs types d'index, chacun optimisé pour des tâches spécifiques.

Les types d'index dans LlamaIndex
- Index du magasin vectoriel : Utilise des algorithmes k-NN et est optimisé pour les données multidimensionnelles.
- Index basé sur les mots-clés : Utilise TF-IDF pour les requêtes textuelles.
- Index hybride : Une combinaison d'index vectoriel et basé sur les mots-clés, offrant une approche équilibrée.
Index du magasin vectoriel dans LlamaIndex
L'index du magasin vectoriel est votre référence pour tout ce qui concerne les données multidimensionnelles. Il est particulièrement utile pour les applications d'apprentissage automatique où vous travaillez avec des points de données complexes.
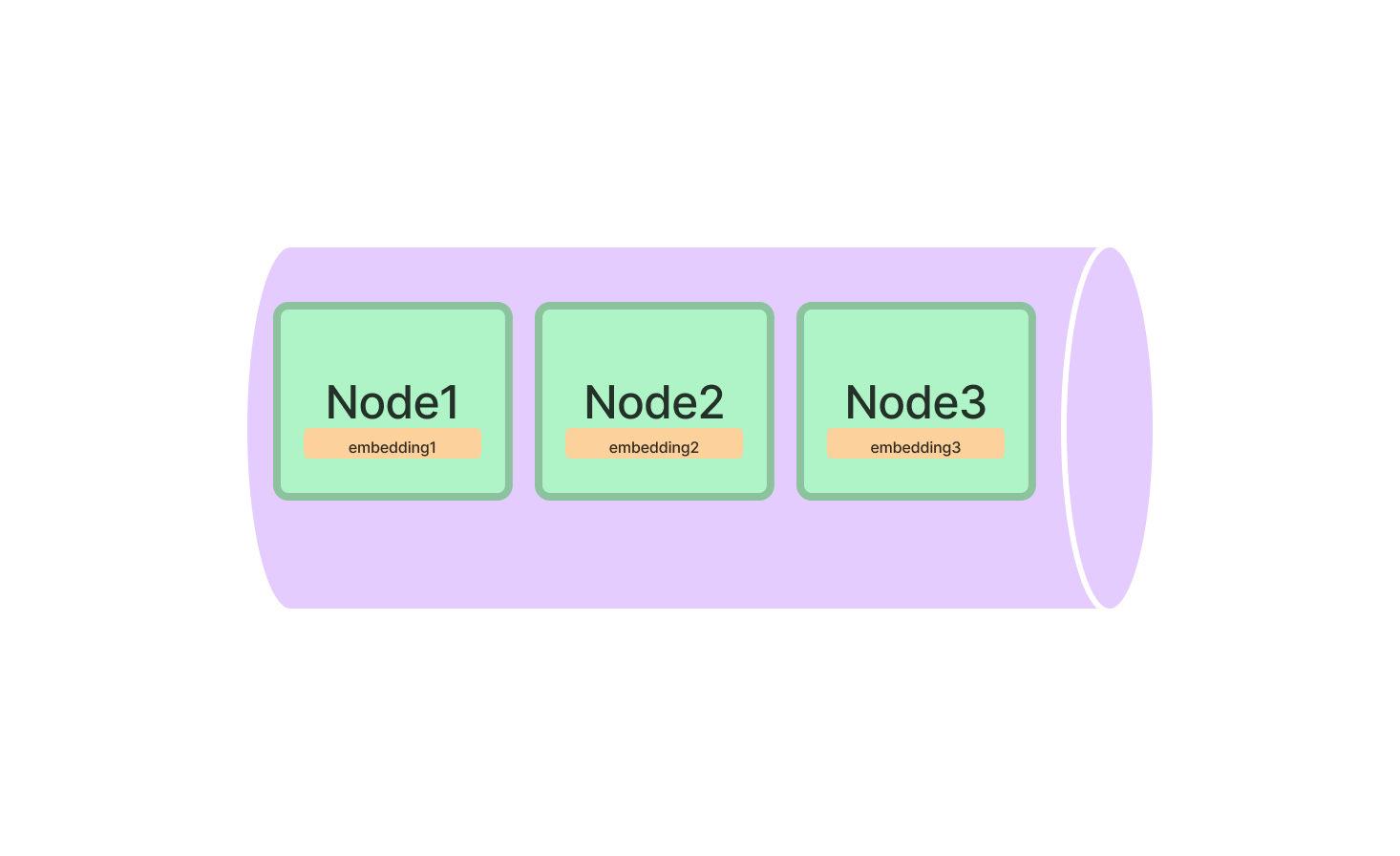
Pour commencer, vous devrez importer la classe VectorStoreIndex du package LlamaIndex. Une fois importée, vous pouvez l'initialiser en spécifiant les dimensions de vos vecteurs.
from llamaindex import VectorStoreIndex
vector_index = VectorStoreIndex(dimensions=300)Cela configure un index du magasin vectoriel avec 300 dimensions, prêt à traiter vos données multidimensionnelles. Vous pouvez maintenant ajouter des vecteurs à l'index et exécuter des requêtes pour trouver les vecteurs les plus similaires.
# Ajout d'un vecteur
vector_index.add_vector(vector_id="vector_1", vector_data=[0.1, 0.2, 0.3, ...])
# Exécution d'une requête
query_result = vector_index.query(vector=[0.1, 0.2, 0.3, ...], top_k=5)Index basé sur les mots-clés dans LlamaIndex
Si vous préférez les requêtes basées sur du texte, l'index basé sur les mots-clés est votre allié. Il utilise l'algorithme TF-IDF pour filtrer les données textuelles, ce qui le rend idéal pour des requêtes en langage naturel.
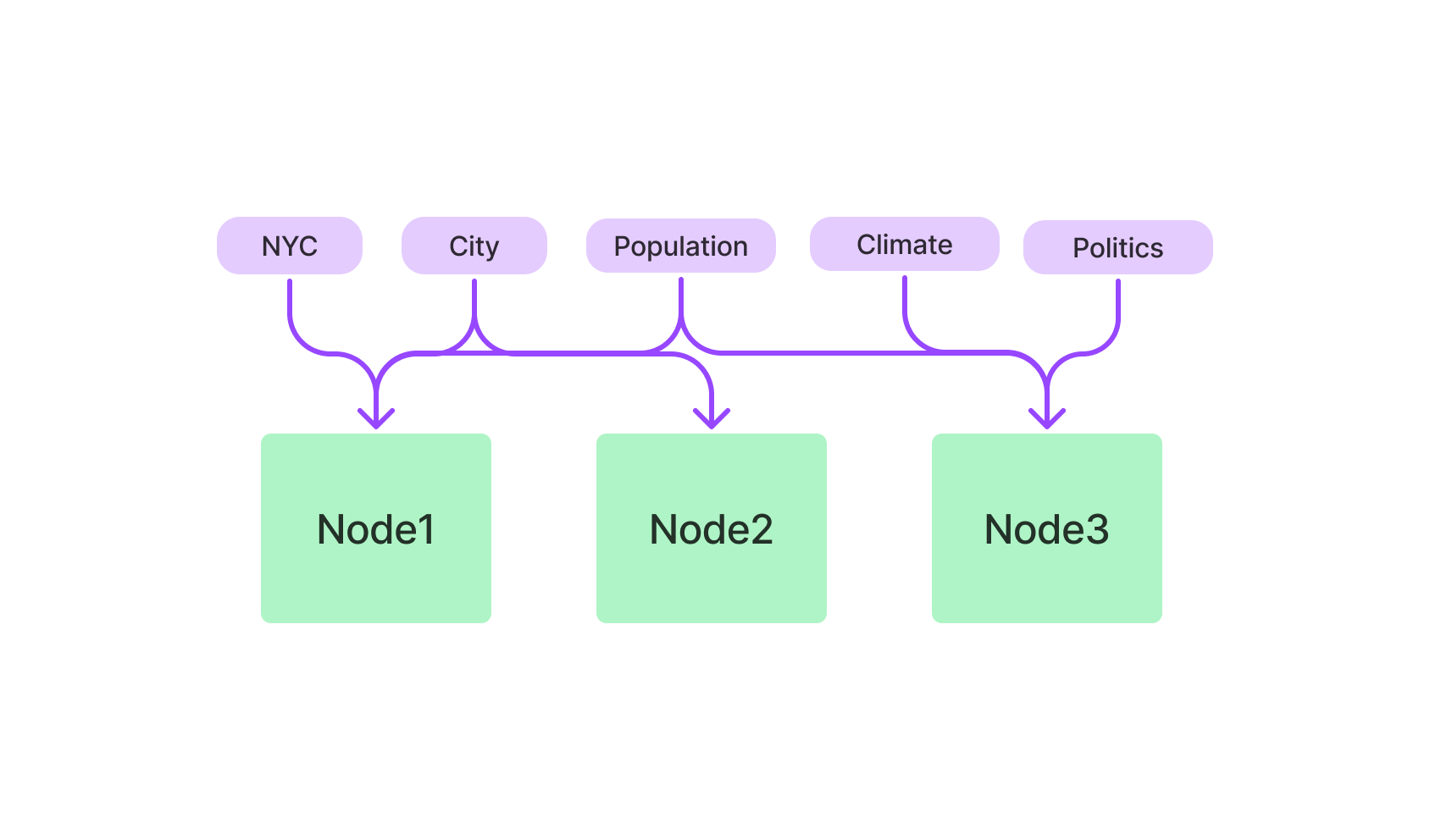
Commencez par importer la classe KeywordBasedIndex du package LlamaIndex. Une fois cela fait, initialiser l'index.
from llamaindex import KeywordBasedIndex
text_index = KeywordBasedIndex()Vous êtes maintenant prêt à ajouter des données textuelles à cet index et à exécuter des requêtes basées sur du texte.
# Ajout de données textuelles
text_index.add_text(text_id="document_1", text_data="Il s'agit d'un document d'exemple.")
# Exécution d'une requête
query_result = text_index.query(text="exemple", top_k=3)Démarrage rapide avec LlamaIndex : Guide étape par étape
Installer et initialiser LlamaIndex n'est que le début. Pour exploiter véritablement ses capacités, vous devez savoir comment l'utiliser efficacement.
Installation de LlamaIndex
Tout d'abord, installez-le sur votre machine. Ouvrez votre terminal et exécutez :
pip install llamaindexOu si vous utilisez conda :
conda install -c conda-forge llamaindexInitialisation de LlamaIndex
Une fois l'installation terminée, vous devrez initialiser LlamaIndex dans votre environnement Python. C'est là que vous préparez le terrain pour toute la magie qui suit.
from llamaindex import LlamaIndex
index = LlamaIndex(index_type="vector_store", dimensions=300)Ici, index_type spécifie le type d'index que vous configurez, et dimensions sert à spécifier la taille de l'index du magasin vectoriel.
Comment interroger l'index du magasin vectoriel de LlamaIndex
Après avoir configuré LlamaIndex avec succès, vous êtes prêt à explorer ses puissantes capacités de requête. L'index du magasin vectoriel est conçu pour gérer des données complexes et multidimensionnelles, ce qui en fait un outil de choix pour l'apprentissage automatique, l'analyse de données et d'autres tâches computationnelles.
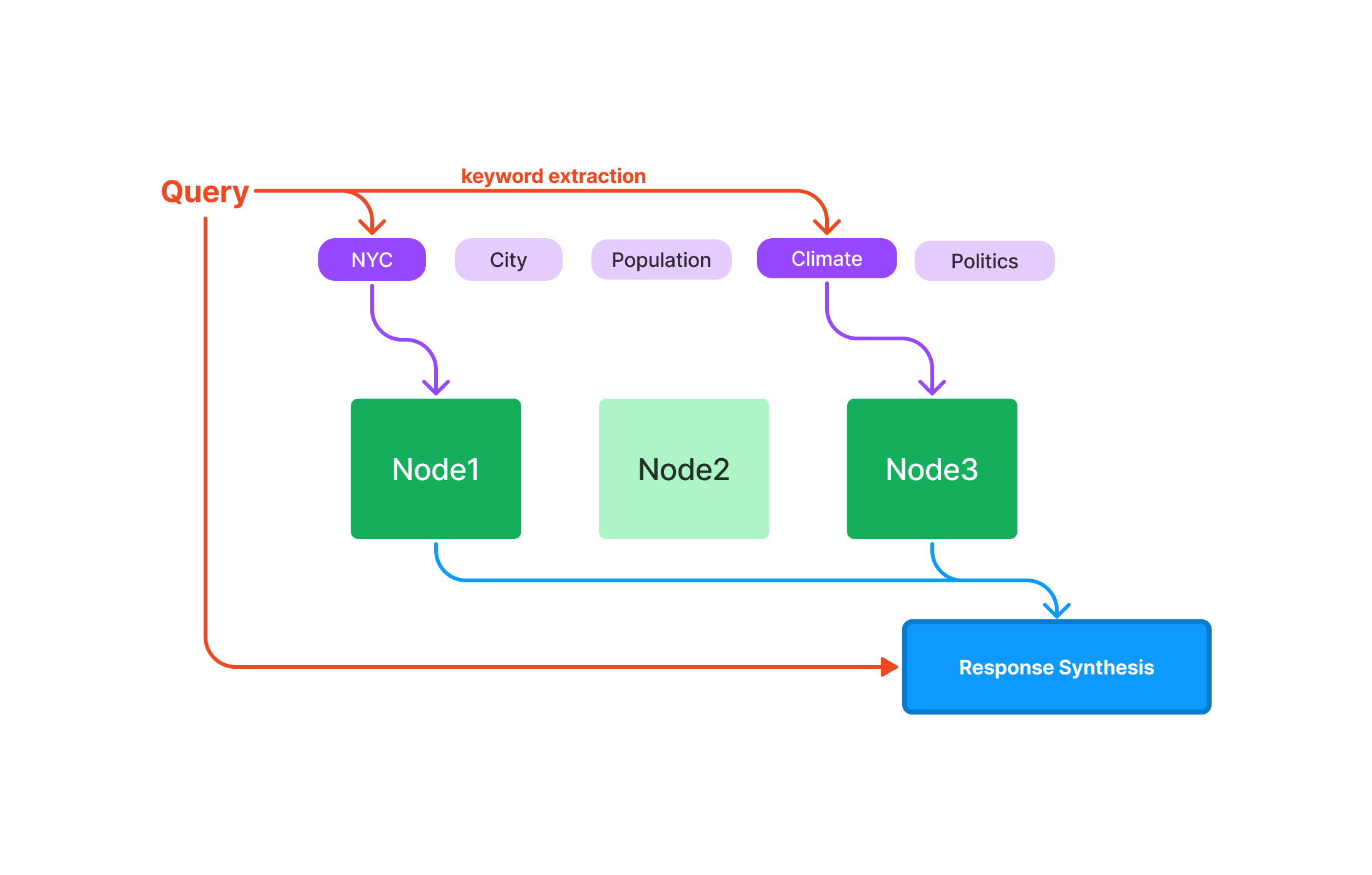
Effectuer votre première requête dans LlamaIndex
Avant de plonger dans le code, il est crucial de comprendre les éléments de base d'une requête dans LlamaIndex :
-
Vecteur de requête: Il s'agit du vecteur pour lequel vous souhaitez trouver des similarités dans votre ensemble de données. Il doit être dans le même espace dimensionnel que les vecteurs que vous avez indexés.
-
Paramètre "top_k": Ce paramètre spécifie le nombre de vecteurs les plus proches de votre vecteur de requête que vous souhaitez récupérer. Le "k" dans "top_k" correspond au nombre de voisins les plus proches qui vous intéressent.
Voici une description détaillée de la façon d'effectuer votre première requête:
-
Initialisez votre index: Assurez-vous que votre index est chargé et prêt pour la recherche.
-
Spécifiez le vecteur de requête: Créez une liste ou un tableau contenant les éléments de votre vecteur de requête.
-
Définissez le paramètre "top_k": Décidez combien de vecteurs les plus proches vous souhaitez récupérer.
-
Exécutez la requête: Utilisez la méthode
querypour effectuer la recherche.
Voici un exemple de code Python pour illustrer ces étapes:
# Initialisez votre index (en supposant qu'il s'appelle 'index')
# ...
# Définissez le vecteur de requête
query_vector = [0.2, 0.4, 0.1, ...]
# Définissez le nombre de vecteurs les plus proches à récupérer
top_k = 5
# Exécutez la requête
query_result = index.query(vector=query_vector, top_k=top_k)Affiner vos requêtes dans LlamaIndex
Pourquoi l'affinage des requêtes est-il important?
L'affinage de vos requêtes vous permet d'adapter le processus de recherche aux exigences spécifiques de votre projet. Que vous traitiez du texte, des images ou tout autre type de données, l'affinage peut améliorer considérablement l'exactitude et l'efficacité de vos requêtes.
Paramètres clés pour l'affinage:
-
Métrique de distance: LlamaIndex vous permet de choisir entre différentes métriques de distance, telles que "euclidean" et "cosine".
-
Distance euclidienne: Il s'agit de la distance "ordinaire" en ligne droite entre deux points dans un espace euclidien. Utilisez cette métrique lorsque la magnitude des vecteurs est importante.
-
Similarité cosinus: Cette métrique mesure le cosinus de l'angle entre deux vecteurs. Utilisez cette métrique lorsque vous êtes plus intéressé par la direction des vecteurs que par leur magnitude.
-
-
Taille du lot: Si vous traitez un ensemble de données volumineux ou avez besoin d'effectuer plusieurs requêtes, définir une taille de lot peut accélérer le processus en interrogeant plusieurs vecteurs à la fois.
Guide étape par étape pour l'affinage:
Voici comment affiner votre requête:
-
Choisissez la métrique de distance: Choisissez entre "euclidean" et "cosine" en fonction de vos besoins spécifiques.
-
Définissez la taille du lot: Déterminez le nombre de vecteurs que vous souhaitez traiter dans un seul lot.
-
Exécutez la requête affinée: Utilisez à nouveau la méthode
query, mais cette fois incluez les paramètres supplémentaires.
Voici un exemple de code Python pour illustrer ces étapes:
# Définissez le vecteur de requête
query_vector = [0.2, 0.4, 0.1, ...]
# Définissez le nombre de vecteurs les plus proches à récupérer
top_k = 5
# Choisissez la métrique de distance
distance_metric = 'euclidean'
# Définissez la taille du lot pour les requêtes multiples
batch_size = 100
# Exécutez la requête affinée
query_result = index.query(vector=query_vector, top_k=top_k, metric=distance_metric, batch_size=batch_size)En maîtrisant ces techniques d'affinage, vous pouvez rendre vos requêtes dans LlamaIndex plus ciblées et efficaces, et ainsi extraire le maximum de valeur de vos données multidimensionnelles.
Que pouvez-vous construire avec LlamaIndex?
Maintenant que vous maitrisez les bases, que pouvez-vous réellement construire avec LlamaIndex? Les possibilités sont vastes, surtout si vous considérez sa compatibilité avec les Modèles de Langage de Grande Taille (LLM).
LlamaIndex pour les moteurs de recherche avancés
L'une des utilisations les plus attrayantes de LlamaIndex est dans le domaine des moteurs de recherche avancés. Imaginez un moteur de recherche qui non seulement récupère des documents pertinents, mais comprend également le contexte de votre requête. Avec LlamaIndex, vous pouvez créer exactement cela.
Voici un exemple rapide pour démontrer comment vous pourriez créer un moteur de recherche de base en utilisant l'index basé sur les mots-clés de LlamaIndex.
# Initialisez l'index basé sur les mots-clés
from llamaindex import KeywordBasedIndex
search_index = KeywordBasedIndex()
# Ajoutez quelques documents
search_index.add_text("doc1", "Les lamas sont géniaux.")
search_index.add_text("doc2", "J'adore la programmation.")
# Exécutez une requête
results = search_index.query("Lamas", top_k=2)LlamaIndex pour les systèmes de recommandation
Une autre application fascinante est la création de systèmes de recommandation. Que ce soit pour suggérer des produits similaires, des articles ou même des chansons, l'index Vector Store de LlamaIndex peut changer la donne.
Voici comment vous pourriez configurer un système de recommandation de base:
# Initialisez l'index Vector Store
from llamaindex import VectorStoreIndex
rec_index = VectorStoreIndex(dimensions=50)
# Ajoutez quelques vecteurs de produits
rec_index.add_vector("product1", [0.1, 0.2, 0.3, ...])
rec_index.add_vector("product2", [0.4, 0.5, 0.6, ...])
# Exécutez une requête pour trouver des produits similaires
similar_products = rec_index.query(vector=[0.1, 0.2, 0.3, ...], top_k=5)LlamaIndex vs LangChain
Lorsqu'il s'agit de développer des applications basées sur des Modèles de Langage de Grande Taille (LLMs), le choix du framework peut avoir un impact significatif sur le succès du projet. Deux frameworks qui ont suscité l'attention dans cet espace sont LlamaIndex et LangChain. Chacun a ses caractéristiques et avantages uniques, mais ils répondent à des besoins différents et sont optimisés pour des tâches spécifiques. Dans cette section, nous examinerons les détails techniques et fournirons un exemple de code pour vous aider à comprendre les principales différences entre ces deux frameworks, notamment dans le contexte du Développement de Génération Assistée par Récupération (RAG) pour le développement de chatbots.
Fonctionnalités principales et capacités techniques
LangChain
-
Framework polyvalent: LangChain est conçu pour être un outil polyvalent pour une large gamme d'applications. Il permet non seulement le chargement, le traitement et l'indexation des données, mais fournit également des fonctionnalités d'interaction avec les LLMs.
Exemple de code:
const res = await llm.call("Raconte-moi une blague"); -
Flexibilité : L'une des caractéristiques marquantes de LangChain est sa flexibilité. Elle permet aux utilisateurs de personnaliser de manière approfondie le comportement de leurs applications.
-
API de haut niveau : LangChain abstrait la plupart des complexités liées à l'utilisation des LLM (Large Language Models), offrant des API de haut niveau simples et faciles à utiliser.
Exemple de code :
const chain = new SqlDatabaseChain({ llm: new OpenAI({ temperature: 0 }), database: db, sqlOutputKey: "sql", }); const res = await chain.call({ query: "Combien de pistes y a-t-il ?" }); -
Chaînes clés en main : LangChain est préchargé avec des chaînes clés en main telles que
SqlDatabaseChain, qui peuvent être personnalisées ou utilisées comme base pour construire de nouvelles applications.
LlamaIndex
-
Spécialisé dans la recherche et la récupération : LlamaIndex est conçu pour la création d'applications de recherche et de récupération. Il offre une interface simple pour interroger les LLM et récupérer des documents pertinents.
Exemple de code :
query_engine = index.as_query_engine() response = query_engine.query("Stackoverflow est génial.") -
Efficacité : LlamaIndex est optimisé pour la performance, ce qui en fait un meilleur choix pour les applications ayant besoin de traiter rapidement de grandes quantités de données.
-
Connecteurs de données : LlamaIndex peut ingérer des données provenant de différentes sources, notamment des API, des fichiers PDF, des bases de données SQL, etc., permettant une intégration transparente dans les applications LLM.
-
Indexation optimisée : L'une des principales caractéristiques de LlamaIndex est sa capacité à structurer les données ingérées sous forme de représentations intermédiaires optimisées pour des requêtes rapides et efficaces.
Quand utiliser quel cadre ?
-
Applications polyvalentes : Si vous construisez un chatbot qui doit être flexible et polyvalent, LangChain est le choix idéal. Sa nature polyvalente et ses API de haut niveau le rendent adapté à un large éventail d'applications.
-
Mise au point sur la recherche et la récupération : Si la fonction principale de votre chatbot est la recherche et la récupération d'informations, LlamaIndex est le meilleur choix. Ses capacités d'indexation et de récupération spécialisées le rendent hautement efficace pour de telles tâches.
-
Combinaison des deux : Dans certains scénarios, il peut être bénéfique d'utiliser les deux frameworks. LangChain peut gérer les fonctionnalités générales et les interactions avec les LLM, tandis que LlamaIndex peut gérer les tâches spécialisées de recherche et de récupération. Cette combinaison peut offrir une approche équilibrée, en exploitant la flexibilité de LangChain et l'efficacité de LlamaIndex.
Exemple de code pour une utilisation combinée :
# LangChain pour les fonctionnalités générales res = llm.call("Raconte-moi une blague") # LlamaIndex pour la recherche spécialisée query_engine = index.as_query_engine() response = query_engine.query("Parle-moi du changement climatique.")
Alors, lequel devrais-je choisir ? LangChain ou LlamaIndex ?
Le choix entre LangChain et LlamaIndex, ou la décision d'utiliser les deux, doit être guidé par les exigences spécifiques de votre projet. LangChain offre une plus large gamme de capacités et est idéal pour les applications polyvalentes. En revanche, LlamaIndex est spécialisé dans la recherche et la récupération efficace, ce qui le rend adapté aux tâches intensives en données. En comprenant les nuances techniques et les capacités de chaque framework, vous pouvez prendre une décision éclairée qui correspond le mieux à vos besoins de développement de chatbot.
Conclusion
Maintenant, vous devriez avoir une compréhension solide de ce qu'est LlamaIndex. De ses index spécialisés à sa large gamme d'applications et son avantage par rapport à d'autres outils tels que LangChain, LlamaIndex s'avère un outil indispensable pour quiconque travaille avec les modèles de langage volumineux. Que vous construisiez un moteur de recherche, un système de recommandation ou toute autre application nécessitant une interrogation et une récupération de données efficaces, LlamaIndex est là pour vous.
FAQ sur LlamaIndex
Répondons à certaines des questions les plus courantes concernant LlamaIndex.
À quoi sert LlamaIndex ?
LlamaIndex est principalement utilisé comme une couche intermédiaire entre les utilisateurs et les modèles de langage volumineux (LLM). Il excelle dans l'exécution de requêtes, la synthèse des réponses et l'intégration des données, ce qui en fait un outil idéal pour une variété d'applications telles que les moteurs de recherche et les systèmes de recommandation.
L'utilisation de LlamaIndex est-elle gratuite ?
Oui, LlamaIndex est un outil open source, ce qui le rend gratuit à utiliser. Vous pouvez trouver son code source sur GitHub et contribuer à son développement.
Quelle est la différence entre GPT Index et LlamaIndex ?
GPT Index est conçu pour les requêtes basées sur du texte et est généralement utilisé avec des modèles GPT (Generative Pre-trained Transformer). LlamaIndex, en revanche, est plus polyvalent et peut gérer à la fois des requêtes basées sur du texte et des requêtes basées sur des vecteurs, ce qui le rend compatible avec une plus large gamme de modèles de langage volumineux.
Quelle est l'architecture de LlamaIndex ?
LlamaIndex est construit sur une architecture modulaire qui comprend différents types d'index tels que l'indexation par vecteur et l'indexation basée sur les mots clés. Il est principalement écrit en Python et prend en charge plusieurs algorithmes tels que k-NN, TF-IDF et les embeddings BERT.
Vous voulez connaître les dernières actualités sur les modèles de langage volumineux ? Consultez le dernier classement des LLM !
