L'ère des modèles linguistiques larges à 1 bit : Microsoft présente BitNet b1.58
Published on
Introduction
Les chercheurs de Microsoft ont introduit une nouvelle variante révolutionnaire de modèle linguistique large (LLM) à 1 bit appelée BitNet b1.58, où chaque paramètre du modèle est ternaire, prenant les valeurs 1. Ce LLM à 1.58 bit correspond aux performances des LLM à précision complète (FP16 ou BF16) avec la même taille de modèle et le même nombre de jetons d'entraînement, tout en étant nettement plus rentable en termes de latence, d'utilisation de la mémoire, de débit et de consommation d'énergie. BitNet b1.58 représente une avancée majeure dans la création de LLM à la fois performants et hautement efficaces.

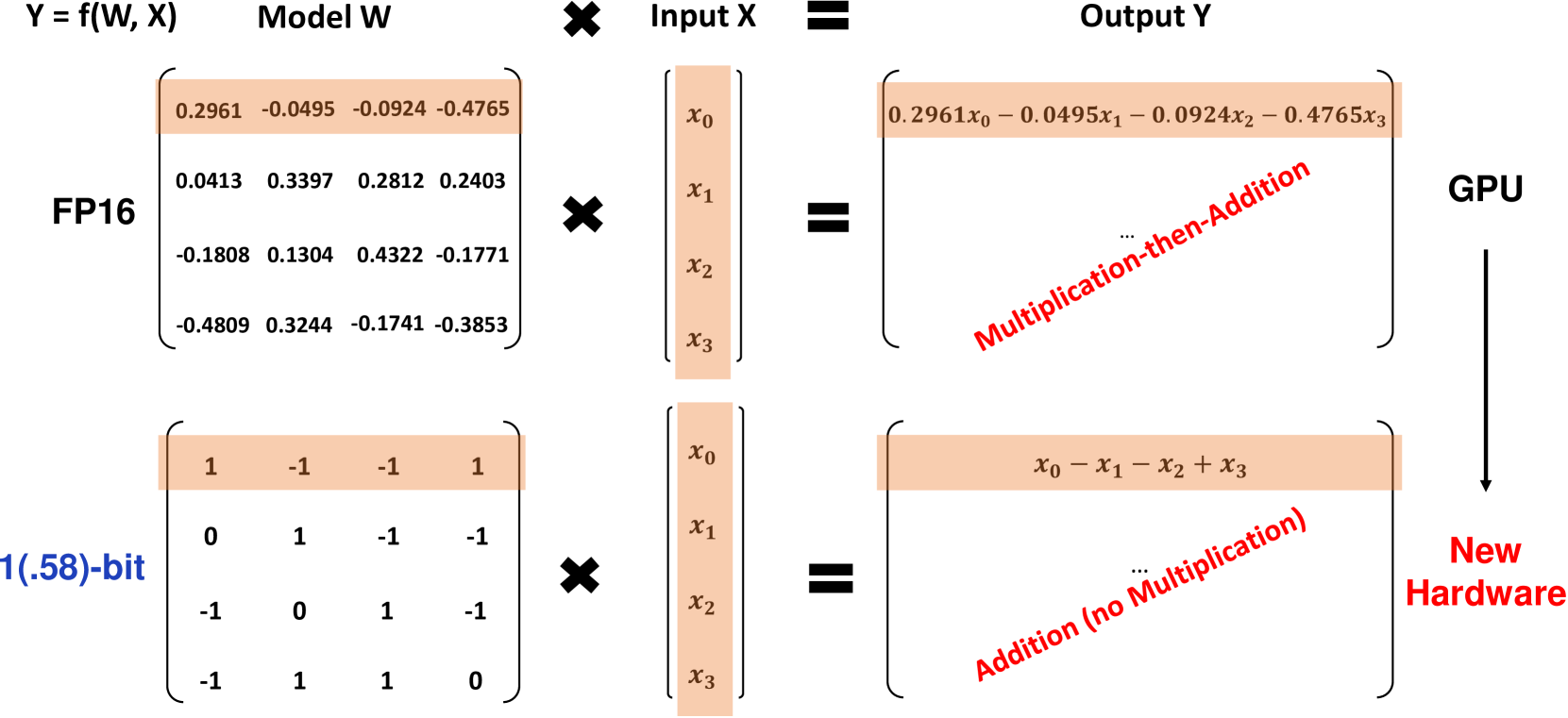
Qu'est-ce que BitNet b1.58 ?
BitNet b1.58 est basé sur l'architecture BitNet originale, un modèle Transformer qui remplace les couches standard nn.Linear par des couches BitLinear. Il est entraîné à partir de zéro avec des poids de 1.58 bit et des activations de 8 bit. Par rapport au BitNet à 1 bit d'origine, b1.58 introduit quelques modifications clés :
-
Il utilise une fonction de quantification de absmean pour contraindre les poids à 1. Cela arrondit chaque poids à l'entier le plus proche parmi ces valeurs après mise à l'échelle par la valeur absolue moyenne.
-
Pour les activations, il les met à l'échelle dans la plage [-sa, sa] par jeton, ce qui simplifie l'implémentation par rapport au BitNet d'origine.
-
Il adopte des composants de l'architecture LLaMA open-source populaire, notamment RMSNorm, les activations SwiGLU, les embeddings rotatifs et supprime les biais. Cela permet une intégration facile avec les logiciels LLM existants.
L'ajout de la valeur 0 aux poids permet la filtration des caractéristiques, renforçant ainsi les capacités de modélisation par rapport aux modèles à 1 bit purs. Les expériences montrent que BitNet b1.58 correspond aux valeurs de base FP16 en termes de perplexité et de performances de fin de tâche pour une taille de modèle de 3B.
Résultats de performance
Les chercheurs ont comparé BitNet b1.58 à une ligne de base LLM FP16 LLaMA reproduite pour différentes tailles de modèle allant de 700M à 70B de paramètres. Les deux ont été pré-entraînés sur le même ensemble de données RedPajama avec 100B de jetons et évalués sur la perplexité et un éventail de tâches linguistiques hors contexte.
Les résultats clés sont les suivants :
-
BitNet b1.58 correspond à la perplexité de la ligne de base FP16 LLaMA pour une taille de 3B, tout en étant 2,71 fois plus rapide et en utilisant 3,55 fois moins de mémoire GPU.
-
Un BitNet b1.58 de 3,9B surpasse le LLaMA de 3B en termes de perplexité et de performances de fin de tâche avec une latence et des coûts mémoire inférieurs.
-
Dans le cadre des tâches linguistiques hors contexte, l'écart de performances entre BitNet b1.58 et LLaMA se réduit à mesure que la taille du modèle augmente, BitNet correspondant à LLaMA pour une taille de 3B.
-
En s'étendant jusqu'à 70B, BitNet b1.58 atteint une accélération de 4,1 fois par rapport à la base FP16. Les économies de mémoire augmentent également avec l'échelle.
-
BitNet b1.58 utilise 71,4 fois moins d'énergie pour les multiplications matricielles. L'efficacité énergétique de bout en bout augmente avec la taille du modèle.
-
Sur deux GPU A100 de 80 Go, un BitNet b1.58 de 70B permet de prendre en charge des tailles de lots 11 fois supérieures à celles de LLaMA, ce qui permet un débit 8,9 fois supérieur.
Les résultats démontrent que BitNet b1.58 offre une amélioration de Pareto par rapport aux modèles de pointe FP16 LLM - il est plus efficace en termes de latence, de mémoire et d'énergie tout en correspondant à la perplexité et aux performances de fin de tâche à une échelle suffisante. Par exemple, un BitNet b1.58 de 13B est plus efficace qu'un LLM FP16 de 3B, un BitNet de 30B plus efficace qu'un FP16 de 7B et un BitNet de 70B plus efficace qu'un modèle FP16 de 13B.
Lorsqu'il est entraîné sur 2T de jetons selon la recette StableLM-3B, BitNet b1.58 a surpassé StableLM-3B hors contexte sur toutes les tâches évaluées, montrant une forte généralisation.
Les tableaux ci-dessous fournissent des données plus détaillées sur les comparaisons de performances entre BitNet b1.58 et la ligne de base FP16 LLaMA :
| Modèles | Taille | Mémoire (Go) | Latence (ms) | PPL |
|---|---|---|---|---|
| LLaMA LLM | 700M | 2,08 (1,00x) | 1,18 (1,00x) | 12,33 |
| BitNet b1.58 | 700M | 0,80 (2,60x) | 0,96 (1,23x) | 12,87 |
| LLaMA LLM | 1,3B | 3,34 (1,00x) | 1,62 (1,00x) | 11,25 |
| BitNet b1.58 | 1,3B | 1,14 (2,93x) | 0,97 (1,67x) | 11,29 |
| LLaMA LLM | 3B | 7,89 (1,00x) | 5,07 (1,00x) | 10,04 |
| BitNet b1.58 | 3B | 2,22 (3,55x) | 1,87 (2,71x) | 9,91 |
| BitNet b1.58 | 3,9B | 2,38 (3,32x) | 2,11 (2,40x) | 9,62 |
Tableau 1 : Comparaison de la perplexité et des coûts de BitNet b1.58 et LLaMA LLM.
| Modèles | Taille | ARCe | ARCc | HS | BQ | OQ | PQ | WGe | Moy. |
|---|---|---|---|---|---|---|---|---|---|
| LLaMA LLM | 700M | 54,7 | 23,0 | 37,0 | 60,0 | 20,2 | 68,9 | 54,8 | 45,5 |
| BitNet b1.58 | 700M | 51,8 | 21,4 | 35,1 | 58,2 | 20,0 | 68,1 | 55,2 | 44,3 |
| LLaMA LLM | 1,3B | 56,9 | 23,5 | 38,5 | 59,1 | 21,6 | 70,0 | 53,9 | 46,2 |
| BitNet b1.58 | 1,3B | 54,9 | 24,2 | 37,7 | 56,7 | 19,6 | 68,8 | 55,8 | 45,4 |
| LLaMA LLM | 3B | 62,1 | 25,6 | 43,3 | 61,8 | 24,6 | 72,1 | 58,2 | 49,7 |
| BitNet b1.58 | 3B | 61,4 | 28,3 | 42,9 | 61,5 | 26,6 | 71,5 | 59,3 | 50,2 |
| BitNet b1.58 | 3,9B | 64,2 | 28,7 | 44,2 | 63,5 | 24,2 | 73,2 | 60,5 | 51,2 |
Tableau 2 : Précision hors contexte de BitNet b1.58 et LLaMA LLM pour les tâches finales.
Les graphiques suivants montrent la latence de décodage et la consommation de mémoire de BitNet b1.58 pour différentes tailles de modèle (Figure 1). L'accélération augmente avec la taille du modèle, atteignant 4,1 fois pour 70B de paramètres par rapport à la base FP16. Les économies de mémoire augmentent également avec l'échelle.
Se référer à la légende Se référer à la légende Figure 1 : Latence de décodage (gauche) et consommation de mémoire (droite) de BitNet b1.58 pour différentes tailles de modèle. En termes d'efficacité énergétique, BitNet b1.58 utilise 71,4 fois moins d'énergie pour les multiplications de matrices par rapport aux LLM FP16. Le coût énergétique de bout en bout pour différentes tailles de modèle est illustré dans la Figure 2, montrant que BitNet b1.58 devient de plus en plus efficace aux grandes échelles.
Référence à la légende Référence à la légende Figure 2 : Consommation énergétique de BitNet b1.58 comparé à LLaMA LLM. Gauche : Composants de l'énergie des opérations arithmétiques. Droite : Coût énergétique de bout en bout pour différentes tailles de modèle.
Le débit est un autre avantage clé de BitNet b1.58. Sur deux GPU A100 de 80 Go, un BitNet b1.58 de 70B prend en charge des lots de 11x plus grande taille qu'un LLaMA LLM de 70B, ce qui se traduit par un débit 8,9 fois plus élevé, comme indiqué dans le Tableau 3.
| Modèles | Taille | Taille maximale du lot | Débit (tokens/s) |
|---|---|---|---|
| LLaMA LLM | 70B | 16 (1,0x) | 333 (1,0x) |
| BitNet b1.58 | 70B | 176 (11,0x) | 2977 (8,9x) |
Tableau 3 : Comparaison du débit entre BitNet b1.58 de 70B et LLaMA LLM.
Implications et orientations futures
L'architecture et les résultats de BitNet b1.58 ont des implications significatives pour l'avenir des LLM :
-
Elle établit une nouvelle frontière de Pareto et une loi d'échelle pour les LLM à la fois performants et hautement efficaces. Les LLM de 1,58 bit peuvent correspondre aux références en FP16 à des coûts d'inférence nettement inférieurs.
-
La réduction drastique de la mémoire permet d'exécuter des LLM beaucoup plus grands sur une quantité de matériel donnée. Cela est particulièrement important pour les architectures gourmandes en mémoire telles que le "mixture-of-experts".
-
Les activations sur 8 bits permettent de doubler la longueur du contexte possible avec un budget mémoire donné par rapport aux activations sur 16 bits. Une compression supplémentaire à 4 bits ou moins est possible à l'avenir.
-
L'efficacité exceptionnelle des LLM de 1,58 bits sur les dispositifs CPU ouvre la voie au déploiement de LLM puissants sur des périphériques embarqués/mobiles, où les CPU sont le processeur principal.
-
Le nouveau paradigme de calcul sur faible nombre de bits de BitNet b1.58 incite à concevoir des accélérateurs IA sur mesure et des systèmes optimisés spécifiquement pour les LLM à 1 bit afin d'exploiter pleinement leur potentiel.
Microsoft voit les LLM à 1 bit comme un chemin très prometteur pour rendre les LLM nettement plus rentables tout en préservant leurs capacités. Ils envisagent une ère où les modèles à 1 bit alimentent des applications allant des centres de données à la périphérie. Cependant, pour atteindre cet objectif, il sera nécessaire de co-concevoir les architectures de modèle, le matériel et les systèmes logiciels afin d'exploiter pleinement les propriétés uniques de ces modèles. BitNet b1.58 établit un point de départ passionnant pour cette nouvelle ère des LLM.
Conclusion
BitNet b1.58 représente une percée majeure dans la poussée des grands modèles de langage à la limite de la quantification tout en préservant les performances. En utilisant des poids ternaires 1 et des activations sur 8 bits, il se compare aux LLM en FP16 en termes de perplexité et de performances finales tout en utilisant beaucoup moins de mémoire, en réduisant la latence et la consommation d'énergie.
L'architecture à 1,58 bit établit une nouvelle frontière de Pareto pour les LLM, où des modèles plus grands peuvent être exécutés à une fraction du coût. Cela ouvre de nouvelles possibilités telles que le soutien natif de contexte plus long, le déploiement de puissants LLM sur des appareils embarqués et incite à la conception de matériel sur mesure pour l'IA sur faible nombre de bits.
Le travail de Microsoft démontre que les LLM quantifiés de manière agressive sont non seulement viables, mais établissent en fait une loi d'échelle supérieure par rapport aux modèles FP16. Avec une co-conception plus poussée des architectures, du matériel et des logiciels, les LLM à 1 bit ont le potentiel de propulser la prochaine grande avancée dans les capacités d'IA rentables, du cloud à la périphérie. BitNet b1.58 constitue un point de départ impressionnant pour cette nouvelle ère passionnante des grands modèles de langage ultra-efficients.