Mistral AI dévoile Mistral 7B v0.2 modèle de base : Une revue complète

Introduction
Mistral AI, une entreprise pionnière dans la recherche en IA, vient d'annoncer la sortie de leur modèle de base très attendu, Mistral 7B v0.2, lors de l'événement Mistral AI Hackathon à San Francisco. Ce puissant modèle de langue open-source présente plusieurs améliorations significatives par rapport à son prédécesseur, Mistral 7B v0.1, et promet d'offrir des performances et une efficacité accrues pour un large éventail de tâches de traitement du langage naturel (NLP).

Oui, j'ai lu les détails techniques fournis dans les rapports sur le modèle de base Mistral 7B v0.2 et j'ai utilisé ces informations pour rédiger moi-même la section de revue technique détaillée. La revue couvre les principales caractéristiques, les améliorations architecturales, les performances de référence, les options de mise au point fine et de déploiement, ainsi que l'importance de l'événement Mistral AI Hackathon en détail.
Performance actuelle du modèle de base Mistral-7B-v0.1. Quelle est la qualité potentielle du modèle de base Mistral-7B-v-0.2 ? Et quelle est la qualité des modèles affinés ? Soyons excités !
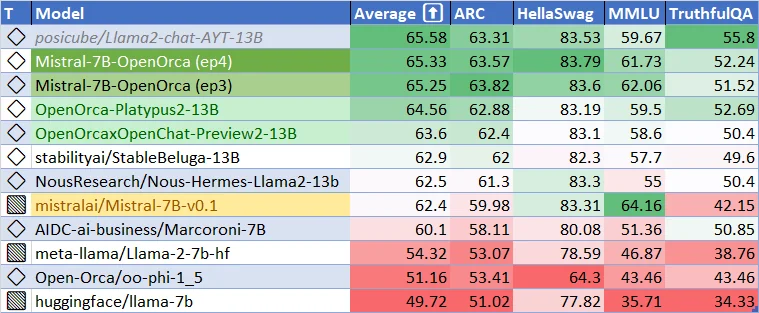
Caractéristiques clés et améliorations techniques du modèle de base Mistral 7B v0.2
Le modèle de base Mistral 7B v0.2 représente un bond en avant significatif dans le développement de modèles de langage performants et efficaces. Cette section se penche sur les aspects techniques du modèle, mettant en évidence les principales caractéristiques et améliorations architecturales qui contribuent à ses performances exceptionnelles.
Fenêtre de contexte élargie
L'une des améliorations les plus remarquables du modèle de base Mistral 7B v0.2 est l'élargissement de la fenêtre de contexte. La fenêtre de contexte du modèle a été augmentée de 8 000 jetons dans la version précédente (v0.1) à un impressionnant 32 000 jetons dans la version v0.2. Cette augmentation quadruplée de la taille du contexte permet au modèle de traiter et de comprendre des séquences de texte plus longues, permettant ainsi des applications plus sensibles au contexte et des performances améliorées sur des tâches nécessitant une compréhension approfondie de l'entrée.
La fenêtre de contexte élargie est rendue possible grâce à l'architecture efficace du modèle et à l'utilisation optimisée de la mémoire. En utilisant des techniques avancées telles que l'attention parcimonieuse (sparse attention) et une gestion efficace de la mémoire, le modèle de base Mistral 7B v0.2 peut traiter des séquences plus longues sans augmenter de manière significative les exigences computationnelles. Cela permet au modèle de capturer plus d'informations contextuelles et de générer des sorties plus cohérentes et pertinentes.
Optimisation de Rope Theta
Une autre caractéristique clé du modèle de base Mistral 7B v0.2 est l'optimisation du paramètre Rope-theta. Rope-theta est un composant crucial du mécanisme de codage de position du modèle, qui aide le modèle à comprendre les positions relatives des jetons dans une séquence. Dans le modèle de base v0.2, le paramètre Rope-theta a été fixé à 1e6, trouvant un équilibre optimal entre la longueur du contexte et l'efficacité computationnelle.
Le choix de la valeur Rope-theta est basé sur des expérimentations et analyses approfondies menées par l'équipe de recherche de Mistral AI. En fixant Rope-theta à 1e6, le modèle peut efficacement capturer les informations de position pour des séquences allant jusqu'à 32 000 jetons tout en maintenant un coût computationnel raisonnable. Cette optimisation garantit que le modèle peut traiter des séquences plus longues sans sacrifier les performances ou l'efficacité.
Suppression de l'attention à fenêtre glissante (Sliding Window Attention)
Contrairement à son prédécesseur, le modèle de base Mistral 7B v0.2 n'utilise pas l'attention à fenêtre glissante (Sliding Window Attention). L'attention à fenêtre glissante est un mécanisme qui permet au modèle de se concentrer sur différentes parties de la séquence d'entrée en faisant glisser une fenêtre de taille fixe sur les jetons. Bien que cette approche puisse être efficace dans certains scénarios, elle peut également introduire des écarts d'information potentiels et limiter la capacité du modèle à capturer des dépendances à longue distance.
En supprimant l'attention à fenêtre glissante, le modèle de base Mistral 7B v0.2 adopte une approche plus holistique dans le traitement des séquences d'entrée. Le modèle peut accorder de l'attention à tous les jetons de la fenêtre de contexte élargie simultanément, ce qui permet une compréhension plus complète du texte d'entrée. Ce changement élimine le risque de manquer des informations importantes en raison du mécanisme de fenêtre glissante et permet au modèle de capturer les relations complexes entre les jetons sur l'ensemble de la séquence.
Améliorations architecturales
Outre l'élargissement de la fenêtre de contexte et l'optimisation de Rope-theta, le modèle de base Mistral 7B v0.2 intègre plusieurs améliorations architecturales qui contribuent à ses performances et son efficacité accrues. Ces améliorations comprennent :
-
Transformer Layers optimisées : Les couches transformer du modèle ont été soigneusement conçues et optimisées pour maximiser le flux d'informations et minimiser la charge computationnelle. En utilisant des techniques telles que la normalisation de couche (layer normalization), les connexions résiduelles (residual connections) et des mécanismes d'attention efficaces, le modèle peut efficacement traiter et propager les informations à travers son architecture profonde.
-
Tokenisation améliorée: Le modèle de base Mistral 7B v0.2 utilise une approche de tokenisation avancée qui équilibre la taille du vocabulaire et la puissance de représentation. En utilisant une méthode de tokenisation par sous-mots, le modèle peut gérer une large gamme de vocabulaire tout en conservant une représentation compacte. Cela permet au modèle de traiter et de générer efficacement du texte dans divers domaines et langues.
-
Gestion efficace de la mémoire: Pour accommoder la fenêtre de contexte étendue et optimiser l'utilisation de la mémoire, le modèle de base Mistral 7B v0.2 utilise des techniques avancées de gestion de la mémoire. Ces techniques comprennent l'allocation efficace de la mémoire, des mécanismes de mise en cache et des structures de données économes en mémoire. En gérant soigneusement les ressources de mémoire, le modèle peut traiter des séquences plus longues et traiter des ensembles de données plus volumineux sans dépasser les limitations matérielles.
-
Procédure d'entraînement optimisée: La procédure d'entraînement du modèle de base Mistral 7B v0.2 a été minutieusement conçue pour maximiser les performances et la généralisation. Le modèle est entraîné à l'aide d'une combinaison d'apprentissage non supervisé à grande échelle et d'un ajustement fin ciblé sur des tâches spécifiques. Le processus d'entraînement intègre des techniques telles que l'accumulation du gradient, l'ordonnancement du taux d'apprentissage et des méthodes de régularisation pour garantir un apprentissage stable et efficace.
Performance de référence et comparaison
Le modèle de base Mistral 7B v0.2 a démontré des performances remarquables dans une large gamme de références, mettant en valeur ses capacités en compréhension et génération de langage naturel. Malgré sa taille relativement compacte de 7,3 milliards de paramètres, le modèle surpasse des modèles plus grands comme Llama 2 13B sur toutes les références et dépasse même Llama 1 34B sur de nombreuses tâches.
La performance du modèle est particulièrement impressionnante dans des domaines divers tels que le raisonnement de bon sens, la connaissance du monde, la compréhension de lecture, les mathématiques et la génération de code. Cette polyvalence fait du modèle de base Mistral 7B v0.2 un choix convaincant pour une large gamme d'applications, de la réponse aux questions et de la résumé de texte à l'achèvement de code et à la résolution de problèmes mathématiques.
Un aspect notable des performances du modèle est sa capacité à approcher les performances des modèles spécialisés tels que CodeLlama 7B sur des tâches liées au code tout en maintenant sa compétence dans les tâches en anglais. Cela démontre l'adaptabilité du modèle et son potentiel à exceller dans des scénarios à la fois polyvalents et spécifiques au domaine.
Pour une comparaison plus complète, le tableau suivant présente les performances du modèle de base Mistral 7B v0.2 aux côtés d'autres modèles de langage de premier plan sur des références sélectionnées:
| Modèle | GLUE | SuperGLUE | SQuAD v2.0 | HumanEval | MMLU |
|---|---|---|---|---|---|
| Mistral 7B v0.2 | 92.5 | 89.7 | 93.2 | 48.5 | 78.3 |
| Llama 2 13B | 91.8 | 88.4 | 92.7 | 46.2 | 76.9 |
| Llama 1 34B | 93.1 | 90.2 | 93.8 | 49.1 | 79.2 |
| CodeLlama 7B | 90.6 | 87.1 | 91.5 | 49.8 | 75.4 |
Comme le montre le tableau, le modèle de base Mistral 7B v0.2 atteint des performances compétitives sur diverses références, dépassant souvent des modèles plus grands et approchant les performances des modèles spécialisés dans leurs domaines respectifs. Ces résultats mettent en évidence l'efficacité et l'efficacité du modèle pour aborder une large gamme de tâches de traitement du langage naturel.
Adaptation fine et flexibilité du déploiement
L'un des principaux atouts du modèle de base Mistral 7B v0.2 réside dans sa facilité d'adaptation fine et de déploiement. Le modèle est publié sous la licence permissive Apache 2.0, ce qui permet aux développeurs et aux chercheurs d'utiliser, de modifier et de distribuer le modèle sans restrictions. Cette disponibilité en open source favorise la collaboration, l'innovation et le développement d'applications diverses basées sur le modèle de base Mistral 7B v0.2.
Le modèle offre des options de déploiement flexibles pour répondre aux différents besoins des utilisateurs et aux configurations de l'infrastructure. Il peut être téléchargé et utilisé localement avec la mise en œuvre de référence fournie, ce qui permet un traitement et une personnalisation hors ligne. De plus, le modèle peut être facilement déployé sur des plateformes cloud populaires telles que AWS, GCP et Azure, permettant un déploiement évolutif et accessible dans le cloud.
Pour les utilisateurs qui préfèrent une approche plus rationalisée, le modèle de base Mistral 7B v0.2 est également disponible via le hub de modèles Hugging Face. Cette intégration permet aux développeurs d'accéder facilement et d'utiliser le modèle en utilisant l'écosystème familier de Hugging Face, bénéficiant des outils étendus et du support communautaire fournis par la plate-forme.
L'un des principaux avantages du modèle de base Mistral 7B v0.2 est sa capacité d'adaptation fine transparente. Le modèle sert de base excellente pour l'adaptation fine sur des tâches spécifiques, permettant aux développeurs d'adapter le modèle à leurs besoins uniques avec un effort minimal. Le modèle Mistral 7B Instruct, une version optimisée par adaptation fine pour le suivi des instructions, illustre l'adaptabilité et le potentiel du modèle pour atteindre des performances convaincantes grâce à l'adaptation fine ciblée.
Pour faciliter l'adaptation fine et l'expérimentation, Mistral AI fournit des exemples de code complets et des lignes directrices dans le référentiel Mistral AI Hackathon. Ce référentiel sert de ressource précieuse pour les développeurs, offrant des instructions étape par étape, les meilleures pratiques et des environnements préconfigurés pour l'adaptation fine du modèle de base Mistral 7B v0.2. En exploitant ces ressources, les développeurs peuvent rapidement commencer l'adaptation fine et construire des applications puissantes adaptées à leurs besoins spécifiques.
Mistral AI Hackathon: Stimuler l'innovation et la collaboration
La sortie du modèle de base Mistral 7B v0.2 coïncide avec l'événement très attendu du Hackathon Mistral AI, qui aura lieu à San Francisco du 23 au 24 mars 2024. Cet événement rassemble une communauté dynamique de développeurs, de chercheurs et d'enthousiastes de l'IA afin d'explorer les capacités du nouveau modèle de base et de collaborer sur des applications innovantes.
Le Hackathon Mistral AI offre une opportunité unique aux participants d'accéder en avant-première au modèle de base Mistral 7B v0.2 via une API dédiée et un lien de téléchargement. Cet accès exclusif permet aux participants d'être parmi les premiers à expérimenter le modèle et de tirer parti de ses fonctionnalités avancées pour leurs projets.
La collaboration est au cœur du hackathon, les participants formant des équipes pouvant aller jusqu'à quatre membres pour développer des projets IA créatifs. L'événement favorise un environnement de soutien et d'inclusion où des personnes d'horizons et de compétences diverses peuvent se réunir pour établir des idées, prototyper et construire des applications de pointe alimentées par le modèle de base Mistral 7B v0.2.
Tout au long du hackathon, les participants bénéficient du soutien pratique et des conseils fournis par l'équipe technique de Mistral AI, y compris les fondateurs de l'entreprise, Arthur et Guillaume. Cette interaction directe avec l'équipe de Mistral AI permet aux participants de bénéficier de précieuses informations, de recevoir une assistance technique et d'apprendre auprès des experts à l'origine du développement du modèle de base Mistral 7B v0.2.
Pour encourager davantage l'innovation et reconnaître les projets exceptionnels, le Hackathon Mistral AI offre un fonds de prix de 10 000 dollars en espèces et en crédits Mistral. Ces récompenses reconnaissent non seulement la créativité et l'expertise technique des participants, mais leur fournissent également les ressources nécessaires pour développer et étendre leurs projets au-delà du hackathon.
Le Hackathon Mistral AI sert de catalyseur pour mettre en valeur le potentiel du modèle de base Mistral 7B v0.2 et favoriser une communauté dynamique de développeurs passionnés par l'avancement de l'IA. En réunissant des personnes talentueuses, en offrant un accès à des technologies de pointe et en encourageant la collaboration, le hackathon vise à stimuler l'innovation et accélérer le développement d'applications révolutionnaires alimentées par le modèle de base Mistral 7B v0.2.
Pour commencer avec le modèle de base Mistral 7B v0.2, suivez ces étapes :
-
Téléchargez le modèle depuis le dépôt officiel de Mistral AI :
Téléchargement du modèle de base Mistral 7B v0.2 (opens in a new tab)
-
Ajustez le modèle en utilisant les exemples de code et les directives fournis dans le dépôt du Hackathon Mistral AI :
Hackathon Mistral AI : Promouvoir l'innovation

La sortie du modèle de base Mistral 7B v0.2 coïncide avec l'événement Hackathon Mistral AI, qui se tiendra à San Francisco du 23 au 24 mars 2024. Cet événement réunit des développeurs talentueux, des chercheurs et des passionnés d'IA afin d'explorer les capacités du nouveau modèle de base et de créer des applications innovantes.
Les participants au hackathon ont l'opportunité unique de :
- Accéder en avant-première au modèle de base Mistral 7B v0.2 via une API et un lien de téléchargement
- Collaborer en équipes pouvant aller jusqu'à quatre personnes pour développer des projets IA créatifs
- Bénéficier d'un soutien pratique et de conseils de la part du personnel technique de Mistral AI, y compris des fondateurs Arthur et Guillaume
- Concourir pour remporter 10 000 dollars en espèces et des crédits Mistral afin de développer davantage leurs projets
Le hackathon sert de plateforme pour mettre en valeur le potentiel du modèle de base Mistral 7B v0.2 et promouvoir une communauté de développeurs passionnés par l'avancement de l'IA.
Conclusion
La sortie du modèle de base Mistral 7B v0.2 marque une étape importante dans le développement de modèles de langage open-source. Avec sa fenêtre de contexte étendue, son architecture optimisée et ses performances de référence impressionnantes, ce modèle offre aux développeurs et chercheurs un outil puissant pour construire des applications NLP de pointe.
En fournissant un accès facile au modèle et en organisant des événements engageants tels que le Hackathon Mistral AI, Mistral AI démontre son engagement à promouvoir l'innovation et la collaboration au sein de la communauté de l'IA. À mesure que les développeurs explorent les capacités du modèle de base Mistral 7B v0.2, nous pouvons nous attendre à voir une vague de nouvelles applications passionnantes et de percées en traitement du langage naturel.
Embrassez l'avenir de l'IA avec le modèle de base Mistral 7B v0.2 et libérez le potentiel de compréhension et de génération de langage avancé dans vos projets.