Introduction à Jamba, le modèle révolutionnaire SSM-Transformer

AI21 Labs est fier de présenter Jamba, le premier modèle produit en série basé sur l'architecture révolutionnaire Mamba. En intégrant parfaitement la technologie d'État Structuré de l'Espace (SSM) de Mamba avec des éléments de l'architecture traditionnelle Transformer, Jamba surmonte les limitations des modèles SSM purs, offrant des performances et une efficacité exceptionnelles.
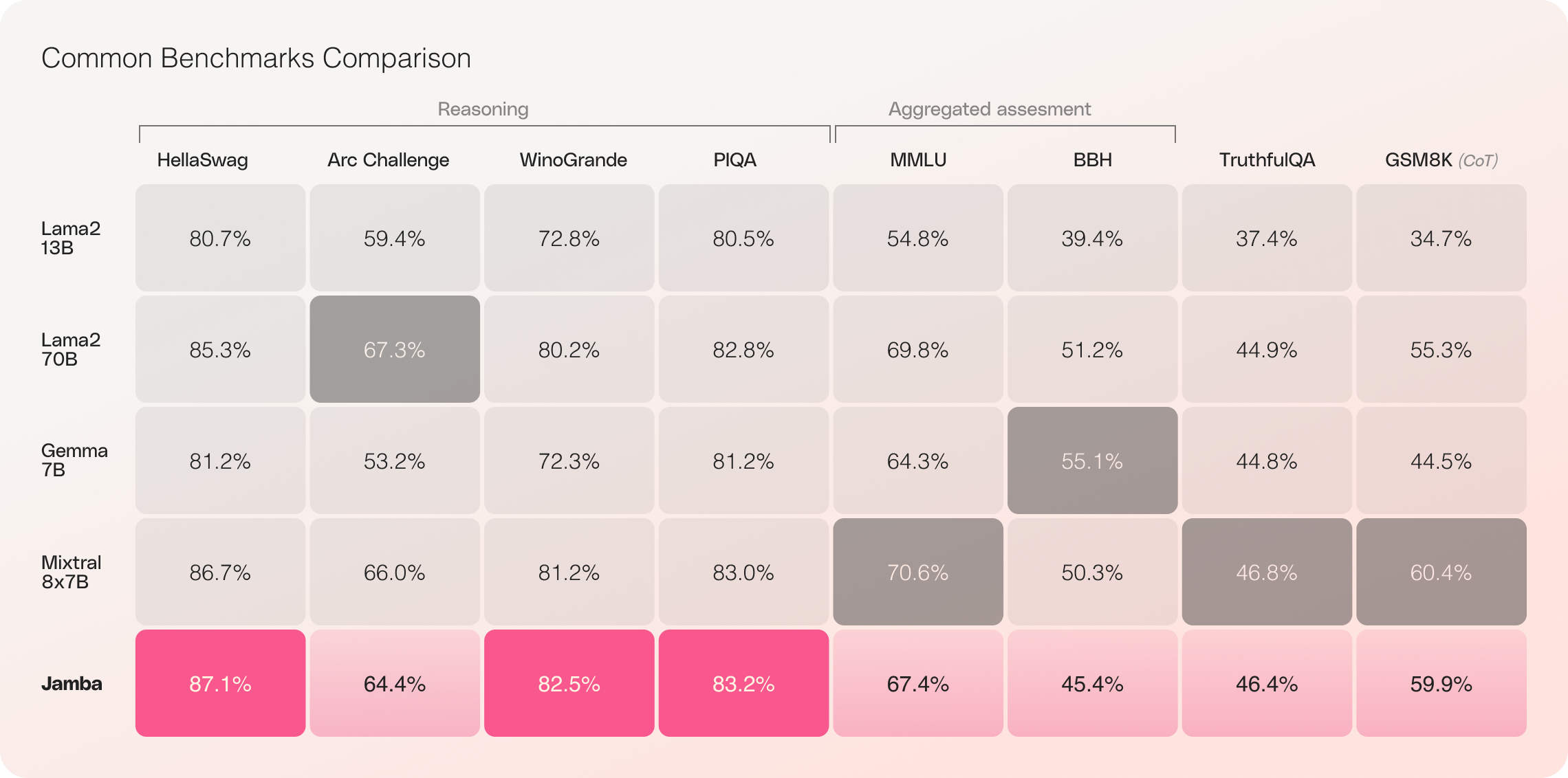
Avec sa fenêtre contextuelle impressionnante de 256K et ses gains de débit remarquables, Jamba est prêt à redéfinir le paysage de l'IA, ouvrant de nouvelles possibilités pour les chercheurs, les développeurs et les entreprises. Jamba a déjà démontré des résultats exceptionnels sur un large éventail de références, égalant ou surpassant d'autres modèles de pointe de sa catégorie.
TLDR : Jamba ne dispose pas de mécanismes de modération de sécurité et utilise la licence Open Source Apache-2.0.

Principales caractéristiques de Jamba
- Premier modèle produit en série basé sur Mamba : Jamba est pionnier dans l'utilisation de l'architecture hybride SSM-Transformer à une échelle et une qualité de production.
- Débit inégalé : Jamba atteint un débit 3 fois supérieur sur les contextes longs par rapport à Mixtral 8x7B, établissant de nouvelles normes en matière d'efficacité.
- Grande fenêtre contextuelle : Avec une fenêtre contextuelle de 256K, Jamba démocratise l'accès aux capacités étendues de gestion du contexte.
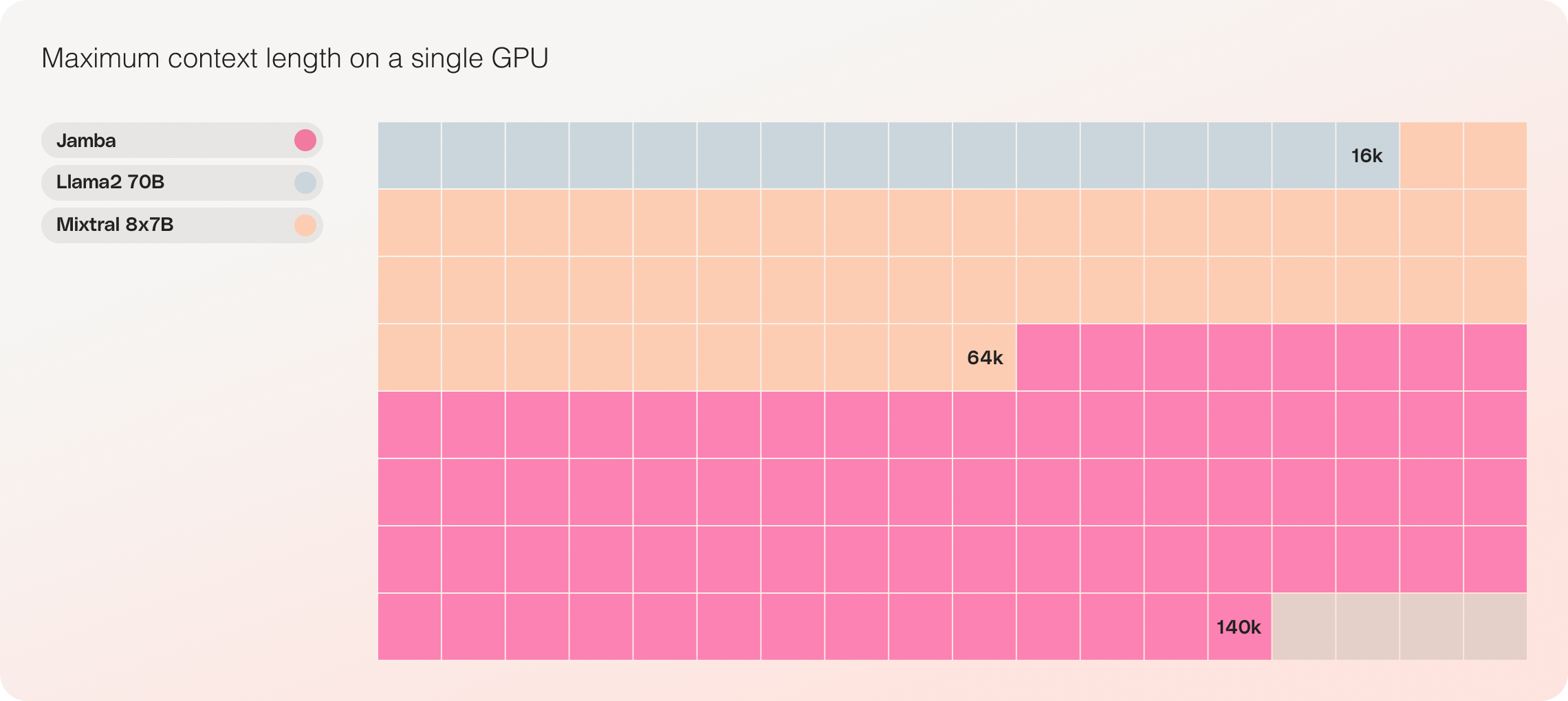
- Compatibilité avec une seule GPU : Jamba est le seul modèle de sa catégorie pouvant contenir jusqu'à 140K de contexte sur une seule GPU, le rendant plus accessible pour le déploiement et l'expérimentation.
- Disponibilité en open source : Publié avec des poids ouverts sous licence Apache 2.0, Jamba invite à d'autres optimisations et découvertes de la part de la communauté de l'IA.
- Intégration future au catalogue d'API NVIDIA : Jamba sera bientôt accessible depuis le catalogue d'API NVIDIA en tant que microservice d'inférence NVIDIA NIM, permettant aux développeurs d'applications d'entreprise de le déployer à l'aide de la plateforme logicielle NVIDIA AI Enterprise.
Jamba : Combinaison des meilleurs architectures Mamba et Transformer
Jamba représente une étape importante dans l'innovation LLM en incorporant avec succès Mamba à l'architecture Transformer et en adaptant le modèle hybride SSM-Transformer à une qualité de production.
Les LLM basés sur le Transformer traditionnel rencontrent deux grands défis :
- Empreinte mémoire importante : L'empreinte mémoire du Transformer augmente avec la longueur du contexte, ce qui rend difficile l'exécution de fenêtres de contexte longues ou de nombreux lots parallèles sans ressources matérielles étendues.
- Inférence lente sur les contextes longs : Le mécanisme d'attention dans les Transformers évolue de manière quadratique avec la longueur de la séquence, ralentissant le débit car chaque jeton dépend de toute la séquence précédente.
Mamba, proposé par des chercheurs des universités Carnegie Mellon et Princeton, répond à ces limites. Cependant, sans l'attention sur l'ensemble du contexte, Mamba peine à égaler la qualité de sortie des meilleurs modèles existants, en particulier sur les tâches liées à la récupération.

Jamba vs Mamba vs Transformer
L'architecture hybride de Jamba, composée de couches Transformer, Mamba et d'un mélange d'experts (MoE), optimise simultanément la mémoire, le débit et les performances. Les couches MoE permettent à Jamba d'utiliser seulement 12B de ses 52B de paramètres lors de l'inférence, ce qui rend ces paramètres actifs plus efficaces qu'un modèle basé uniquement sur Transformer de taille équivalente.
Mise à l'échelle de l'architecture hybride de Jamba
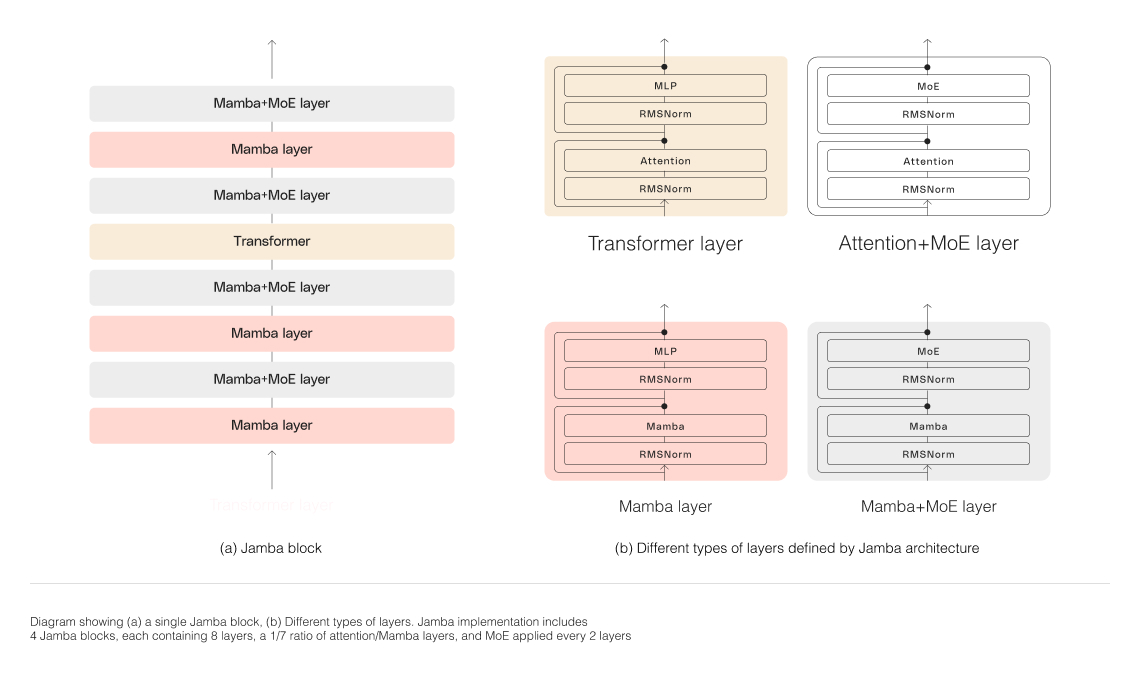
Pour réussir à mettre à l'échelle la structure hybride de Jamba, AI21 Labs a mis en œuvre plusieurs innovations architecturales clés :
-
Approche par blocs et couches : L'architecture de Jamba utilise une approche par blocs et couches, permettant une intégration transparente des architectures Transformer et Mamba. Chaque bloc de Jamba contient soit une couche d'attention, soit une couche Mamba, suivie d'un perceptron multicouche (MLP), ce qui donne un rapport global d'une couche Transformer sur huit couches.
-
Utilisation du mélange d'experts (MoE) : En utilisant des couches MoE, Jamba augmente le nombre total de paramètres du modèle tout en rationalisant le nombre de paramètres actifs utilisés lors de l'inférence. Cela permet d'augmenter la capacité du modèle sans augmenter les exigences de calcul correspondantes. Le nombre de couches MoE et d'experts a été optimisé pour maximiser la qualité et le débit du modèle sur un seul GPU de 80 Go tout en laissant suffisamment de mémoire pour les charges de travail d'inférence courantes.
Impressionnantes performances et efficacité de Jamba
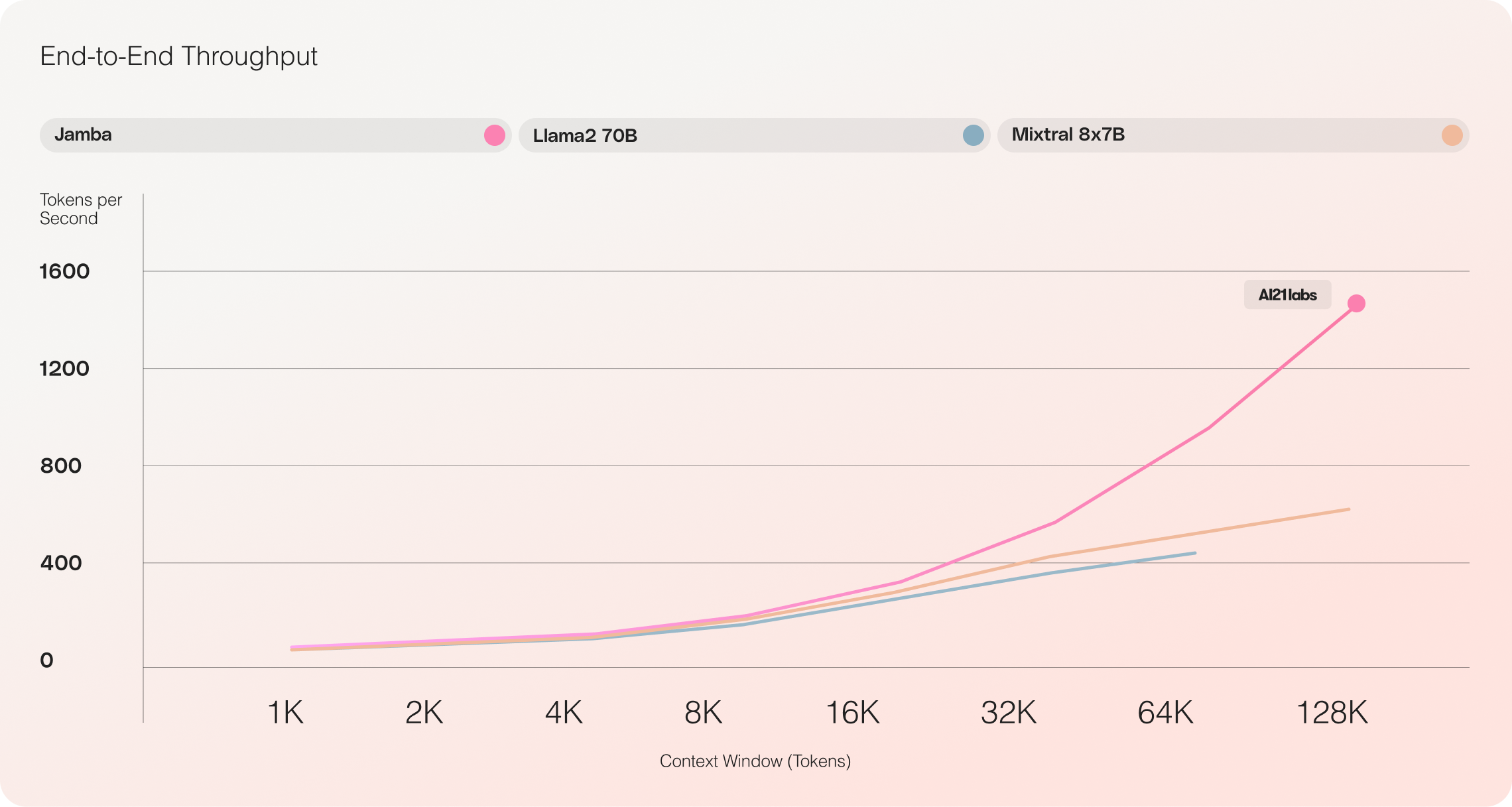
Jamba vs Llama 70B vs Mixtral 8x7B
Les évaluations initiales de Jamba ont donné des résultats impressionnants sur des mesures clés telles que le débit et l'efficacité. Ces références devraient s'améliorer davantage à mesure que la communauté continue d'expérimenter et d'optimiser cette technologie révolutionnaire.
- Efficacité : Jamba offre un débit 3 fois supérieur sur les contextes longs, ce qui le rend plus efficace que les modèles basés sur Transformer comparables tels que Mixtral 8x7B.
- Rentabilité : Grâce à sa capacité à faire tenir 140K contextes sur un seul GPU, Jamba permet un déploiement et des opportunités d'expérimentation plus accessibles par rapport à d'autres modèles open-source de taille similaire.
Des optimisations futures, telles que le parallélisme MoE amélioré et des implémentations Mamba plus rapides, devraient encore améliorer ces gains déjà impressionnants.
Commencez à construire avec Jamba
Jamba est désormais disponible sur Hugging Face, publié avec des poids ouverts sous la licence Apache 2.0. En tant que modèle de base, Jamba est destiné à servir de base pour le fine-tuning, l'entraînement et le développement de solutions personnalisées. Il est essentiel d'ajouter des balises appropriées pour une utilisation responsable et sûre.
Une version de démonstration de Jamba sera bientôt disponible en version bêta via la plateforme AI21. Pour partager vos projets, fournir des commentaires ou poser des questions, rejoignez la conversation sur Discord.
Conclusion
L'introduction de Jamba marque une avancée significative dans la technologie de l'IA, mettant en avant le potentiel immense des architectures hybrides SSM-Transformer. En combinant les forces de Mamba et de Transformer tout en optimisant l'efficacité et les performances, Jamba établit de nouvelles normes pour les modèles d'IA de sa catégorie.
Avec sa capacité impressionnante de traitement des contextes, son débit et sa rentabilité, Jamba est prêt à révolutionner le paysage de l'IA, permettant aux chercheurs, développeurs et entreprises de repousser les limites de ce qui est possible. Alors que la communauté continue d'explorer et de s'appuyer sur les innovations de Jamba, nous pouvons anticiper une nouvelle vague d'applications d'IA qui façonneront l'avenir de l'intelligence artificielle.