Comment Groq AI rend les requêtes LLM x10 plus rapides

Groq, une entreprise proposant des solutions d'IA génératives, redéfinit le paysage de l'inférence des grands modèles de langage (LLM) avec son moteur d'inférence de l'Unité de Traitement du Langage (LPU) révolutionnaire. Cet accélérateur spécialement conçu permet de surmonter les limites des architectures traditionnelles de CPU et de GPU et offre une vitesse et une efficacité inégalées dans le traitement des LLM.
Vous voulez connaître les dernières actualités sur les LLM ? Consultez le tableau de bord LLM le plus récent !

L'architecture LPU : Une plongée approfondie
Au cœur de l'architecture LPU de Groq se trouve une conception monocœur qui privilégie les performances séquentielles. Cette approche permet à l'LPU d'atteindre une densité de calcul exceptionnelle, avec une performance maximale de 1 PetaFLOP/s sur une seule puce. L'architecture unique de l'LPU élimine également les goulots d'étranglement de la mémoire externe en incorporant 220 Mo de SRAM sur puce, offrant une bande passante mémoire de 1,5 To/s époustouflante.
Les capacités de mise en réseau synchrone de l'LPU permettent une extensibilité transparente dans les déploiements à grande échelle. Avec une bande passante bidirectionnelle de 1,6 To/s par LPU, la technologie de Groq peut gérer efficacement les transferts massifs de données nécessaires à l'inférence des LLM. De plus, l'LPU prend en charge une large gamme de niveaux de précision, allant de FP32 à INT4, permettant une haute précision même avec des paramètres de précision plus bas.
Évaluation des performances de Groq
Le moteur d'inférence de l'LPU de Groq a systématiquement surpassé les géants de l'industrie dans divers tests. Dans les tests internes menés sur le modèle Llama-2 70B de Meta AI, Groq a atteint un impressionnant 300 jetons par seconde par utilisateur. Cela représente un bond significatif en matière de vitesse d'inférence des LLM, dépassant les performances des systèmes traditionnels basés sur les GPU.
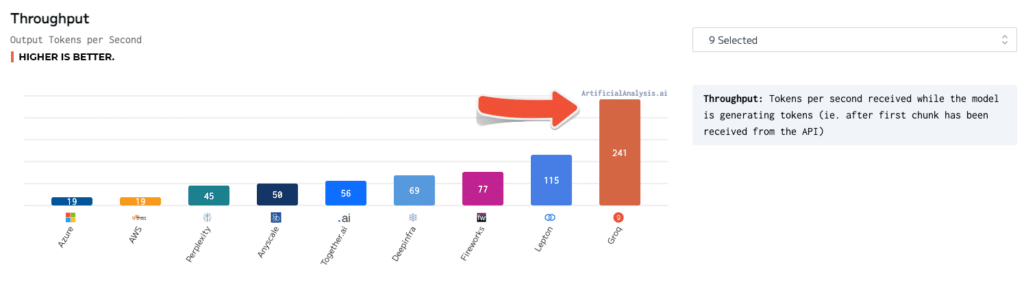
Des benchmarks indépendants ont également validé la supériorité de Groq. Dans des tests réalisés par ArtificialAnalysis.ai, l'API Llama 2 Chat (70B) de Groq a atteint un débit de 241 jetons par seconde, soit plus du double de la vitesse des autres fournisseurs d'hébergement. Groq s'est également distingué dans d'autres indicateurs de performance clés, tels que la latence par rapport au débit, le temps de réponse total et la variance du débit.
Pour mettre ces chiffres en perspective, imaginons un scénario dans lequel un utilisateur interagit avec un chatbot alimenté par une IA. Avec le moteur d'inférence LPU de Groq, le chatbot peut générer des réponses à raison de 300 jetons par seconde, permettant des conversations quasi instantanées. En revanche, un système basé sur les GPU ne pourrait générer que 50 à 100 jetons par seconde, entraînant des délais perceptibles et une expérience utilisateur moins engageante.
Groq vs. Autres technologies d'IA

Comparé aux GPU de NVIDIA, l'LPU de Groq présente un avantage clair en termes de performances INT8, qui sont cruciales pour l'inférence de LLM haute vitesse. Dans un benchmark comparant l'LPU au GPU A100 de NVIDIA, l'LPU a atteint une accélération de 3,5x sur le modèle Llama-2 70B, traitant 300 jetons par seconde contre 85 jetons par seconde pour l'A100.
La technologie de Groq se démarque également des autres modèles d'IA tels que ChatGPT et Gemini de Google. Bien que des chiffres de performances spécifiques pour ces modèles ne soient pas disponibles publiquement, la vitesse et l'efficacité démontrées par Groq suggèrent qu'il a le potentiel de les surpasser dans des applications concrètes.
Utilisation de Groq AI
Groq propose une suite complète d'outils et de services pour faciliter le déploiement et l'utilisation de sa technologie LPU. La suite GroqWare, qui comprend le Compilateur Groq, offre une expérience de bout en bout pour mettre rapidement en marche les modèles. Voici un exemple de compilation et d'exécution d'un modèle à l'aide du Compilateur Groq :
# Compiler le modèle
groq compile model.onnx -o model.groq
# Exécuter le modèle sur l'LPU
groq run model.groq -i input.bin -o output.binPour ceux qui préfèrent une personnalisation plus poussée, Groq permet également la programmation manuelle de l'architecture Groq, ce qui permet de développer des applications sur mesure et d'optimiser les performances au maximum. Voici un exemple d'assemblage Groq codé à la main pour une simple multiplication matricielle :
; Multiplication matricielle sur l'LPU de Groq
; Supposons que les matrices A et B sont chargées en mémoire
; Charger les dimensions de la matrice
ld r0, [n]
ld r1, [m]
ld r2, [k]
; Initialiser la matrice résultat C
mov r3, 0
; Boucle externe sur les lignes de A
mov r4, 0
loop_i:
; Boucle interne sur les colonnes de B
mov r5, 0
loop_j:
; Accumuler le produit scalaire
mov r6, 0
mov r7, 0
loop_k:
ld r8, [A + r4 * m + r7]
ld r9, [B + r7 * k + r5]
mul r10, r8, r9
add r6, r6, r10
add r7, r7, 1
cmp r7, r2
jlt loop_k
; Stocker le résultat dans C
st [C + r4 * k + r5], r6
add r5, r5, 1
cmp r5, r2
jlt loop_j
add r4, r4, 1
cmp r4, r0
jlt loop_iLes développeurs et chercheurs peuvent également tirer parti de la puissante technologie de Groq grâce à l'API Groq, qui offre un accès aux capacités d'inférence en temps réel. Voici un exemple d'utilisation de l'API Groq pour générer du texte à l'aide du modèle Llama-2 70B :
import groq
# Initialiser le client Groq
client = groq.Client(api_key="your_api_key")
# Configurer le modèle et les paramètres
model = "llama-2-70b"
prompt = "Il était une fois, dans un pays lointain, très lointain..."
max_tokens = 100
# Générer du texte
response = client.generate(model=model, prompt=prompt, max_tokens=max_tokens)
# Afficher le texte généré
print(response.text)Applications potentielles et impact
Les temps de réponse quasi instantanés rendus possibles par le moteur d'inférence LPU de Groq ouvrent de nouvelles possibilités dans de nombreux secteurs. Dans le domaine de la finance, la technologie de Groq peut être exploitée pour la détection en temps réel de fraudes et l'évaluation des risques. En traitant d'énormes quantités de données de transactions et en identifiant des anomalies en millisecondes, les institutions financières peuvent prévenir les activités frauduleuses et protéger les avoirs de leurs clients.
Dans le domaine de la santé, l'LPU de Groq peut révolutionner les soins aux patients en permettant l'analyse en temps réel des données médicales. De l'analyse des images médicales à celle des dossiers de santé électroniques, la technologie de Groq peut aider les professionnels de la santé à établir des diagnostics rapides et précis, améliorant ainsi les résultats pour les patients.
Les véhicules autonomes peuvent également bénéficier énormément des capacités d'inférence à grande vitesse de Groq. En traitant les données des capteurs et en prenant des décisions en une fraction de seconde, les systèmes d'intelligence artificielle alimentés par Groq peuvent améliorer la sécurité et la fiabilité des voitures autonomes, ouvrant la voie à un avenir de transport intelligent.
Conclusion
Le moteur d'inférence LPU de Groq représente un pas significatif en avant dans le domaine de l'accélération de l'intelligence artificielle. Grâce à son architecture innovante, ses références impressionnantes et sa gamme complète d'outils et de services, Groq permet aux développeurs et aux organisations de repousser les limites de ce qui est possible avec les grands modèles de langage.
A mesure que la demande d'inférence en temps réel de l'intelligence artificielle continue de croître, Groq est bien placé pour être à l'avant-garde de la prochaine génération de solutions alimentées par l'IA. Des chatbots et des assistants virtuels aux systèmes autonomes et au-delà, les applications potentielles de la technologie de Groq sont vastes et transformatrices.
En s'engageant à démocratiser l'accès à l'IA et à favoriser l'innovation, Groq révolutionne non seulement le paysage technique, mais façonne également l'avenir de notre interaction avec et des avantages tirés de l'intelligence artificielle. Alors que nous nous trouvons à l'aube d'une ère dirigée par l'IA, la technologie révolutionnaire de Groq est prête à être un catalyseur de progrès et de découvertes sans précédent dans les années à venir.
Envie de connaître les dernières nouvelles sur LLM ? Consultez le dernier classement de LLM !