Comment exécuter des modèles Mistral localement - Un guide complet

Dans le paysage en constante évolution de l'intelligence artificielle, Mistral AI s'est imposé comme un phare de l'innovation, ouvrant de nouveaux horizons dans le domaine des modèles de langage de grande envergure (LLM). Avec la présentation de ses modèles révolutionnaires, Mistral AI fait progresser non seulement la frontière de l'apprentissage automatique, mais aussi démocratise l'accès à une technologie de pointe. Ce guide vise à éclairer les subtilités des offres de Mistral AI et à fournir une feuille de route complète pour exploiter leurs capacités localement.
Quels sont ces modèles Mistral AI ?
Mistral AI a dévoilé une gamme de modèles de langue qui ne sont pas seulement des itérations, mais des avancées en linguistique computationnelle. Au cœur de cette suite se trouvent Mistral 7B et Mistral 8x7B, chacun conçu pour répondre à des besoins et des capacités computationnelles divers.
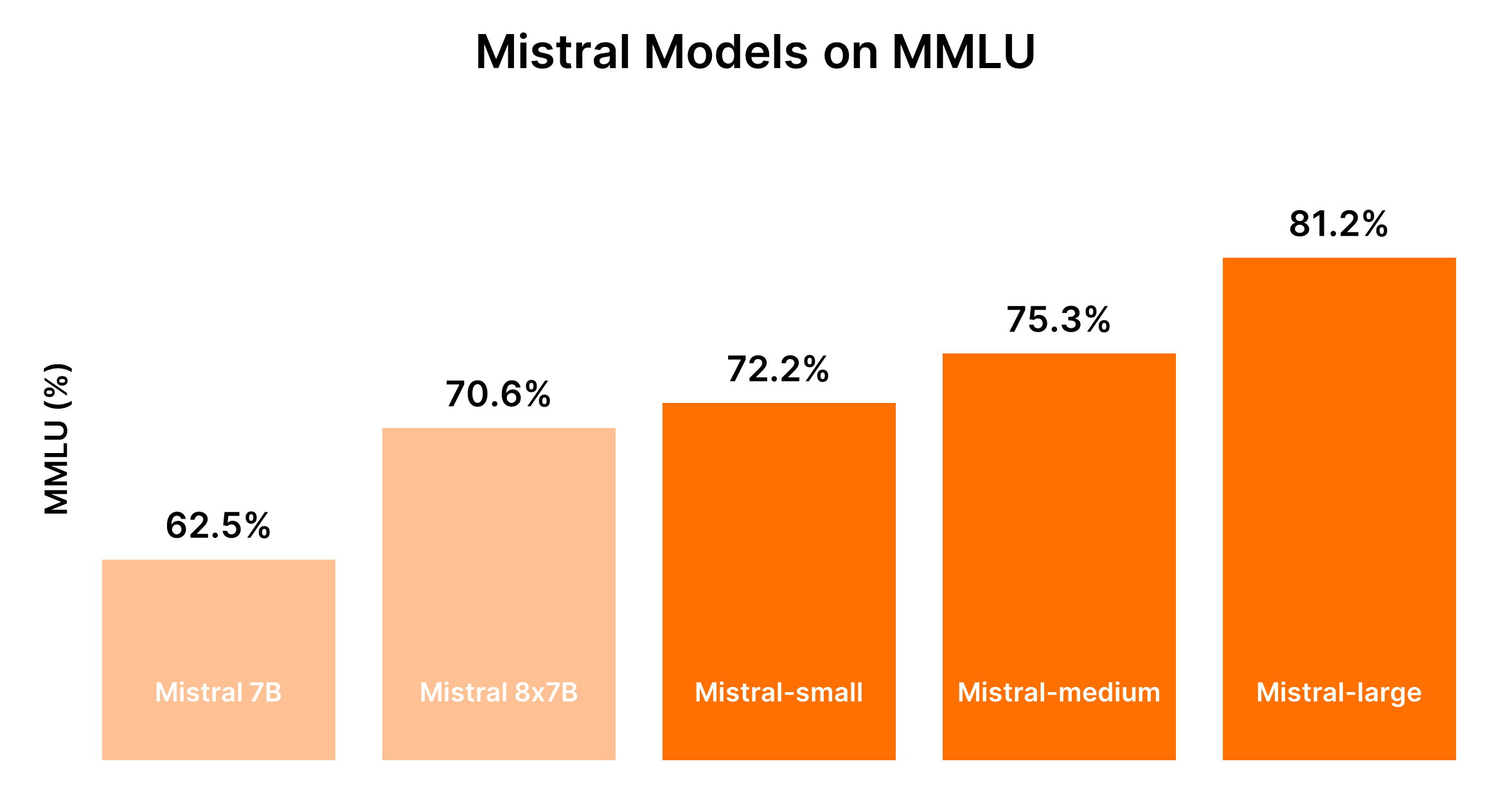
Comparaison des modèles Mistral AI (Mistral 7B vs Mistral 8x7b vs Mistral Small vs Mistral Medium vs Mistral Large)
Compris. En fonction des informations fournies et en mettant l'accent sur la création de tableaux au format markdown pour une comparaison directe, structurons l'analyse comparative des modèles Mistral AI.
Analyse comparative des modèles Mistral AI
Mistral AI propose une gamme de modèles, chacun adapté à des cas d'utilisation différents, des tâches de masse simples aux capacités de raisonnement complexes. Voici des analyses comparatives et des résultats de performance au format markdown pour une meilleure compréhension.
Aperçu des modèles et des cas d'utilisation
| Identifiant du modèle | Alias | Cas d'utilisation |
|---|---|---|
| open-mistral-7b | mistral-tiny-2312 | Tâches de masse simples telles que la classification, le support client ou la génération de texte |
| open-mixtral-8x7b | mistral-small-2312 | Similaire à open-mistral-7b, adapté pour des tâches de masse simples |
| mistral-small-latest | mistral-small-2402 | Tâches légèrement avancées nécessitant un raisonnement minimal |
| mistral-medium-latest | mistral-medium-2312 | Tâches intermédiaires telles que l'extraction de données, la résumé de documents, la rédaction d'e-mails |
| mistral-large-latest | mistral-large-2402 | Tâches complexes nécessitant une grande capacité de raisonnement, comme la génération de texte synthétique, la génération de code |
Performances et compromis de coût
Les performances des modèles Mistral sont généralement proportionnelles à leur taille, les modèles plus grands offrant des capacités accrues mais à des coûts plus élevés. Le tableau suivant résume les classements de performance basés sur le benchmark MMLU et les considérations générales de coût.
| Modèle | Classement de performance | Considération du coût |
|---|---|---|
| Mistral 7B (tiny-2312) | 5e | Le plus rentable pour les tâches simples |
| Mixtral 8x7B (small-2312) | 4e | Rentable pour les tâches simples en masse |
| Mistral Small (small-2402) | 3e | Coût modéré, adapté aux tâches avec raisonnement minimal |
| Mistral Medium (medium-2312) | 2e | Coût plus élevé, performances équilibrées pour les tâches intermédiaires |
| Mistral Large (large-2402) | 1er | Coût le plus élevé, performances inégalées pour les tâches complexes |
Étant donné la nature dynamique des performances des LLM et des coûts associés, il est conseillé de se référer aux benchmarks et aux prix actuels pour une comparaison plus précise. Pour des benchmarks à jour et des informations sur les performances, des plateformes comme le Tableau de bord de l'arène des chatbots (opens in a new tab) de Hugging Face et Artificial Analysis (opens in a new tab) peuvent fournir des informations précieuses.
Orientations pour la prise de décision : Quel modèle Mistral AI choisir ?
Le choix du bon modèle dépend de l'équilibre entre les besoins en termes de performances et les contraintes budgétaires, en tenant compte de la complexité des tâches que votre application envisage de gérer.
- Pour les tâches simples : Commencez par Mistral Small ou Mistral 7B pour plus de rentabilité.
- Pour les tâches intermédiaires à complexes : Évaluez si les performances améliorées de Mistral Medium ou Mistral Large justifient les dépenses supplémentaires en fonction des besoins spécifiques de votre application.
Cette comparaison structurée vise à faciliter la prise de décisions éclairées lors de la sélection des offres de modèles de Mistral AI, en veillant à ce que le modèle choisi corresponde aux exigences fonctionnelles et aux contraintes budgétaires de votre projet.

Partie 1. Comment exécuter Mistral localement avec Ollama (la méthode facile)
L'exécution de modèles Mistral AI localement avec Ollama offre un moyen accessible de tirer parti de la puissance de ces LLM avancés directement sur votre machine. Cette approche est idéale pour les développeurs, les chercheurs et les passionnés qui souhaitent expérimenter l'analyse et la génération de texte basées sur l'IA, entre autres, sans dépendre des services cloud. Voici un guide concis pour vous aider à démarrer :
Étape 1 : Télécharger Ollama
- Rendez-vous sur la page de téléchargement d'Ollama et choisissez la version appropriée pour votre système d'exploitation. Pour les utilisateurs de macOS, vous téléchargerez un fichier
.dmg. - Installez Ollama en faisant glisser le fichier téléchargé dans votre répertoire
/Applications.
Étape 2 : Explorer les commandes d'Ollama
Ouvrez votre terminal et saisissez ollama pour voir la liste des commandes disponibles. Vous verrez des options telles que serve, create, show, run, pull, et plus encore.
Étape 3 : Installation de Mistral AI
Pour installer un modèle Mistral AI, vous devez d'abord trouver le modèle que vous souhaitez installer. Si vous êtes intéressé par la version Mistral:instruct, vous pouvez l'installer directement ou la récupérer si elle n'est pas déjà sur votre machine.
- Pour l'exécuter directement (et le télécharger si nécessaire) :
ollama run mistral:instruct - Pour pré-télécharger le modèle :
ollama pull mistral:instruct
Étape 4 : Interagir avec Mistral AI
Une fois le modèle installé, vous pouvez interagir avec lui en mode interactif ou en passant des entrées directement.
-
Pour le mode interactif :
ollama run mistral --verboseEnsuite, suivez les invites pour entrer vos requêtes.
-
Pour le mode non interactif (entrée directe) : Supposons que vous ayez un article que vous souhaitez résumer enregistré dans
bbc.txt. Vous pouvez passer directement le contenu de l'article à Mistral pour le résumer :ollama run mistral --verbose "Please can you summarise this article: $(cat bbc.txt)"Remplacez
"Please can you summarise this article: $(cat bbc.txt)"par une instruction pertinente pour votre tâche.
Analyse de la sortie d'exemple
Votre terminal affichera la sortie du modèle, y compris le résumé ou la réponse à votre demande. Il est fascinant de voir comment Mistral traite et comprend des requêtes complexes, offrant même des corrections lorsqu'il est interpellé sur des inexactitudes.
Exécution de Mistral AI à partir de l'API HTTP
Ollama prend également en charge une API HTTP, permettant une interaction programmatique avec les modèles.
- Exemple de requête
curl:curl -X POST http://localhost:11434/api/generate -d '{ "model": "mistral", "prompt": "Quel est le sentiment de cette phrase : La situation entourant l'assistant vidéo arbitre est à un point de crise." }'
Cette méthode renvoie des réponses JSON qui peuvent être analysées de manière programmatique, offrant ainsi un moyen flexible d'intégrer les capacités de Mistral AI dans des applications.
L'exécution de Mistral AI avec Ollama sur une machine locale offre de vastes possibilités pour exploiter l'intelligence artificielle dans des projets personnels, de développement et de recherche. La facilité d'installation et d'utilisation, associée à la puissance des LLM de Mistral, en fait une option attrayante pour quiconque souhaite explorer les frontières de la technologie de l'intelligence artificielle.
Partie 2. Comment exécuter Mistral 7B localement sur Windows
Mistral 7B peut être utilisé sur plusieurs plateformes, notamment HuggingFace, Vertex AI, Replicate, Sagemaker Jumpstart et Baseten. La fonctionnalité "Modèles" de Kaggle offre également une approche simplifiée, vous permettant de commencer par l'inférence ou le fine-tuning en quelques minutes sans avoir besoin de télécharger le modèle ou les données.
Prérequis pour accéder à Mistral 7B
Avant de commencer, assurez-vous que votre environnement est à jour pour éviter les erreurs courantes telles que KeyError: 'mistral' :
!pip install -q -U transformers
!pip install -q -U accelerate
!pip install -q -U bitsandbytesMise en œuvre de la quantification sur 4 bits
Pour accélérer le chargement du modèle et réduire l'utilisation de la mémoire, la quantification sur 4 bits est utilisée :
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig, pipeline
import torch
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
)Chargement de Mistral 7B dans les cahiers Kaggle
Les cahiers Kaggle facilitent l'ajout de Mistral 7B grâce à une simple interaction avec l'interface utilisateur. Après avoir sélectionné la variation et la version du modèle appropriées, vous pouvez facilement charger le modèle et le tokenizer pour l'utiliser :
model_name = "/kaggle/input/mistral/pytorch/7b-v0.1-hf/1"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
load_in_4bit=True,
quantization_config=bnb_config,
torch_dtype=torch.bfloat16,
device_map="auto",
trust_remote_code=True,
)L'utilisation de la fonction pipeline simplifie le processus de génération de réponses en fonction de la requête donnée.
Exemple d'inférence
En définissant une requête et en invoquant le pipeline, Mistral 7B génère des réponses cohérentes et pertinentes sur le plan contextuel, illustrant sa compréhension de concepts complexes tels que la régularisation en apprentissage automatique :
prompt = "En tant que data scientist, pouvez-vous expliquer le concept de régularisation en apprentissage automatique ?"
sequences = pipe(
prompt,
do_sample=True,
max_new_tokens=100,
temperature=0.7,
top_k=50,
top_p=0.95,
num_return_sequences=1,
)
print(sequences[0]['generated_text'])Comment effectuer un fine-tuning de Mistral 7B
Le processus de fine-tuning implique la mise à jour des bibliothèques, la configuration des modules et l'adaptation du modèle à votre jeu de données. En utilisant les cahiers Kaggle, les clés API pour des services tels que Hugging Face et Weights & Biases sont stockées et accessibles de manière sécurisée. Cette section détaille les étapes et configurations essentielles pour un fine-tuning efficace, vous permettant ainsi de maximiser le potentiel du modèle sur votre jeu de données spécifique.
- Mise à jour et installation des bibliothèques nécessaires : Assure la compatibilité et l'accès aux dernières fonctionnalités pour le fine-tuning.
- Chargement des modules et configuration de l'accès à l'API : Facilite l'interaction avec les services externes et les dépôts de modèles.
- Configuration et entraînement du modèle : Adapte le modèle aux subtilités de votre jeu de données, en exploitant la puissance de PEFT (Fine-tuning de paramètres efficace) pour un entraînement efficace.
- Évaluation et enregistrement de votre modèle : Évalue les performances du modèle et enregistre le fine-tuning effectué.
Le guide détaillé vise à vous équiper des outils et des connaissances nécessaires pour exploiter efficacement les capacités du modèle Mistral 7B. De l'accès au modèle à son fine-tuning sur un jeu de données spécifique, chaque étape est conçue pour améliorer les capacités de traitement du langage naturel de votre projet.
Partie 3. Comment exécuter Mixtral 8x7b localement avec LlamaIndex et Ollama

La puissance européenne de l'IA, Mistral AI, a récemment dévoilé son modèle "mélange d'experts", Mixtral 8x7b. Ce modèle, composé de huit experts, chacun entraîné avec 7 milliards de paramètres, suscite un intérêt considérable pour ses performances qui correspondent, voire dépassent, celles de GPT-3.5 et Llama2 70b sur diverses références.
Étape 1 : Installer Ollama
Ollama, un outil open source disponible pour macOS, Linux et Windows (via Windows Subsystem for Linux), simplifie le processus d'exécution de modèles locaux. Avec Ollama, vous pouvez lancer Mixtral avec une seule commande :
ollama run mixtralCette commande télécharge le modèle (ce qui peut prendre un certain temps) et nécessite une quantité importante de RAM (48 Go) pour fonctionner correctement. Pour les systèmes moins performants, Mistral 7b est une alternative viable.
Étape 2 : Installer les dépendances
Pour intégrer Mixtral à LlamaIndex, vous aurez besoin de plusieurs dépendances. Installez-les à l'aide de pip :
pip install llama-index qdrant_client torch transformersÉtape 3 : Test de validation
Vérifiez la configuration avec un "test de validation" en utilisant Ollama et LlamaIndex :
from llama_index.llms import Ollama
llm = Ollama(model="mixtral")
response = llm.complete("Qui est Laurie Voss?")
print(response)Étape 4 : Charger les données et les indexer
Préparation des données :
Utilisez n'importe quel ensemble de données pour cet exemple ; ici, nous utilisons une collection de tweets. Qdrant, une base de données vectorielle open source, stocke les données. Les extraits de code suivants montrent le processus de chargement et d'indexation des données avec Qdrant et LlamaIndex :
from pathlib import Path
import qdrant_client
from llama_index import VectorStoreIndex, ServiceContext, download_loader
from llama_index.llms import Ollama
from llama_index.storage.storage_context import StorageContext
from llama_index.vector_stores.qdrant import QdrantVectorStore
## Initialiser Qdrant et charger les tweets
client = qdrant_client.QdrantClient(path="./qdrant_data")
vector_store = QdrantVectorStore(client=client, collection_name="tweets")
storage_context = StorageContext.from_defaults(vector_store=vector_store)
## Configurer le contexte de service avec Mixtral et incorporer localement
llm = Ollama(model="mixtral")
service_context = ServiceContext.from_defaults(llm=llm, embed_model="local")
## Indexer et interroger les données
index = VectorStoreIndex.from_documents(documents, service_context=service_context, storage_context=storage_context)
query_engine = index.as_query_engine()
response = query_engine.query("Que pense l'auteur de Star Trek ? Donnez des détails.")
print(response)Vérification de l'index :
La dernière étape consiste à utiliser l'index préconstruit pour répondre aux requêtes. Ce processus ne nécessite pas de rechargement des données car elles sont déjà indexées dans Qdrant :
import qdrant_client
from llama_index import VectorStoreIndex, ServiceContext
from llama_index.llms import Ollama
from llama_index.vector_stores.qdrant import QdrantVectorStore
## Charger le magasin de vecteurs et Mixtral
client = qdrant_client.QdrantClient(path="./qdrant_data")
vector_store = QdrantVectorStore(client=client, collection_name="tweets")
llm = Ollama(model="mixtral")
service_context = ServiceContext.from_defaults(llm=llm, embed_model="local")
## Charger l'index et effectuer une requête
index = VectorStoreIndex.from_vector_store(vector_store=vector_store, service_context=service_context)
query_engine = index.as_query_engine(similarity_top_k=20)
response = query_engine.query("L'auteur aime-t-il SQL ? Donnez des détails.")
print(response)Partie 4. Comment exécuter Mistral 8x7B localement avec llama.cpp
L'exécution des modèles Mistral AI localement est devenue plus accessible grâce à des outils tels que llama.cpp et le plugin llm-llama-cpp. La sortie du modèle Mixtral 8x7B, un modèle de mélange spars de haute qualité (SMoE), a marqué une avancée significative dans le paysage de l'IA en licence ouverte. Voici un bref guide sur la manière d'exécuter Mixtral 8x7B localement à l'aide de llama.cpp et des outils associés.
Installation et exécution de Mixtral 8x7B localement
-
Installer l'outil LLM : Tout d'abord, assurez-vous d'avoir LLM installé sur votre machine. LLM sert de passerelle pour l'exécution de divers modèles d'IA localement.
pipx install llm -
Installer le plugin
llm-llama-cpp: Ce plugin est nécessaire pour exécuter Mixtral et d'autres modèles pris en charge parllama.cpp.llm install llm-llama-cpp -
Configurer
llama-cpp-python: Pour les Mac avec Apple Silicon, la configuration peut inclure l'activation du support de Metal :CMAKE_ARGS="-DLLAMA_METAL=on" FORCE_CMAKE=1 llm install llama-cpp-pythonLes instructions détaillées peuvent varier en fonction de votre plateforme, veuillez donc vous référer à la documentation de
llm-llama-cpppour obtenir des indications. -
Télécharger le modèle Mixtral : Vous aurez besoin du fichier GGUF pour Mixtral 8x7B. Choisissez une taille de fichier adaptée à vos besoins ; par exemple, la variante de 36 Go pour la version Instruct du modèle :
curl -LO 'https://huggingface.co/TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF/resolve/main/mixtral-8x7b-instruct-v0.1.Q6_K.gguf?download=true' -
Exécuter le modèle : Avec le modèle téléchargé, vous pouvez exécuter Mixtral 8x7B en utilisant l'outil
llm:llm -m gguf -o path mixtral-8x7b-instruct-v0.1.Q6_K.gguf '[INST] Écrivez une fonction Python qui télécharge un fichier à partir d'une URL[/INST]'Cette commande spécifie d'utiliser le modèle GGUF avec l'option
-m ggufet fournit le chemin vers le fichier GGUF téléchargé avec l'option-o path.
Autres considérations
-
Mode interactif : Si vous souhaitez interagir avec le modèle de manière plus conversationnelle, envisagez d'exécuter
llmen mode interactif. Ce mode permet un dialogue aller-retour avec le modèle d'IA. -
Construction de la phrase d'appel : Le préfixe
[INST]dans l'exemple de commande ci-dessus indique la nature basée sur des instructions de la phrase d'appel, adaptée aux versions instructives des modèles. Adaptez vos phrases d'appel pour qu'elles correspondent au format d'entrée attendu par le modèle pour des résultats optimaux.
Partie 5. Exécution de Mistral 7B localement sur un iPhone

L'exécution du modèle Mistral 7B sur un iPhone nécessite quelques étapes techniques, car les appareils iOS ont généralement plus de restrictions que les environnements de bureau. Voici un guide simplifié étape par étape :
-
Prérequis :
- Assurez-vous que votre iPhone exécute la dernière version d'iOS pour éviter les problèmes de compatibilité.
- Installez un environnement de développement d'applications iOS, tel que Xcode, sur votre Mac, pour compiler et exécuter l'application personnalisée qui utilisera Mistral 7B.
-
Choix de l'option d'exécution : Pour le déploiement sur iPhone,
llm-llama-cpppourrait être la plus appropriée en raison de sa compatibilité avec les environnements C++, qui peuvent être intégrés dans des projets iOS. -
Configuration de l'environnement de développement :
- Téléchargez le fichier GGUF pour
llm-llama-cppà partir du dépôt officiel. - Ouvrez Xcode et créez un nouveau projet iOS.
- Intégrez la bibliothèque
llm-llama-cppdans votre projet. Cela peut nécessiter des dépendances supplémentaires, veuillez donc vous référer à la documentation.
- Téléchargez le fichier GGUF pour
-
Codage :
- Écrivez du code Swift ou Objective-C pour interagir avec la bibliothèque C++. Cela peut impliquer la création d'un en-tête de liaison pour utiliser du code C++ dans des projets Swift.
- Initialisez le modèle dans votre application, en gérant toute configuration requise, telle que le chemin du modèle et les paramètres.
-
Test et déploiement :
- Testez l'application sur votre iPhone, en vous assurant que le modèle s'exécute correctement et fonctionne comme prévu.
- Déployez l'application via Xcode, soit à usage personnel, soit, si elle est conforme aux directives d'Apple, soumettez-la à l'App Store.
Partie 6. Exécution de Mistral AI localement avec l'API

Pour exécuter Mistral AI localement en utilisant son API, suivez ces étapes en vous assurant de disposer d'un environnement capable d'effectuer des requêtes HTTP, tel que Postman pour les tests ou des langages de programmation ayant des capacités de requêtes HTTP (par exemple, Python avec la bibliothèque requests).
Prérequis :
- Obtenez une clé API (opens in a new tab) en vous inscrivant pour accéder à l'API Mistral.
- Assurez-vous que votre environnement local dispose d'un accès à Internet pour communiquer avec les serveurs de l'API Mistral.
- Installez le plugin
llm-mistraldans votre environnement local. Cela peut impliquer de l'ajouter aux dépendances de votre projet en cas de projet de programmation. - Configurez votre projet ou votre outil pour utiliser votre clé API Mistral. Cela implique généralement de définir la clé dans un fichier de configuration ou en tant que variable d'environnement.
Créer des complétions de chat
Cet endpoint de l'API vous permet de générer des complétions de texte basées sur une requête. La requête nécessite de spécifier le modèle, les messages (requêtes), et divers paramètres pour contrôler le processus de génération, tels que la température, top_p et max_tokens.
Exemple de code Python pour des complétions de chat :
import requests
url = "https://api.mistral.ai/chat/completions"
payload = {
"model": "mistral-small-latest",
"messages": [{"role": "user", "content": "Comment commencer à utiliser Mistral AI ?"}],
"temperature": 0.7,
"top_p": 1,
"max_tokens": 512,
"stream": False,
"safe_prompt": False,
"random_seed": 1337
}
headers = {
"Authorization": "Bearer VOTRE_CLÉ_API",
"Content-Type": "application/json"
}
response = requests.post(url, json=payload, headers=headers)
if response.status_code == 200:
print(response.json())
else:
print("Erreur :", response.text)Créer des embeddings
L'endpoint de l'API des embeddings est utilisé pour convertir du texte en vecteurs multidimensionnels. Cela peut être utile pour des tâches telles que la recherche sémantique, le regroupement ou la recherche de textes similaires.
Exemple de code Python pour la création d'embeddings :
import requests
url = "https://api.mistral.ai/embeddings"
payload = {
"model": "mistral-embed",
"input": ["Bonjour", "monde"],
"encoding_format": "float"
}
headers = {
"Authorization": "Bearer VOTRE_CLÉ_API",
"Content-Type": "application/json"
}
response = requests.post(url, json=payload, headers=headers)
if response.status_code == 200:
print(response.json())
else:
print("Erreur :", response.text)Liste des modèles disponibles
Cet appel API est simple et vous permet de récupérer une liste de tous les modèles accessibles. Cela peut aider à sélectionner dynamiquement des modèles pour différentes tâches en fonction de leurs capacités ou de vos besoins.
Exemple de code Python pour la liste des modèles disponibles :
import requests
url = "https://api.mistral.ai/models"
headers = {
"Authorization": "Bearer VOTRE_CLÉ_API"
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
print(response.json())
else:
print("Erreur :", response.text)Ces exemples constituent une base pour interagir avec l'API de Mistral AI, permettant la création d'applications sophistiquées basées sur l'IA. N'oubliez pas de remplacer "VOTRE_CLÉ_API" par votre véritable clé API.
Ces étapes offrent un aperçu de base de l'intégration et de l'utilisation du modèle d'IA Mistral 7B localement sur un iPhone et via son API. Des adaptations peuvent être nécessaires en fonction des besoins spécifiques du projet ou des mises à jour de la plateforme.