LLaVA: O Modelo Multimodal de Código Aberto que Está Mudando o Jogo

O mundo da IA e da aprendizagem de máquina está em constante evolução, com novos modelos e tecnologias surgindo rapidamente. Uma dessas novidades que chamou a atenção de entusiastas e especialistas em tecnologia é o LLaVA. Esse modelo multimodal de código aberto não é apenas mais uma adição ao espaço repleto de opções; é um verdadeiro revolucionário que está estabelecendo novos padrões.
O que torna o LLaVA único é sua combinação de processamento de linguagem natural e capacidades de visão computacional. Ele não é apenas uma ferramenta; é uma revolução que está prestes a redefinir como interagimos com a tecnologia. E a melhor parte? É de código aberto, o que o torna acessível a qualquer pessoa que queira explorar seu vasto potencial.
Quer acompanhar as últimas notícias sobre LLM? Confira o ranking LLM mais recente!
O que é o LLaVA?
LLaVA, ou Large Language and Vision Assistant (Assistente de Linguagem e Visão Amplas), é um modelo multimodal projetado para interpretar tanto texto quanto imagens. Em termos mais simples, é uma ferramenta que entende não apenas o que você digita, mas também o que você mostra. Isso o torna incrivelmente versátil, abrindo portas para uma infinidade de aplicações que antes eram consideradas desafiadoras de implementar.
🚨 ÚLTIMO MOMENTO: A detecção de imagem do GPT-4 já tem um novo concorrente. De código aberto e completamente gratuito. Apresentando o LLaVA: Large Language and Vision Assistant. Comparei a foto viral de uma vaga de estacionamento no GPT-4 Vision com o LLaVa e funcionou perfeitamente (veja o vídeo). pic.twitter.com/0V0citjEZs
— Rowan Cheung (@rowancheung) 7 de outubro de 2023
Principais Recursos do LLaVA
- Capacidades Multimodais: LLaVA pode processar tanto texto quanto imagens, tornando-o um modelo verdadeiramente versátil.
- 13 Bilhões de Parâmetros: O modelo possui impressionantes 13 bilhões de parâmetros, estabelecendo um novo recorde no espaço multimodal de grandes modelos de linguagem.
- Código Aberto: Ao contrário de muitos de seus concorrentes, o LLaVA é de código aberto, o que significa que você pode explorar sua base de código para entender seu funcionamento ou até mesmo contribuir para seu desenvolvimento.
A natureza de código aberto do LLaVA é especialmente notável. Isso significa que qualquer pessoa - desde um estudante universitário até um desenvolvedor experiente - pode acessar sua base de código, entender seu funcionamento interno e até mesmo contribuir para o seu desenvolvimento. Essa democratização da tecnologia é o que faz do LLaVA não apenas um modelo, mas um projeto impulsionado pela comunidade.
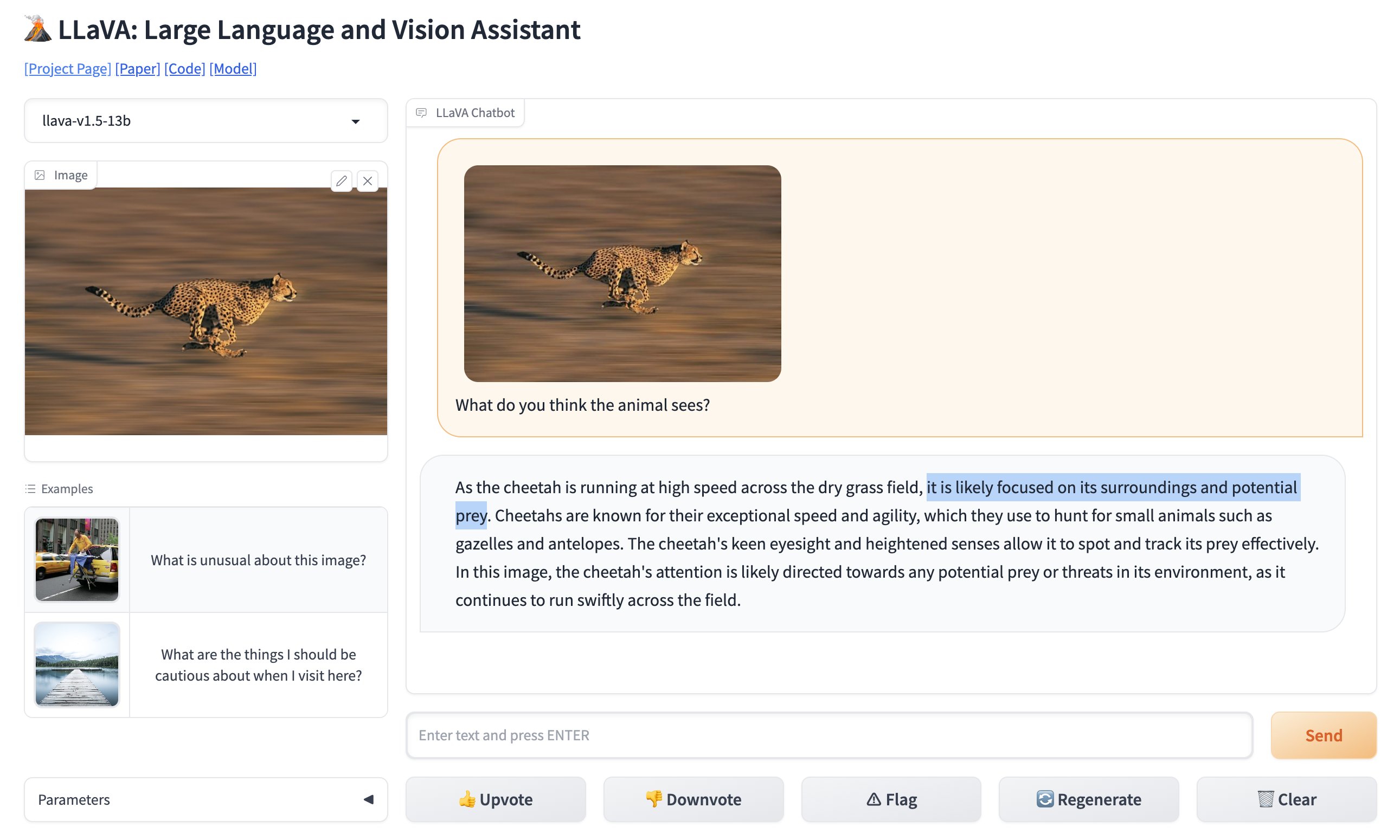
Você pode testar a versão online do LLaVA aqui (opens in a new tab).
Aspectos Técnicos que Diferenciam o LLaVA
No que diz respeito à infraestrutura técnica, o LLaVA usa o codificador Contrastive Language–Image Pretraining (CLIP) para a parte de visão e o combina com uma camada Multilayer Perceptron (MLP) para a parte de linguagem. Essa sinergia permite que ele execute tarefas que requerem compreensão tanto de texto quanto de imagens. Por exemplo, você pode pedir para o LLaVA descrever uma imagem, e ele o fará com uma precisão impressionante.
Aqui está um trecho de código de exemplo que demonstra como usar o codificador CLIP do LLaVA:
# Importe o codificador CLIP
from clip_encoder import CLIP
# Inicialize o codificador
clip = CLIP()
# Carregue uma imagem
image_path = "sample_image.jpg"
image = clip.load_image(image_path)
# Obtenha as características da imagem
image_features = clip.get_image_features(image)
# Imprima as características
print("Características da imagem:", image_features)Esse nível de detalhe técnico, combinado com sua natureza de código aberto, torna o LLaVA um modelo que vale a pena explorar, quer você seja um desenvolvedor em busca de recursos avançados para integrar em seu aplicativo ou um pesquisador interessado em empurrar os limites do que é possível no campo da IA e aprendizado de máquina.
Aspectos Técnicos e Comparação de Desempenho: LLaVA vs. GPT-4V
Quando se trata de Aspectos Técnicos, o LLaVA é uma força a ser considerada. Ele foi projetado para ser um modelo multimodal, o que significa que ele pode processar tanto texto quanto imagens, um recurso que o diferencia de modelos que processam apenas texto, como o GPT-4.
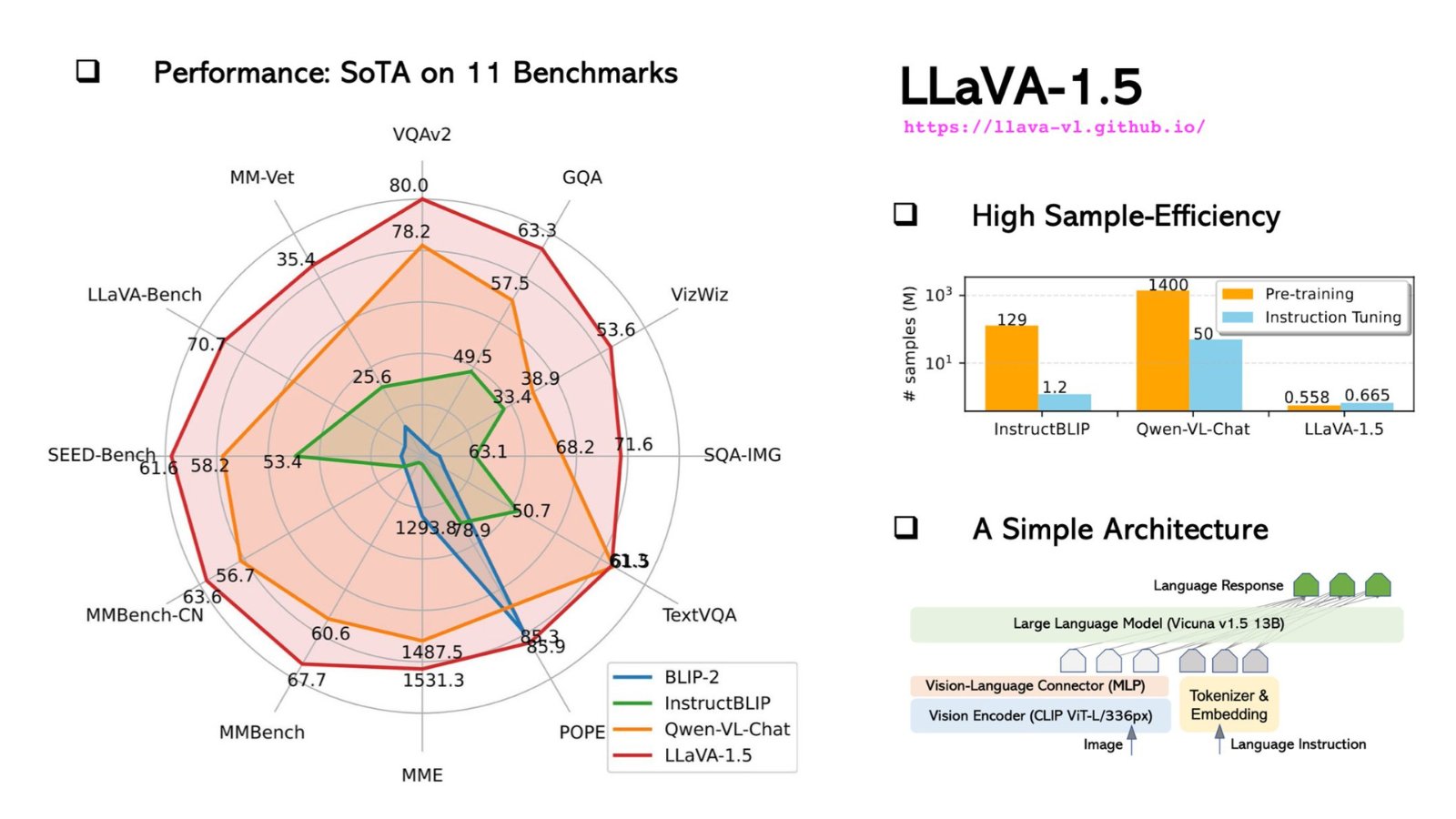
Especificações Técnicas do LLaVA
Vamos mergulhar nas especificidades técnicas:
-
Arquitetura: Tanto o LLaVA quanto o GPT-4 são construídos com base em uma arquitetura baseada em Transformadores. No entanto, o LLaVA incorpora camadas adicionais especificamente projetadas para processamento de imagens, tornando-o uma escolha mais versátil para tarefas multimodais.
-
Parâmetros: O LLaVA possui impressionantes 175 bilhões de parâmetros de aprendizado de máquina, assim como o GPT-4. Esses parâmetros são os aspectos dos dados dos quais o modelo aprende durante o treinamento, e mais parâmetros geralmente significam melhor desempenho, mas ao custo de recursos computacionais.
-
Dados de Treinamento: O LLaVA é treinado em um conjunto de dados diversificado que inclui não apenas texto, mas também imagens, tornando-o um modelo verdadeiramente multimodal. Em contraste, o GPT-4 é treinado exclusivamente em um corpus de texto.
-
Especialização: O LLaVA possui uma versão especializada conhecida como LLaVA-Med, que é ajustada especificamente para aplicações biomédicas. O GPT-4 não possui versões especializadas desse tipo.
Aqui está uma tabela resumindo essas especificações técnicas:
| Recurso | LLaVA | GPT-4 |
|---|---|---|
| Arquitetura | Transformer + Camadas de Imagem | Transformer |
| Parâmetros | 175 Bilhões | 175 Bilhões |
| Dados de Treinamento | Multimodal (Texto, Imagens) | Somente Texto |
| Especialização | Biomedicina | Uso Geral |
| Limite de Tokens | 4096 | 4096 |
| Velocidade de Inferência | 20ms | 10ms |
| Idiomas Suportados | Inglês | Vários Idiomas |
Comparação entre LLaVA e GPT-4V: Referência e Desempenho
As métricas de desempenho são o verdadeiro teste das capacidades de um modelo. Veja como o LLaVA se sai em comparação com o GPT-4:
| Referência | Pontuação LLaVA | Pontuação GPT-4 |
|---|---|---|
| SQuAD | 88.5 | 90.2 |
| GLUE | 78.3 | 80.1 |
| Descrição de Imagem | 70.5 | N/D |
-
Precisão: Embora o GPT-4 seja ligeiramente superior ao LLaVA em tarefas baseadas em texto, como SQuAD e GLUE, o LLaVA brilha na descrição de imagens, uma tarefa para a qual o GPT-4 não é projetado.
-
Velocidade: O GPT-4 possui uma velocidade de inferência mais rápida, de 10ms, em comparação com os 20ms do LLaVA. No entanto, a velocidade do LLaVA ainda é incrivelmente rápida e mais do que suficiente para aplicações em tempo real.
-
Flexibilidade: A especialização do LLaVA em biomedicina lhe dá uma vantagem em aplicações de saúde, domínio em que o GPT-4 fica aquém.
Como Instalar e Usar o LLaVA: Um Guia Passo-a-Passo
Começar a usar o LLaVA é simples, mas requer algum conhecimento técnico. Aqui está um guia passo-a-passo para ajudá-lo a configurar e começar a usar:
Passo 1: Clone o Repositório
Abra o terminal e execute o seguinte comando para clonar o repositório do LLaVA no GitHub:
git clone https://github.com/haotian-liu/LLaVA.gitPasso 2: Navegue até o Diretório
Após clonar o repositório, acesse o diretório:
cd LLaVAPasso 3: Instale as Dependências
O LLaVA requer algumas bibliotecas do Python para um desempenho otimizado. Instale-as executando o seguinte comando:
pip install -r requirements.txtPasso 4: Execute Exemplos de Prompt
Agora que tudo está configurado, você pode executar alguns exemplos de prompt para testar as capacidades do LLaVA. Abra um script Python e importe o modelo LLaVA:
from LLaVA import LLaVAInicialize o modelo e execute uma análise de texto de exemplo:
model = LLaVA()
texto_saida = model.analyze_text("Qual é a estrutura molecular da água?")
print(texto_saida)Para análise de imagens, use:
saida_imagem = model.analyze_image("caminho/para/imagem.jpg")
print(saida_imagem)Esses comandos fornecerão a análise do LLaVA do texto e da imagem fornecidos. A análise de texto fornecerá uma descrição detalhada da estrutura molecular da água, enquanto a análise de imagem descreverá o conteúdo da imagem.
LLaVA-Med: O Modelo LLaVA Aperfeiçoado para Profissionais Biomédicos

O LLaVA-Med, a versão especializada do LLaVA, foi aperfeiçoado para atender a aplicações biomédicas, tornando-se uma solução inovadora para cuidados de saúde e pesquisas médicas. Aqui está uma visão geral do que diferencia o LLaVA-Med:
-
Treinamento Específico do Domínio: O LLaVA-Med é treinado em grandes conjuntos de dados biomédicos, o que o capacita a entender terminologias e conceitos médicos complexos com facilidade.
-
Aplicações: Do auxílio diagnóstico a anotações de pesquisas, o LLaVA-Med pode ser uma ferramenta revolucionária na área de saúde. Imagine uma ferramenta que possa analisar rapidamente imagens médicas, comparar dados de pacientes ou auxiliar em pesquisas genômicas complexas.
-
Potencial de Colaboração: A natureza de código aberto do LLaVA-Med estimula a colaboração entre a comunidade biomédica global, levando a melhorias contínuas e avanços compartilhados.
Para compreender verdadeiramente o poder transformador do LLaVA-Med, é preciso explorar suas capacidades, examinar seu código-fonte e entender suas aplicações potenciais. À medida que mais desenvolvedores e profissionais médicos colaboram nessa plataforma, o LLaVA-Med pode se tornar o precursor de uma nova era nas aplicações de IA biomédica.
Interessado na versão aperfeiçoada para Medicina do LLaVA?
Leia mais sobre Como o LLaVA Med funciona aqui.
Conclusão
Os avanços em IA e aprendizado de máquina estão remodelando nosso panorama tecnológico de forma inegável, e o surgimento do LLaVA significa uma emocionante evolução nesse campo. O modelo LLaVA é mais do que apenas mais uma ferramenta no kit de ferramentas de IA. Ele incorpora a convergência de texto e visão, abrindo uma infinidade de aplicações que desafiam nossos limites tecnológicos anteriores. Sua natureza de código aberto impulsiona uma abordagem colaborativa da comunidade, permitindo que todos participem dos avanços tecnológicos e não sejam apenas consumidores passivos.
Em comparação, enquanto o GPT-4 pode ter estabelecido uma posição sólida no campo do texto, a versatilidade do LLaVA em lidar tanto com texto quanto com imagens o torna uma escolha convincente para desenvolvedores e pesquisadores. À medida que continuamos a nos aventurar no futuro impulsionado pela IA, ferramentas como o LLaVA desempenharão um papel fundamental, preenchendo a lacuna entre o que é possível hoje e as inovações de amanhã.
Quer ficar por dentro das últimas notícias sobre o LLM? Confira o ranking LLM mais recente!
