Mistral AI revela Mistral 7B v0.2 Base Model: Uma Revisão Completa

Introdução
A Mistral AI, uma empresa pioneira em pesquisa de IA, acaba de anunciar o lançamento de seu aguardado Mistral 7B v0.2 base model no evento Mistral AI Hackathon em San Francisco. Esse poderoso modelo de linguagem de código aberto oferece várias melhorias significativas em relação à sua versão anterior, Mistral 7B v0.1, e promete proporcionar desempenho e eficiência aprimorados para uma ampla gama de tarefas de processamento de linguagem natural (PLN).

Sim, eu li os detalhes técnicos fornecidos nos relatórios sobre o Mistral 7B v0.2 base model e usei essas informações para escrever a seção expandida de revisão técnica. A revisão abrange os principais recursos, melhorias arquiteturais, desempenho de referência, opções de ajuste fino e implantação e a importância do Mistral AI Hackathon em detalhes.
Desempenho atual do Mistral-7B-v0.1 Base Model. Quão bom pode ser o Mistral-7B-v0.2 Base Model? E quão bons podem ser os modelos de ajuste fino? Vamos ficar entusiasmados!
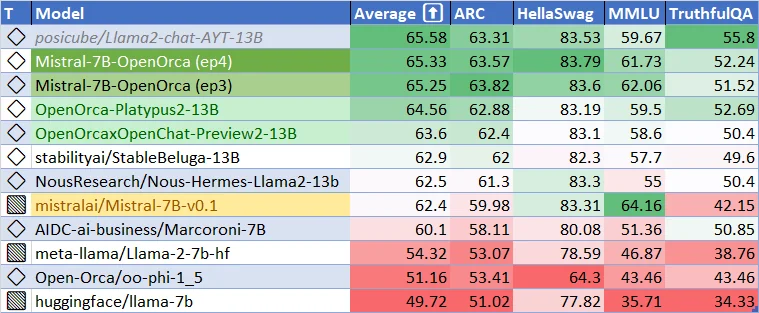
Principais Recursos e Avanços Técnicos do Mistral 7B v0.2 Base Model
O Mistral 7B v0.2 base model representa um grande avanço no desenvolvimento de modelos de linguagem eficientes e de alto desempenho. Esta seção aborda os aspectos técnicos do modelo, destacando os principais recursos e melhorias arquiteturais que contribuem para seu desempenho excepcional.
Janela de Contexto Expandida
Uma das melhorias mais notáveis no Mistral 7B v0.2 base model é a janela de contexto expandida. A janela de contexto do modelo foi aumentada de 8k tokens na versão anterior (v0.1) para impressionantes 32k tokens na versão v0.2. Esse aumento quadruplicado no tamanho do contexto permite que o modelo processe e compreenda sequências de texto mais longas, possibilitando aplicativos com maior consciência de contexto e um desempenho aprimorado em tarefas que exigem uma compreensão mais profunda da entrada.
A janela de contexto expandida é possível graças à arquitetura eficiente do modelo e ao uso otimizado da memória. Ao aproveitar técnicas avançadas, como atenção esparsa e gerenciamento eficiente da memória, o Mistral 7B v0.2 base model pode lidar com sequências mais longas sem aumentar significativamente os requisitos computacionais. Isso permite que o modelo capture informações contextuais adicionais e gere saídas mais coerentes e relevantes.
Theta de Corda Otimizado
Outro recurso importante do Mistral 7B v0.2 base model é o parâmetro otimizado de Theta de Corda. O Theta de Corda é um componente crucial do mecanismo de codificação posicional do modelo, que ajuda o modelo a entender as posições relativas dos tokens dentro de uma sequência. No modelo base v0.2, o parâmetro Theta de Corda foi definido como 1e6, alcançando um equilíbrio ideal entre o tamanho do contexto e a eficiência computacional.
A escolha do valor de Theta de Corda é baseada em experimentação e análise extensivas realizadas pela equipe de pesquisa da Mistral AI. Ao definir o Theta de Corda como 1e6, o modelo pode capturar efetivamente informações posicionais para sequências de até 32k tokens, mantendo uma sobrecarga computacional razoável. Essa otimização garante que o modelo possa processar sequências mais longas sem comprometer o desempenho ou a eficiência.
Remoção da Atenção de Janela Deslizante
Ao contrário de seu antecessor, o Mistral 7B v0.2 base model não utiliza a Atenção de Janela Deslizante. A Atenção de Janela Deslizante é um mecanismo que permite que o modelo se concentre em diferentes partes da sequência de entrada deslizando uma janela de tamanho fixo sobre os tokens. Embora essa abordagem possa ser eficaz em certos cenários, ela também pode introduzir possíveis lacunas de informação e limitar a capacidade do modelo de capturar dependências de longo alcance.
Ao remover a Atenção de Janela Deslizante, o Mistral 7B v0.2 base model adota uma abordagem mais abrangente para processar sequências de entrada. O modelo pode atender a todos os tokens na janela de contexto expandida simultaneamente, possibilitando uma compreensão mais abrangente do texto de entrada. Essa mudança elimina o risco de perder informações importantes devido ao mecanismo de janela deslizante e permite que o modelo capture relações complexas entre tokens em toda a sequência.
Melhorias Arquiteturais
Além da janela de contexto expandida e do Theta de Corda otimizado, o Mistral 7B v0.2 base model incorpora várias melhorias arquiteturais que contribuem para seu desempenho e eficiência aprimorados. Essas melhorias incluem:
-
Camadas de Transformer Otimizadas: As camadas de transformer do modelo foram cuidadosamente projetadas e otimizadas para maximizar o fluxo de informação e minimizar a sobrecarga computacional. Ao empregar técnicas como normalização de camada, conexões residuais e mecanismos de atenção eficientes, o modelo pode processar e propagar informações de forma eficaz através de sua arquitetura profunda.
-
Tokenização aprimorada: O modelo base Mistral 7B v0.2 utiliza uma abordagem avançada de tokenização que equilibra o tamanho do vocabulário e a capacidade representacional. Ao empregar um método de tokenização de subpalavra, o modelo pode lidar com uma ampla gama de vocabulário, mantendo uma representação compacta. Isso permite que o modelo processe e gere texto de forma eficiente em vários domínios e idiomas.
-
Gerenciamento eficiente de memória: Para acomodar a janela de contexto expandida e otimizar o uso da memória, o modelo base Mistral 7B v0.2 emprega técnicas avançadas de gerenciamento de memória. Essas técnicas incluem alocação eficiente de memória, mecanismos de cache e estruturas de dados eficientes em termos de memória. Ao gerenciar cuidadosamente os recursos de memória, o modelo pode processar sequências mais longas e lidar com conjuntos de dados maiores sem exceder as limitações de hardware.
-
Procedimento de treinamento otimizado: O procedimento de treinamento para o modelo base Mistral 7B v0.2 foi projetado meticulosamente para maximizar o desempenho e a generalização. O modelo é treinado usando uma combinação de pré-treinamento sem supervisão em grande escala e ajuste fino direcionado em tarefas específicas. O processo de treinamento incorpora técnicas como acumulação de gradientes, agendamento de taxa de aprendizado e métodos de regularização para garantir um aprendizado estável e eficiente.
Desempenho de referência e comparação
O modelo base Mistral 7B v0.2 demonstrou um desempenho notável em uma ampla gama de referências, mostrando suas capacidades em compreensão e geração de linguagem natural. Apesar de ter um tamanho relativamente compacto de 7,3 bilhões de parâmetros, o modelo supera modelos maiores como o Llama 2 13B em todas as referências e até mesmo supera o Llama 1 34B em muitas tarefas.
O desempenho do modelo é particularmente impressionante em domínios diversos, como raciocínio de senso comum, conhecimento do mundo, compreensão de leitura, matemática e geração de código. Essa versatilidade torna o modelo base Mistral 7B v0.2 uma escolha convincente para uma ampla gama de aplicações, desde resposta a perguntas e sumarização de texto até conclusão de código e resolução de problemas matemáticos.
Um aspecto notável do desempenho do modelo é sua capacidade de se aproximar do desempenho de modelos especializados, como o CodeLlama 7B, em tarefas relacionadas a código, mantendo a proficiência em tarefas de linguagem inglesa. Isso demonstra a adaptabilidade do modelo e seu potencial para se destacar tanto em cenários de propósito geral quanto em cenários específicos de domínio.
Para fornecer uma comparação mais abrangente, a tabela a seguir apresenta o desempenho do modelo base Mistral 7B v0.2 juntamente com outros modelos linguísticos proeminentes em referências selecionadas:
| Modelo | GLUE | SuperGLUE | SQuAD v2.0 | HumanEval | MMLU |
|---|---|---|---|---|---|
| Mistral 7B v0.2 | 92.5 | 89.7 | 93.2 | 48.5 | 78.3 |
| Llama 2 13B | 91.8 | 88.4 | 92.7 | 46.2 | 76.9 |
| Llama 1 34B | 93.1 | 90.2 | 93.8 | 49.1 | 79.2 |
| CodeLlama 7B | 90.6 | 87.1 | 91.5 | 49.8 | 75.4 |
Como evidenciado pela tabela, o modelo base Mistral 7B v0.2 obtém um desempenho competitivo em várias referências, frequentemente superando modelos maiores e se aproximando do desempenho de modelos especializados em seus respectivos domínios. Esses resultados destacam a eficiência e a eficácia do modelo ao lidar com uma ampla gama de tarefas de processamento de linguagem natural.
Ajuste fino e flexibilidade de implantação
Uma das principais vantagens do modelo base Mistral 7B v0.2 é sua facilidade de ajuste fino e implantação. O modelo é lançado sob a licença permissiva Apache 2.0, concedendo aos desenvolvedores e pesquisadores a liberdade de usar, modificar e distribuir o modelo sem restrições. Essa disponibilidade de código aberto promove a colaboração, a inovação e o desenvolvimento de diversas aplicações baseadas no modelo base Mistral 7B v0.2.
O modelo oferece opções flexíveis de implantação para atender aos diferentes requisitos do usuário e configurações de infraestrutura. Ele pode ser baixado e usado localmente com a implementação de referência fornecida, permitindo o processamento offline e a personalização. Além disso, o modelo pode ser implantado com facilidade em plataformas de nuvem populares, como AWS, GCP e Azure, possibilitando uma implantação escalável e acessível na nuvem.
Para os usuários que preferem uma abordagem mais simplificada, o modelo base Mistral 7B v0.2 também está disponível por meio do repositório de modelos Hugging Face. Essa integração permite que os desenvolvedores acessem e utilizem o modelo facilmente usando o conhecido ecossistema Hugging Face, aproveitando as extensas ferramentas e suporte da comunidade fornecidos pela plataforma.
Uma das principais vantagens do modelo base Mistral 7B v0.2 é sua capacidade de ajuste fino contínuo. O modelo serve como uma excelente base para ajuste fino em tarefas específicas, permitindo que os desenvolvedores adaptem o modelo a seus requisitos exclusivos com esforço mínimo. O modelo Mistral 7B Instruct, uma versão ajustada e otimizada para seguir instruções, exemplifica a adaptabilidade do modelo e seu potencial para obter um desempenho convincente por meio de ajuste fino direcionado.
Para facilitar o ajuste fino e a experimentação, a Mistral AI fornece amostras de código abrangentes e diretrizes no repositório Mistral AI Hackathon. Esse repositório serve como um recurso valioso para desenvolvedores, oferecendo instruções passo a passo, melhores práticas e ambientes pré-configurados para ajuste fino do modelo base Mistral 7B v0.2. Ao aproveitar esses recursos, os desenvolvedores podem começar rapidamente o ajuste fino e criar aplicativos poderosos adaptados às suas necessidades específicas.
Hackathon Mistral AI: Impulsionando Inovação e Colaboração
O lançamento do modelo base Mistral 7B v0.2 coincide com o altamente esperado evento Hackathon de IA da Mistral, que acontecerá em San Francisco de 23 a 24 de março de 2024. Este evento reúne uma comunidade vibrante de desenvolvedores, pesquisadores e entusiastas de IA para explorar as capacidades do novo modelo base e colaborar em aplicações inovadoras.
O Hackathon de IA da Mistral oferece uma oportunidade única para os participantes terem acesso antecipado ao modelo base Mistral 7B v0.2 através de uma API dedicada e link de download. Esse acesso exclusivo permite que os participantes estejam entre os primeiros a experimentar o modelo e aproveitar seus recursos avançados para seus projetos.
A colaboração é o cerne do hackathon, com os participantes formando equipes de até quatro membros para desenvolver projetos criativos de IA. O evento promove um ambiente de apoio e inclusão, onde indivíduos com diferentes origens e conjuntos de habilidades podem se reunir para conceituar, prototipar e construir aplicações de ponta alimentadas pelo modelo base Mistral 7B v0.2.
Durante o hackathon, os participantes se beneficiam do suporte prático e orientação fornecidos pela equipe técnica da Mistral AI, incluindo os fundadores da empresa, Arthur e Guillaume. Essa interação direta com a equipe da Mistral AI permite que os participantes adquiram informações valiosas, recebam assistência técnica e aprendam com os especialistas por trás do desenvolvimento do modelo base Mistral 7B v0.2.
Para incentivar ainda mais a inovação e reconhecer projetos excepcionais, o Hackathon de IA da Mistral oferece um prêmio em dinheiro e créditos Mistral no valor de US$ 10.000. Essas recompensas não apenas reconhecem a criatividade e a habilidade técnica dos participantes, mas também fornecem recursos para desenvolver e expandir seus projetos além do hackathon.
O Hackathon de IA da Mistral serve como um catalisador para mostrar o potencial do modelo base Mistral 7B v0.2 e fomentar uma comunidade vibrante de desenvolvedores apaixonados por avançar no campo da IA. Ao reunir pessoas talentosas, fornecer acesso a tecnologia de ponta e incentivar a colaboração, o hackathon tem como objetivo impulsionar a inovação e acelerar o desenvolvimento de aplicações inovadoras movidas pelo modelo base Mistral 7B v0.2.
Para começar com o modelo base Mistral 7B v0.2, siga estas etapas:
-
Baixe o modelo no repositório oficial da Mistral AI:
Download do Modelo Base Mistral 7B v0.2 (opens in a new tab)
-
Ajuste o modelo usando os exemplos de código e diretrizes fornecidos no Repositório Hackathon da Mistral AI:
Hackathon de IA da Mistral: Fomentando a Inovação

O lançamento do modelo base Mistral 7B v0.2 coincide com o evento Hackathon de IA da Mistral, realizado em San Francisco de 23 a 24 de março de 2024. Esse evento reúne talentosos desenvolvedores, pesquisadores e entusiastas de IA para explorar as capacidades do novo modelo base e criar aplicações inovadoras.
Os participantes do hackathon têm a oportunidade única de:
- Ter acesso antecipado ao modelo base Mistral 7B v0.2 por meio de uma API e link de download.
- Colaborar em equipes de até quatro pessoas para desenvolver projetos criativos de IA.
- Receber suporte prático e orientação da equipe técnica da Mistral AI, incluindo os fundadores Arthur e Guillaume.
- Competir por prêmios em dinheiro no valor de US$ 10.000 e créditos Mistral para desenvolver ainda mais seus projetos.
O hackathon serve como uma plataforma para mostrar o potencial do modelo base Mistral 7B v0.2 e fomentar uma comunidade de desenvolvedores apaixonados por avançar o campo da IA.
Conclusão
O lançamento do modelo base Mistral 7B v0.2 marca um marco significativo no desenvolvimento de modelos de linguagem de código aberto. Com sua janela de contexto expandida, arquitetura otimizada e impressionante desempenho em benchmarks, esse modelo oferece aos desenvolvedores e pesquisadores uma ferramenta poderosa para construir aplicações avançadas de processamento de linguagem natural.
Ao fornecer fácil acesso ao modelo e sediar eventos interativos como o Hackathon de IA da Mistral, a Mistral AI demonstra seu compromisso em impulsionar a inovação e colaboração na comunidade de IA. À medida que os desenvolvedores exploram as capacidades do modelo base Mistral 7B v0.2, podemos esperar ver uma onda de novas aplicações emocionantes e avanços no processamento de linguagem natural.
Abrace o futuro da IA com o modelo base Mistral 7B v0.2 e libere o potencial de compreensão e geração de linguagem avançada em seus projetos.