Introdução ao Jamba, o Modelo Revolucionário SSM-Transformer

A AI21 Labs tem o orgulho de apresentar o Jamba, o primeiro modelo para produção em série baseado na revolucionária arquitetura Mamba. Ao integrar perfeitamente a tecnologia Mamba Structured State Space (SSM) com elementos da arquitetura Transformer tradicional, o Jamba supera as limitações dos modelos SSM puros, oferecendo um desempenho e eficiência excepcionais.
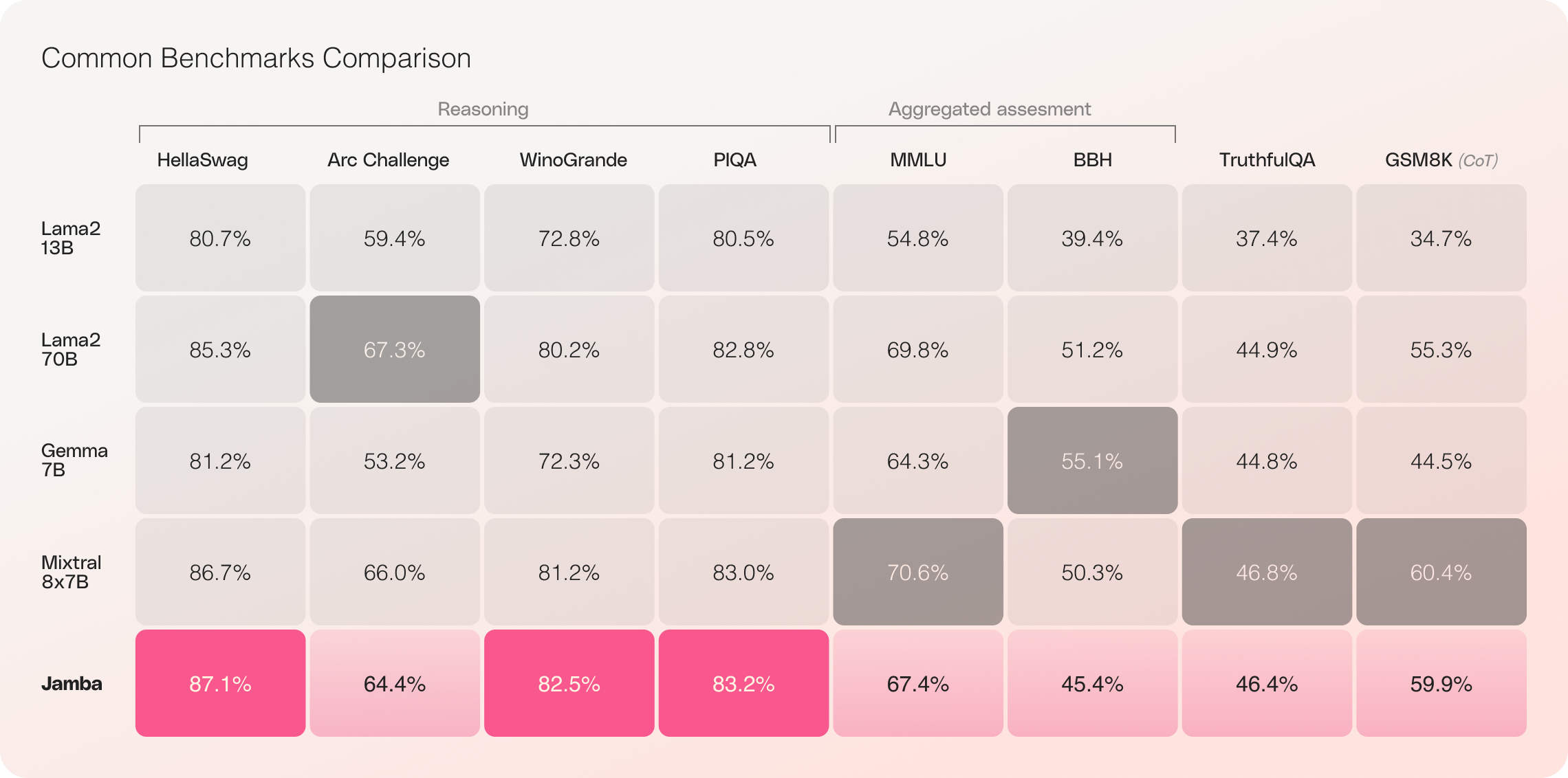
Com sua impressionante janela de contexto de 256K e notáveis ganhos de taxa de transferência, o Jamba está prestes a remodelar o cenário de IA, abrindo novas possibilidades para pesquisadores, desenvolvedores e empresas. O Jamba já demonstrou resultados excepcionais em uma ampla variedade de benchmarks, equiparando ou superando outros modelos de ponta em sua classe de tamanho.
TLDR: O Jamba não possui mecanismos de moderação de segurança e limites de proteção, e usa a Licença de Código Aberto Apache-2.0.

Principais Características do Jamba
- Primeiro modelo para produção em série baseado no Mamba: O Jamba pioneiriza o uso da arquitetura híbrida SSM-Transformer em escala e qualidade para produção em série.
- Taxa de transferência incomparável: O Jamba alcança uma taxa de transferência 3 vezes maior em contextos longos em comparação com o Mixtral 8x7B, estabelecendo novos padrões de eficiência.
- Janela de contexto enorme: Com uma janela de contexto de 256K, o Jamba democratiza o acesso às capacidades abrangentes de manuseio de contexto.
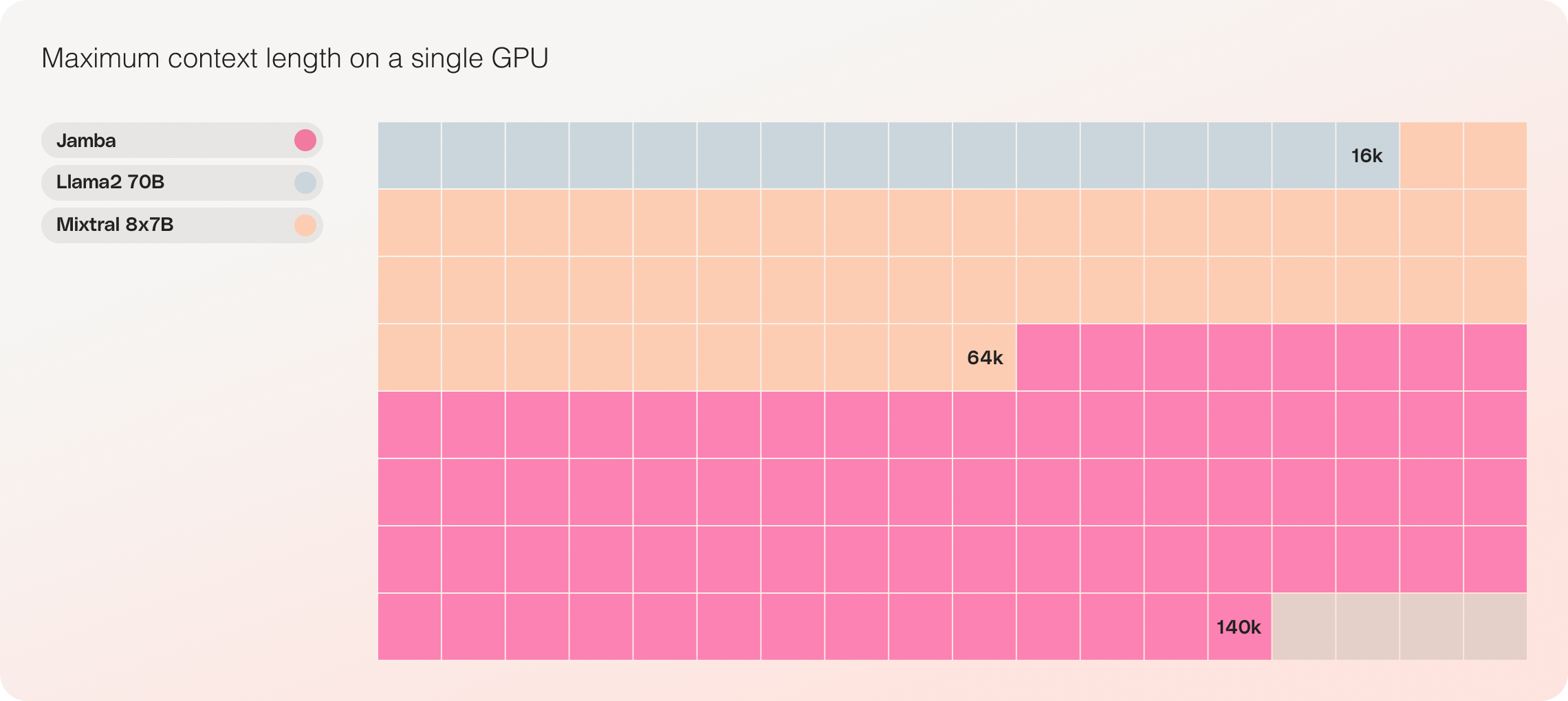
- Compatibilidade com GPU única: O Jamba é o único modelo em sua classe de tamanho que pode acomodar até 140K de contexto em uma única GPU, tornando-o mais acessível para implantação e experimentação.
- Disponibilidade de código aberto: Lançado com pesos abertos sob a licença Apache 2.0, o Jamba convida a otimizações e descobertas adicionais da comunidade de IA.
- Integração futura com o catálogo de API da NVIDIA: O Jamba em breve estará acessível no catálogo de API da NVIDIA como um microserviço de inferência NVIDIA NIM, permitindo que desenvolvedores de aplicativos corporativos o implantem usando a plataforma de software NVIDIA AI Enterprise.
Jamba: Combinando o Melhor das Arquiteturas Mamba e Transformer
O Jamba representa um marco significativo na inovação LLM ao incorporar com sucesso o Mamba juntamente com a arquitetura Transformer e dimensionar o modelo híbrido SSM-Transformer para qualidade de produção em série.
Os LLMs tradicionais baseados em transformers enfrentam dois grandes desafios:
- Grande consumo de memória: A memória consumida pelo Transformer aumenta com o comprimento do contexto, dificultando a execução de janelas de contexto longas ou vários lotes paralelos sem recursos de hardware extensivos.
- Inferência lenta em contextos longos: O mecanismo de atenção nos Transformers escala de forma quadrática com o comprimento da sequência, diminuindo a taxa de transferência, já que cada token depende de toda a sequência anterior.
O Mamba, proposto por pesquisadores das universidades Carnegie Mellon e Princeton, aborda essas deficiências. No entanto, sem atenção sobre todo o contexto, o Mamba tem dificuldade em igualar a qualidade de saída dos melhores modelos existentes, especialmente em tarefas relacionadas à memória.

Jamba vs Mamba vs Transformer
A arquitetura híbrida do Jamba, composta por camadas Transformer, Mamba e Mixture-of-Experts (MoE), otimiza simultaneamente a memória, a taxa de transferência e o desempenho. As camadas MoE permitem que o Jamba utilize apenas 12B de seus 52B de parâmetros durante a inferência, tornando esses parâmetros ativos mais eficientes do que um modelo composto apenas por Transformers de tamanho equivalente.
Dimensionando a Arquitetura Híbrida do Jamba
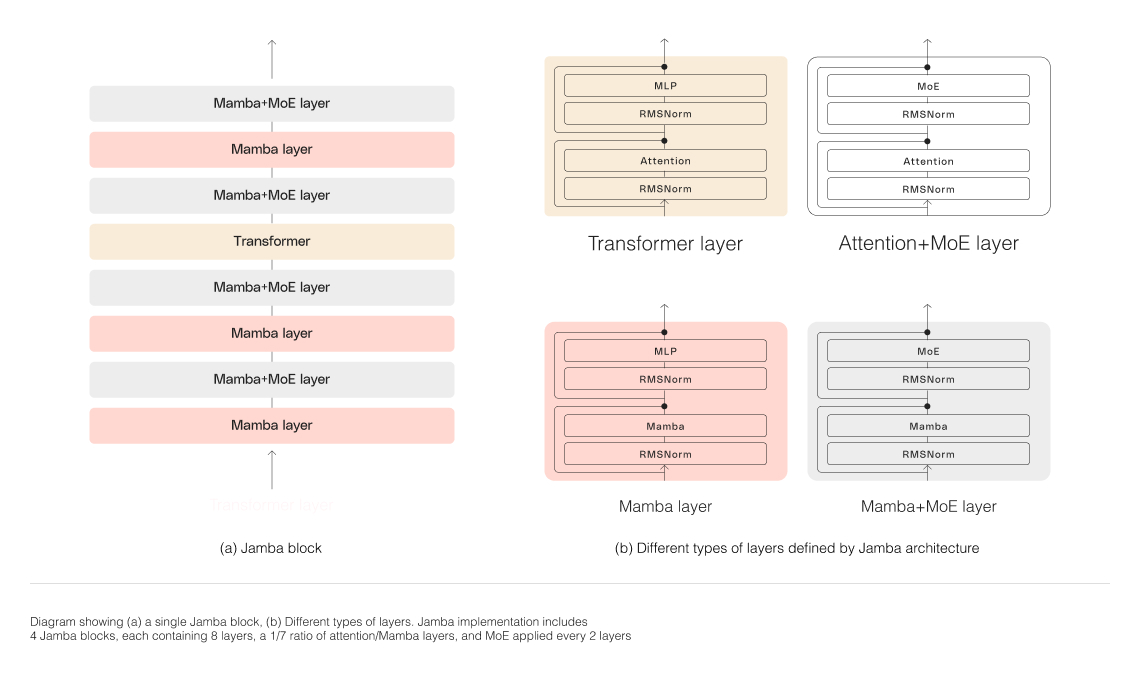
Para dimensionar com sucesso a estrutura híbrida do Jamba, a AI21 Labs implementou várias inovações arquiteturais principais:
-
Abordagem de blocos e camadas: A arquitetura do Jamba possui uma abordagem de blocos e camadas, permitindo a integração perfeita das arquiteturas Transformer e Mamba. Cada bloco do Jamba contém uma camada de atenção ou uma camada Mamba, seguida por um perceptron de várias camadas (MLP), resultando em uma proporção geral de uma camada Transformer a cada oito camadas.
-
Utilização do Mixture-of-Experts (MoE): Ao usar camadas MoE, o Jamba aumenta o número total de parâmetros do modelo enquanto reduz o número de parâmetros ativos usados durante a inferência. Isso resulta em uma capacidade de modelo maior sem um aumento correspondente nos requisitos computacionais. O número de camadas e especialistas MoE foi otimizado para maximizar a qualidade e a taxa de transferência do modelo em uma única GPU de 80 GB, deixando memória suficiente para cargas de trabalho de inferência comuns.
O Impressionante Desempenho e Eficiência do Jamba
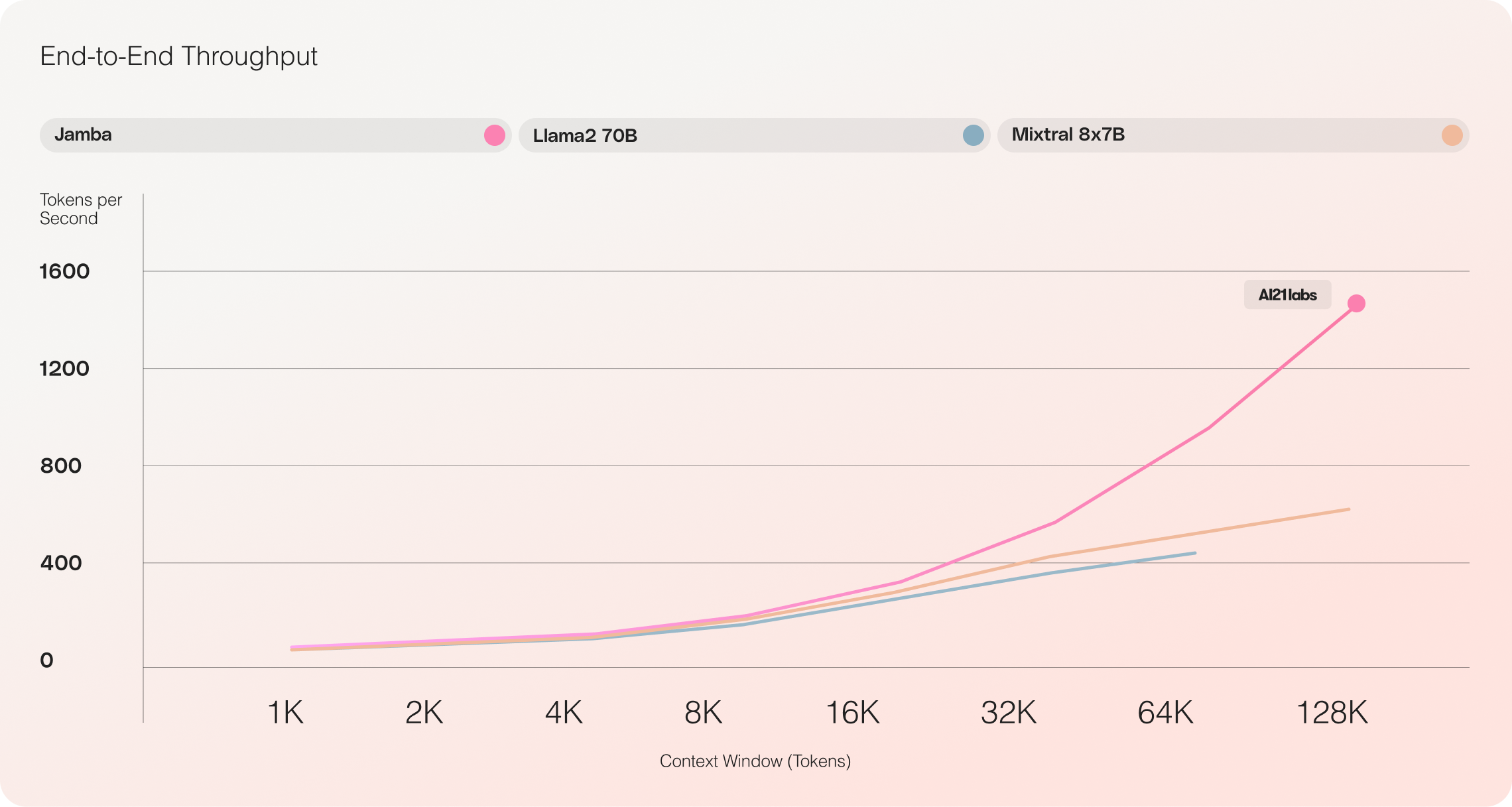
Jamba vs Llama 70B vs Mixtral 8x7B
Avaliações iniciais do Jamba têm apresentado resultados impressionantes em métricas-chave, como taxa de transferência e eficiência. Espera-se que esses benchmarks melhorem ainda mais à medida que a comunidade continua experimentando e otimizando essa tecnologia inovadora.
- Eficiência: O Jamba oferece 3 vezes mais rendimento em contextos longos, tornando-o mais eficiente do que modelos comparáveis baseados em Transformer, como o Mixtral 8x7B.
- Relação custo-eficácia: Com a capacidade de acomodar 140K de contexto em uma única GPU, o Jamba possibilita oportunidades de implementação e experimentação mais acessíveis em comparação a outros modelos de código aberto de tamanho similar.
Otimizações futuras, como paralelismo aprimorado de MoE e implementações mais rápidas do Mamba, têm o objetivo de impulsionar ainda mais esses ganhos já impressionantes.
Comece a Construir com o Jamba
O Jamba agora está disponível no Hugging Face, lançado com pesos abertos sob a licença Apache 2.0. Como modelo base, o Jamba destina-se a servir como base para ajuste fino, treinamento e desenvolvimento de soluções personalizadas. É essencial adicionar proteções adequadas para o uso responsável e seguro.
Uma versão instruída do Jamba em breve estará disponível em beta por meio da Plataforma AI21. Para compartilhar seus projetos, fornecer feedback ou fazer perguntas, participe da conversa no Discord.
Conclusão
A introdução do Jamba marca um salto significativo na tecnologia de IA, demonstrando o imenso potencial das arquiteturas híbridas SSM-Transformer. Ao combinar as qualidades do Mamba e do Transformer com otimização de eficiência e desempenho, o Jamba estabelece novos padrões para modelos de IA em sua classe de tamanho.
Com seu impressionante controle de contexto, rendimento e relação custo-eficácia, o Jamba está pronto para revolucionar o panorama da IA, permitindo que pesquisadores, desenvolvedores e empresas ampliem os limites do que é possível. À medida que a comunidade continua a explorar e a construir sobre as inovações do Jamba, podemos antecipar uma nova onda de aplicações de IA que moldarão o futuro da inteligência artificial.