LlamaIndex: a alternativa LangChain que escalona LLMs

Introdução: O que é o LlamaIndex?
LlamaIndex é uma ferramenta de indexação de alto desempenho especificamente projetada para ampliar as capacidades de Large Language Models (LLMs). Não é apenas um otimizador de consulta; é uma estrutura abrangente que oferece recursos avançados como síntese de resposta, composabilidade e armazenamento eficiente de dados. Se você lida com consultas complexas e requer respostas de alta qualidade e contextualmente relevantes, o LlamaIndex é a solução ideal.
Neste artigo, faremos uma imersão técnica no LlamaIndex, explorando seus principais componentes, recursos avançados e como implementá-lo efetivamente em seus projetos. Também o compararemos com ferramentas similares como o LangChain para fornecer uma compreensão completa de suas capacidades.
Quer ficar por dentro das últimas notícias do LLM? Confira o leaderboard mais recente aqui!
Afinal, o que é o LlamaIndex?
O LlamaIndex é uma ferramenta especializada projetada para ampliar as funcionalidades de Large Language Models (LLMs). Ele serve como uma solução abrangente para interações específicas de LLM, sendo especialmente eficiente em cenários que exigem consultas precisas e respostas de alta qualidade.
Consulta: Otimizado para recuperação rápida de dados, tornando-o ideal para aplicações sensíveis à velocidade. Síntese de Resposta: Simplificado para produzir respostas concisas e contextualmente relevantes. Composabilidade: Permite a construção de consultas e fluxos de trabalho complexos usando componentes modulares e reutilizáveis.
Agora, vamos entrar nos detalhes sobre o LlamaIndex, vamos lá?
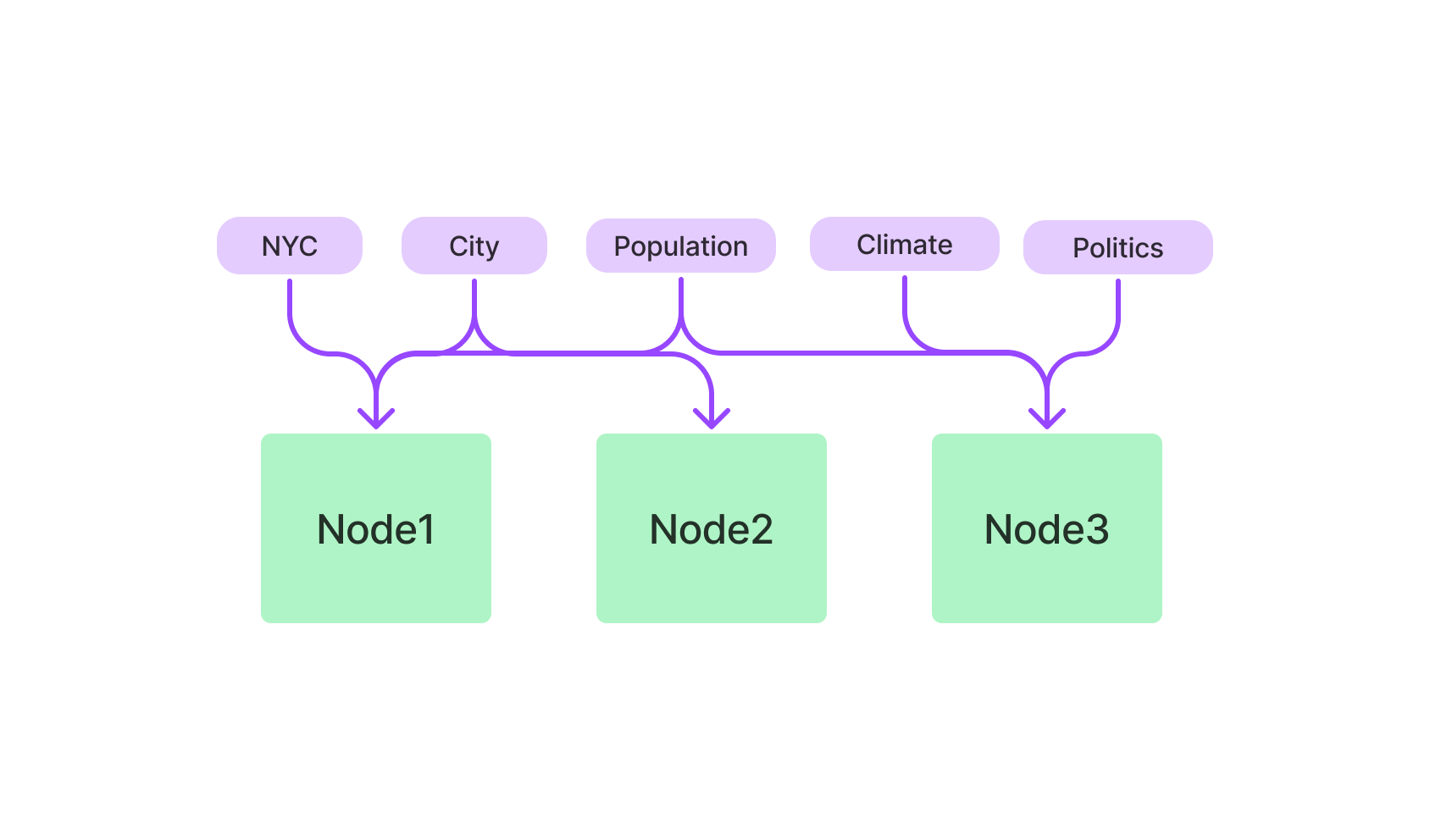
O que são Índices no LlamaIndex?
Os índices são o cerne do LlamaIndex, sendo as estruturas de dados que mantêm as informações a serem consultadas. O LlamaIndex oferece vários tipos de índices, cada um otimizado para tarefas específicas.

Tipos de Índices no LlamaIndex
- Vector Store Index: Utiliza algoritmos k-NN e é otimizado para dados de alta dimensão.
- Índice Baseado em Palavras-chave: Utiliza TF-IDF para consultas baseadas em texto.
- Índice Híbrido: Uma combinação de índices Vetorizados e Baseado em Palavras-chave, oferecendo uma abordagem balanceada.
Vector Store Index no LlamaIndex
O Vector Store Index é a escolha ideal para qualquer coisa relacionada a dados de alta dimensão. É particularmente útil para aplicações de aprendizado de máquina onde você lida com pontos de dados complexos.
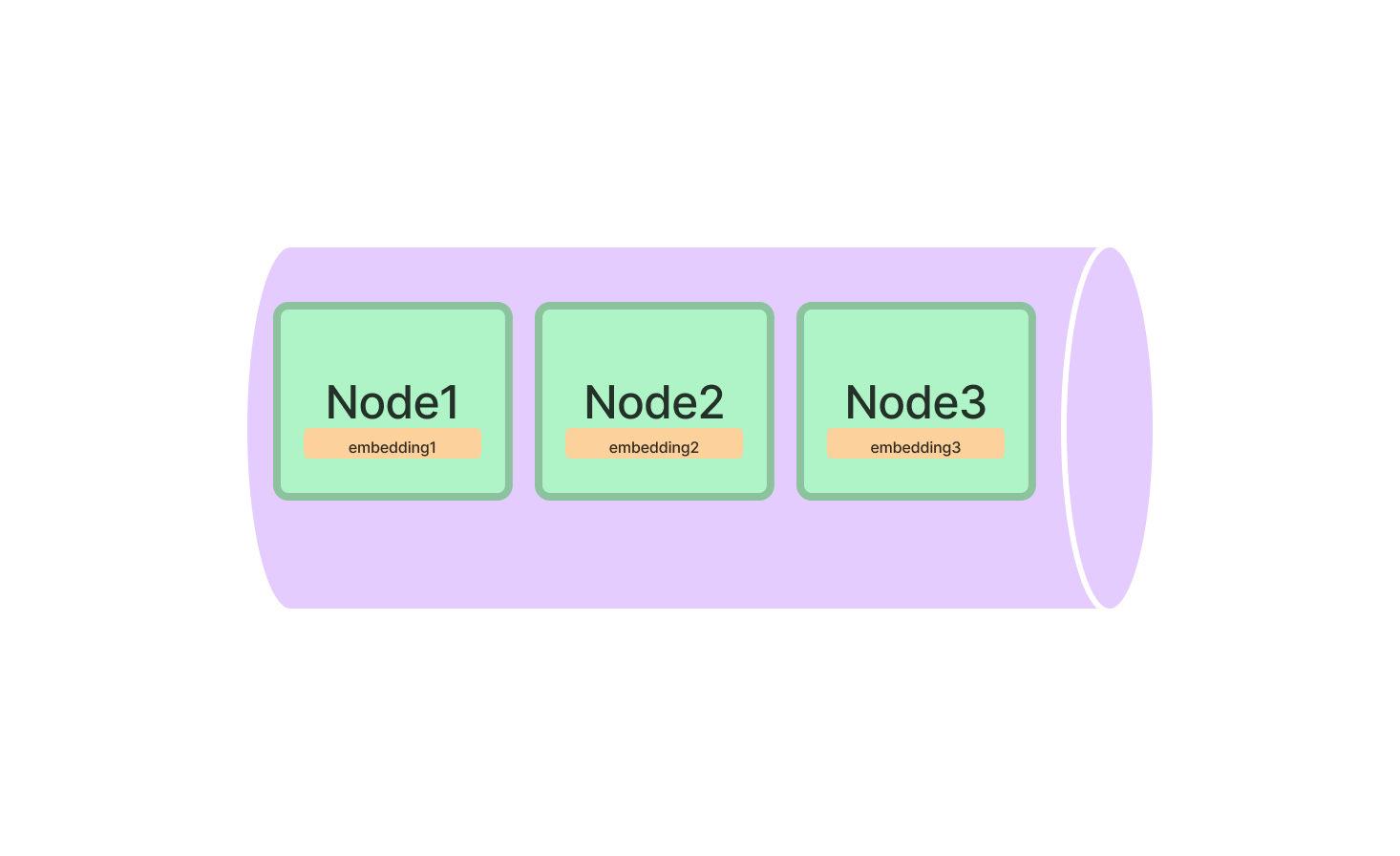
Para começar, você precisará importar a classe VectorStoreIndex do pacote LlamaIndex. Uma vez importada, inicialize-a especificando as dimensões de seus vetores.
from llamaindex import VectorStoreIndex
vector_index = VectorStoreIndex(dimensions=300)Isso configura um Vector Store Index com 300 dimensões, pronto para lidar com seus dados de alta dimensão. Agora, você pode adicionar vetores ao índice e executar consultas para encontrar os vetores mais semelhantes.
# Adicionando um vetor
vector_index.add_vector(vector_id="vector_1", vector_data=[0.1, 0.2, 0.3, ...])
# Executando uma consulta
query_result = vector_index.query(vector=[0.1, 0.2, 0.3, ...], top_k=5)Índice Baseado em Palavras-chave no LlamaIndex
Se você prefere consultas baseadas em texto, o Índice Baseado em Palavras-chave é seu aliado. Ele utiliza o algoritmo TF-IDF para filtrar dados textuais, sendo ideal para consultas em linguagem natural.
Comece importando a classe KeywordBasedIndex do pacote LlamaIndex. Após isso, inicialize-o.
from llamaindex import KeywordBasedIndex
text_index = KeywordBasedIndex()Agora você pode adicionar dados de texto a este índice e executar consultas baseadas em texto.
# Adicionando dados de texto
text_index.add_text(text_id="document_1", text_data="Este é um documento de exemplo.")
# Executando uma consulta
query_result = text_index.query(text="exemplo", top_k=3)Começando rápido com LlamaIndex: Guia passo a passo
Instalar e inicializar o LlamaIndex é apenas o começo. Para aproveitar verdadeiramente seu poder, você precisa saber como usá-lo efetivamente.
Instalando o LlamaIndex
Primeiro, vamos colocá-lo em sua máquina. Abra o terminal e execute:
pip install llamaindexOu, se você estiver usando o conda:
conda install -c conda-forge llamaindexInicializando o LlamaIndex
Após a instalação ser concluída, você precisará inicializar o LlamaIndex em seu ambiente Python. Aqui é onde você prepara o terreno para toda a mágica que está por vir.
from llamaindex import LlamaIndex
index = LlamaIndex(index_type="vector_store", dimensions=300)Aqui, index_type especifica o tipo de índice que você está configurando, e dimensions é para especificar o tamanho do Vector Store Index.
Como fazer consultas com o Vector Store Index do LlamaIndex
Após configurar o LlamaIndex com sucesso, você está pronto para explorar suas poderosas capacidades de consulta. O Vector Store Index é projetado para lidar com dados complexos e de alta dimensão, tornando-o uma ferramenta indispensável para aprendizado de máquina, análise de dados e outras tarefas computacionais.
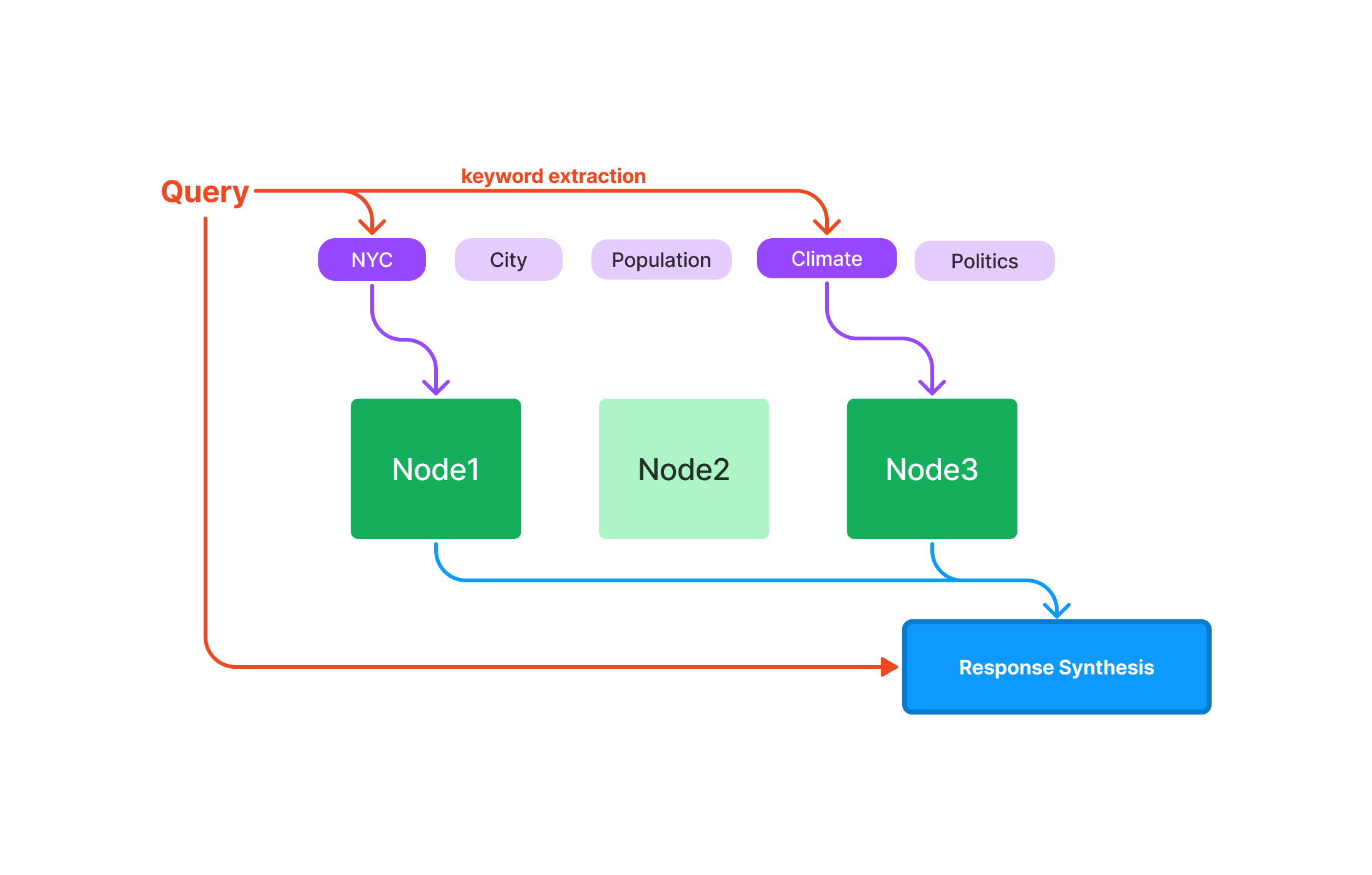
Faça sua primeira consulta no LlamaIndex
Antes de mergulhar no código, é crucial entender os elementos básicos de uma consulta no LlamaIndex:
-
Vetor de Consulta: Este é o vetor que você está interessado em encontrar semelhanças dentro do seu conjunto de dados. Ele deve estar no mesmo espaço dimensional dos vetores que você indexou.
-
Parâmetro
top_k: Este parâmetro especifica o número de vetores mais próximos do vetor de consulta que você deseja recuperar. O "k" emtop_krepresenta o número de vizinhos mais próximos de seu interesse.
Aqui está uma explicação de como fazer sua primeira consulta:
-
Inicializar seu Índice: Certifique-se de que seu índice seja carregado e esteja pronto para consulta.
-
Especificar o Vetor de Consulta: Crie uma lista ou matriz que contenha os elementos do seu vetor de consulta.
-
Definir o Parâmetro
top_k: Decida quantos dos vetores mais próximos você deseja recuperar. -
Executar a Consulta: Use o método
querypara realizar a pesquisa.
Aqui está um trecho de código Python de exemplo para ilustrar essas etapas:
# Inicialize seu índice (assumindo que ele seja chamado 'index')
# ...
# Defina o vetor de consulta
query_vector = [0.2, 0.4, 0.1, ...]
# Defina o número de vetores mais próximos a serem recuperados
top_k = 5
# Execute a consulta
query_result = index.query(vector=query_vector, top_k=top_k)Aperfeiçoando Suas Consultas no LlamaIndex
Por que o Aperfeiçoamento é Importante?
Aperfeiçoar suas consultas permite adaptar o processo de busca aos requisitos específicos do seu projeto. Seja lidando com texto, imagens ou qualquer outro tipo de dado, o aperfeiçoamento pode melhorar significativamente a precisão e eficiência de suas consultas.
Parâmetros Principais para Aperfeiçoamento:
-
Métrica de Distância: O LlamaIndex permite escolher entre diferentes métricas de distância, como 'euclidiana' e 'cosseno'.
-
Distância Euclidiana: Esta é a distância "ordinária" em linha reta entre dois pontos em um espaço euclidiano. Use esta métrica quando a magnitude dos vetores for importante.
-
Similaridade de Cosseno: Esta métrica mede o cosseno do ângulo entre dois vetores. Use quando você estiver mais interessado na direção dos vetores do que em sua magnitude.
-
-
Tamanho do Lote: Se você estiver lidando com um conjunto de dados grande ou precisar fazer várias consultas, definir um tamanho de lote pode acelerar o processo, consultando vários vetores de uma só vez.
Guia Passo a Passo para Aperfeiçoamento:
Veja como aperfeiçoar sua consulta:
-
Escolha a Métrica de Distância: Decida entre 'euclidiana' e 'cosseno' com base em suas necessidades específicas.
-
Defina o Tamanho do Lote: Determine o número de vetores que você deseja processar em um único lote.
-
Execute a Consulta Aperfeiçoada: Use o método
querynovamente, desta vez incluindo os parâmetros adicionais.
Aqui está um trecho de código Python para demonstrar:
# Defina o vetor de consulta
query_vector = [0.2, 0.4, 0.1, ...]
# Defina o número de vetores mais próximos a serem recuperados
top_k = 5
# Escolha a métrica de distância
distance_metric = 'euclidiana'
# Defina o tamanho do lote para consultas múltiplas
batch_size = 100
# Execute a consulta aperfeiçoada
query_result = index.query(vector=query_vector, top_k=top_k, metric=distance_metric, batch_size=batch_size)Dominando essas técnicas de aperfeiçoamento, você pode tornar suas consultas no LlamaIndex mais direcionadas e eficientes, obtendo assim o máximo valor de seus dados de alta dimensão.
O que Você Pode Fazer com o LlamaIndex?
Você já domina o básico, mas o que você realmente pode construir com o LlamaIndex? As possibilidades são vastas, especialmente quando você considera sua compatibilidade com Modelos de Linguagem em Grande Escala (LLMs).
LlamaIndex para Mecanismos de Busca Avançados
Um dos usos mais cativantes do LlamaIndex está no campo de mecanismos de busca avançados. Imagine um mecanismo de busca que não apenas recupera documentos relevantes, mas também entende o contexto de sua consulta. Com o LlamaIndex, você pode construir exatamente isso.
Aqui está um exemplo rápido para demonstrar como você pode configurar um mecanismo de busca básico usando o Índice Baseado em Palavras-Chave do LlamaIndex.
# Inicialize o Índice Baseado em Palavras-Chave
from llamaindex import KeywordBasedIndex
search_index = KeywordBasedIndex()
# Adicione alguns documentos
search_index.add_text("doc1", "Llamas são incríveis.")
search_index.add_text("doc2", "Eu adoro programação.")
# Execute uma consulta
results = search_index.query("Llamas", top_k=2)LlamaIndex para Sistemas de Recomendação
Outra aplicação fascinante está na construção de sistemas de recomendação. Seja sugerindo produtos, artigos ou até mesmo músicas semelhantes, o Índice de Armazenamento de Vetores do LlamaIndex pode ser um diferencial.
Aqui está como você pode configurar um sistema básico de recomendação:
# Inicialize o Índice de Armazenamento de Vetores
from llamaindex import VectorStoreIndex
rec_index = VectorStoreIndex(dimensions=50)
# Adicione alguns vetores de produtos
rec_index.add_vector("product1", [0.1, 0.2, 0.3, ...])
rec_index.add_vector("product2", [0.4, 0.5, 0.6, ...])
# Execute uma consulta para encontrar produtos semelhantes
similar_products = rec_index.query(vector=[0.1, 0.2, 0.3, ...], top_k=5)LlamaIndex vs. LangChain
Quando se trata de desenvolver aplicativos baseados em Modelos de Linguagem em Grande Escala (LLMs), a escolha do framework pode impactar significativamente o sucesso do projeto. Dois frameworks que ganharam atenção nesse espaço são o LlamaIndex e o LangChain. Ambos têm recursos e vantagens únicos, mas atendem a necessidades diferentes e são otimizados para tarefas específicas. Nesta seção, vamos analisar os detalhes técnicos e fornecer trechos de código de exemplo para ajudar você a entender as principais diferenças entre esses dois frameworks, especialmente no contexto de Geração com Recuperação Aprimorada (RAG) para o desenvolvimento de chatbots.
Recursos Principais e Capacidades Técnicas
LangChain
-
Framework de Uso Geral: O LangChain foi projetado para ser uma ferramenta versátil para uma ampla variedade de aplicações. Ele não apenas permite o carregamento, processamento e indexação de dados, mas também fornece funcionalidades para interagir com LLMs.
Trecho de Código de Exemplo:
const res = await llm.call("Me conte uma piada"); -
Flexibilidade: Uma das principais características do LangChain é a sua flexibilidade. Ele permite que os usuários personalizem o comportamento de suas aplicações de forma abrangente.
-
APIs de Alto Nível: O LangChain abstrai a maioria das complexidades envolvidas no trabalho com LLMs, oferecendo APIs de alto nível simples e fáceis de usar.
Código de Exemplo:
const chain = new SqlDatabaseChain({ llm: new OpenAI({ temperature: 0 }), database: db, sqlOutputKey: "sql", }); const res = await chain.call({ query: "Quantas faixas existem?" }); -
Chains Prontas para Uso: O LangChain vem pré-carregado com chains prontas para uso, como
SqlDatabaseChain, que podem ser personalizadas ou usadas como base para a construção de novas aplicações.
LlamaIndex
-
Especializado em Busca e Recuperação: O LlamaIndex foi projetado para construir aplicações de busca e recuperação. Ele oferece uma interface simples para consultar LLMs e recuperar documentos relevantes.
Código de Exemplo:
query_engine = index.as_query_engine() response = query_engine.query("Stackoverflow é incrível.") -
Eficiência: O LlamaIndex foi otimizado para desempenho, tornando-o uma opção melhor para aplicações que precisam processar grandes volumes de dados rapidamente.
-
Conectores de Dados: O LlamaIndex pode ingestar dados de várias fontes, incluindo APIs, PDFs, bancos de dados SQL e outros, permitindo integração perfeita em aplicações LLM.
-
Indexação Otimizada: Uma das principais características do LlamaIndex é a sua capacidade de estruturar os dados ingeridos em representações intermediárias otimizadas para consultas rápidas e eficientes.
Quando Usar Qual Framework?
-
Aplicações de Uso Geral: Se você está construindo um chatbot que precisa ser flexível e versátil, o LangChain é a escolha ideal. Sua natureza de uso geral e APIs de alto nível o tornam adequado para uma ampla gama de aplicações.
-
Foco em Busca e Recuperação: Se a função principal do seu chatbot for buscar e recuperar informações, o LlamaIndex é a melhor opção. Seus recursos especializados de indexação e recuperação o tornam altamente eficiente para essas tarefas.
-
Combinação de Ambos: Em alguns cenários, pode ser benéfico usar ambos os frameworks. O LangChain pode lidar com funcionalidades gerais e interações com LLMs, enquanto o LlamaIndex pode gerenciar tarefas especializadas de busca e recuperação. Essa combinação pode oferecer uma abordagem equilibrada, aproveitando a flexibilidade do LangChain e a eficiência do LlamaIndex.
Código de Exemplo para Uso Combinado:
# LangChain para funcionalidades gerais res = llm.call("Me conte uma piada") # LlamaIndex para busca especializada query_engine = index.as_query_engine() response = query_engine.query("Me conte sobre as mudanças climáticas.")
Então, Qual Devo Escolher? LangChain ou LlamaIndex?
A escolha entre o LangChain e o LlamaIndex - ou a decisão de usar ambos - deve ser guiada pelos requisitos e objetivos específicos do seu projeto. O LangChain oferece uma variedade maior de capacidades e é ideal para aplicações de uso geral. Em contraste, o LlamaIndex é especializado em busca e recuperação eficientes, tornando-o adequado para tarefas intensivas em dados. Ao entender as nuances técnicas e capacidades de cada framework, você pode tomar uma decisão informada que melhor se alinha com suas necessidades de desenvolvimento de chatbot.
Conclusão
Agora você deve ter uma compreensão sólida do que o LlamaIndex é. Desde seus índices especializados até sua ampla gama de aplicações e sua vantagem sobre outras ferramentas como o LangChain, o LlamaIndex se mostra uma ferramenta indispensável para quem trabalha com Large Language Models. Seja você está construindo um mecanismo de busca, um sistema de recomendação ou qualquer aplicação que requer consultas eficientes e recuperação de dados, o LlamaIndex tem tudo que você precisa.
Perguntas Frequentes sobre o LlamaIndex
Vamos responder algumas das perguntas mais comuns sobre o LlamaIndex.
Para que é usado o LlamaIndex?
O LlamaIndex é usado principalmente como uma camada intermediária entre os usuários e os Large Language Models. Ele se destaca na execução de consultas, síntese de respostas e integração de dados, tornando-o ideal para uma variedade de aplicações, como mecanismos de busca e sistemas de recomendação.
O LlamaIndex é gratuito?
Sim, o LlamaIndex é uma ferramenta de código aberto e, portanto, gratuita para uso. Você pode encontrar seu código-fonte no GitHub e contribuir para seu desenvolvimento.
O que é GPT Index e LlamaIndex?
O GPT Index é projetado para consultas baseadas em texto e geralmente é usado com modelos GPT (Generative Pre-trained Transformer). O LlamaIndex, por outro lado, é mais versátil e pode lidar com consultas baseadas em texto e vetores, tornando-o compatível com uma variedade maior de Large Language Models.
Qual é a arquitetura do LlamaIndex?
O LlamaIndex é construído com uma arquitetura modular que inclui vários tipos de índices, como o índice de armazenamento de vetores e o índice baseado em palavras-chave. Ele é principalmente escrito em Python e suporta vários algoritmos, como k-NN, TF-IDF e embeddings BERT.
Quer ficar por dentro das últimas notícias sobre LLM? Confira o LLM leaderboard mais recente!
