LLaVA-Med: O Próximo Grande Salto em Imagens Biomédicas

O mundo da imagem médica está presenciando uma mudança paradigmática. Os dias em que os profissionais de saúde dependiam exclusivamente de sua visão aguçada e anos de experiência para interpretar exames médicos ficaram para trás. Surgiu o LLaVA-Med, uma variante especializada do renomado modelo LLaVA, projetado exclusivamente para o setor biomédico. Essa poderosa ferramenta não é apenas mais uma tecnologia; ela representa o futuro do diagnóstico e do planejamento de tratamento. Sejam radiografias, ressonâncias magnéticas ou exames tridimensionais intrincados, o LLaVA-Med oferece insights incomparáveis, preenchendo a lacuna entre as práticas tradicionais e a tecnologia de IA de ponta.
Imagine ter um assistente que possa fornecer uma análise aprofundada de qualquer imagem ou texto médico ao seu alcance. Isso é o LLaVA-Med para você. Oferecendo uma combinação de precisão e capacidades multimodais, ele está prestes a se tornar um companheiro indispensável para profissionais de saúde em todo o mundo. Vamos embarcar em uma jornada para descobrir o que torna essa ferramenta tão excepcional.
Quer saber as últimas notícias do LLM? Confira o ranking mais recente do LLM!
O que é o LLaVA-Med?
LLaVA-Med é uma variante única do modelo LLaVA, especificamente ajustada para o setor biomédico. Ele é projetado para interpretar e analisar imagens e textos médicos, tornando-se uma ferramenta inestimável para os profissionais de saúde. Seja você está examinando radiografias, ressonâncias magnéticas ou exames tridimensionais complexos, o LLaVA-Med fornece insights detalhados que podem auxiliar no diagnóstico e planejamento do tratamento.
Microsoft aprimorou o código aberto #LLaVA e criou o LLaVA-Med, um modelo de visão e linguagem capaz de interpretar imagens biomédicas. Imagine ajustar esse modelo para ler estudos de sua instituição, gerando textos precisos e personalizados na sua linguagem e tom. pic.twitter.com/rnSOWITTLB
— Paulo Kuriki, MD (@kuriki) 8 de outubro de 2023
O que torna o LLaVA-Med único?
-
Ajustado para Dados Médicos: Ao contrário do modelo LLaVA de propósito geral, o LLaVA-Med é treinado em um conjunto de dados especializado que compreende revistas médicas, anotações clínicas e uma grande variedade de imagens médicas.
-
Alta Precisão: O LLaVA-Med possui taxas de precisão impressionantes ao interpretar imagens médicas, muitas vezes superando outros softwares de imagem médica.
-
Capacidades Multimodais: O LLaVA-Med pode analisar tanto texto quanto imagens, tornando-o ideal para interpretar prontuários de pacientes que frequentemente contêm uma mistura de anotações escritas e imagens médicas.
Avaliando o LLaVA-Med: Ele é Bom?
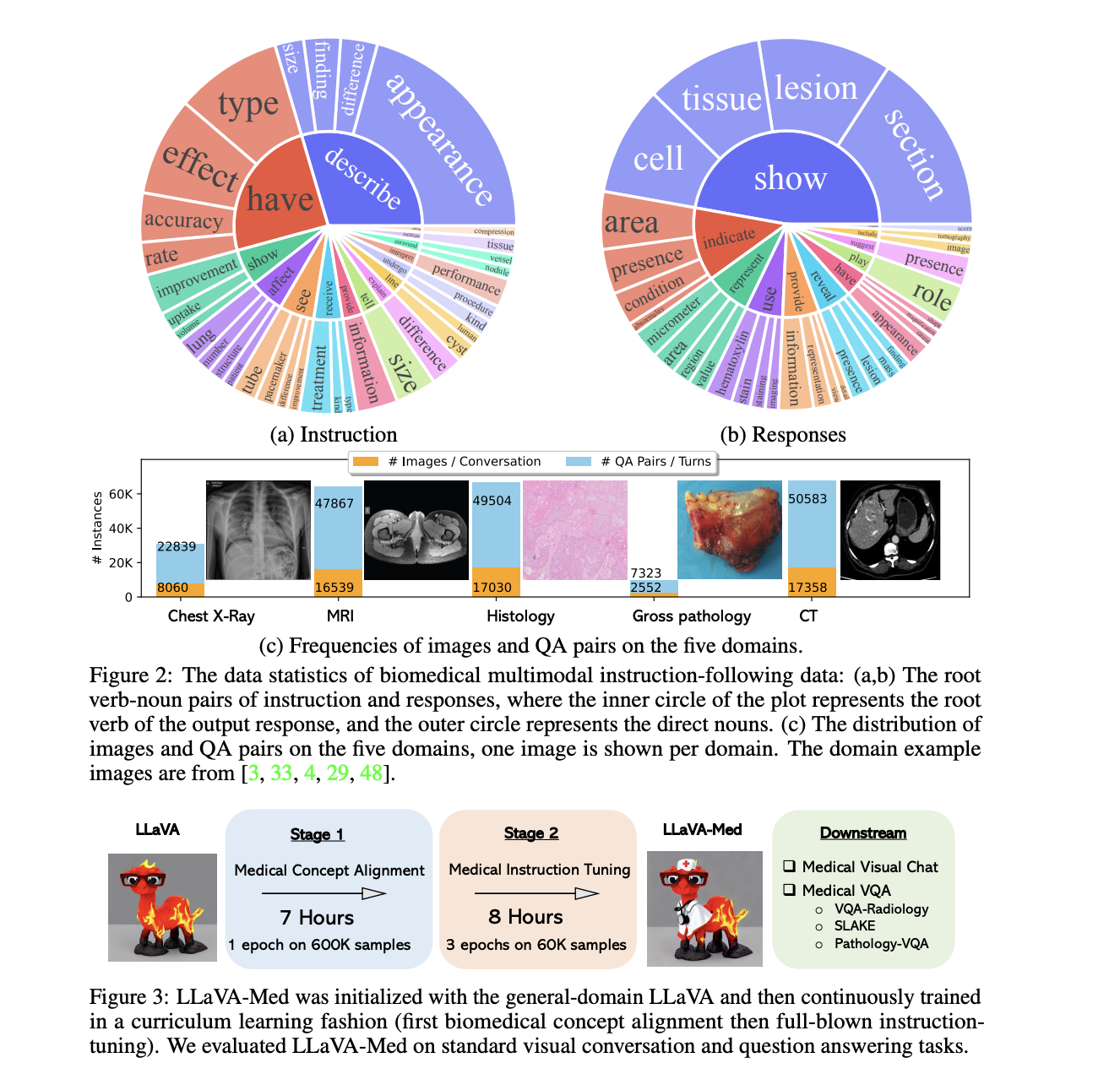
Certamente, vou integrar as informações da tabela fornecida no texto.
1. Proficiência do LLaVA-Med em Interpretações Biomédicas Visuais:
Enraizado no amplo modelo LLaVA, a excelência do LLaVA-Med é enfatizada distintivamente na interpretação de dados visuais biomédicos.
-
Conjuntos de Dados de Referência para Avaliação: O LLaVA-Med, assim como outros modelos, são avaliados em vários conjuntos de dados, com benchmarks específicos como VQA-RAD, SLAKE e PathVQA testando a capacidade do modelo em responder a perguntas visuais nas áreas de radiologia, patologia e muito mais.
-
Resultados de Ajuste Supervisionado: A tabela mostra os resultados dos experimentos de ajuste supervisionado com métodos diferentes:
| Método | VQA-RAD (Ref) | VQA-RAD (Aberto) | VQA-RAD (Fechado) | SLAKE (Ref) | SLAKE (Aberto) | SLAKE (Fechado) | PathVQA (Ref) | PathVQA (Aberto) | PathVQA (Fechado) |
|---|---|---|---|---|---|---|---|---|---|
| LLaVA | 50.00 | 65.07 | 78.18 | 63.22 | 7.74 | 63.20 | |||
| LLaVA-Med (LLaVA) | 61.52 | 84.19 | 83.08 | 85.34 | 37.95 | 91.21 | |||
| LLaVA-Med (Vicuna) | 64.39 | 81.98 | 84.71 | 83.17 | 38.87 | 91.65 | |||
| LLaVA-Med (BioMed) | 64.75 | 83.09 | 87.11 | 86.78 | 39.60 | 91.09 |
Descrição das Métricas:
-
Método: Isso indica a versão ou abordagem específica do modelo que está sendo avaliado. Ele engloba várias iterações e fontes do LLaVA e do LLaVA-Med.
-
VQA-RAD (Ref, Aberto, Fechado): Métricas para o questionamento visual em radiologia. 'Ref' refere-se à pontuação de referência, 'Aberto' à pontuação em perguntas abertas e 'Fechado' à pontuação em perguntas fechadas.
-
SLAKE (Ref, Aberto, Fechado): Métricas para o benchmark SLAKE. 'Ref' representa a pontuação de referência, 'Aberto' corresponde à pontuação em perguntas abertas e 'Fechado' é para a pontuação em perguntas fechadas.
-
PathVQA (Ref, Aberto, Fechado): Métricas relacionadas à Pathology Visual Question Answering. 'Ref' indica a pontuação de referência, 'Aberto' representa a pontuação de perguntas de resposta aberta e 'Fechado' significa a pontuação de perguntas de resposta fechada.
Referência: Fonte de pesquisa (opens in a new tab)
Ao juxtapor os resultados do LLaVA-Med derivados de vários métodos, fica evidente que o modelo exibe um desempenho formidável em interpretações biomédicas visuais, especialmente quando avaliado em comparação com benchmarks como VQA-RAD e SLAKE. Essa proficiência destaca seu potencial em auxiliar profissionais médicos a tomar decisões mais informadas com base em dados visuais.
2. Proficiência do LLaVA-Med em Seguir Instruções:
Originado do modelo extenso LLaVA, a especialização do LLaVA-Med é pronunciada devido a seu enfoque personalizado em nuances biomédicas.
-
Dataset para o Aperfeiçoamento do Modelo: O aprimoramento do LLaVA-Med utilizou um dataset biomédico multimodal de instruções. Abrangendo diversos contextos biomédicos do mundo real, esse dataset garante a habilidade do LLaVA-Med em articular e compreender conhecimentos médicos.
-
Visão Geral da Adaptação em Duas Fases:
- Fase 1 (Integração de Conceitos Biomédicos): Essa fase fundamental foi crucial. Ela teve como objetivo mesclar o conhecimento completo do LLaVA com conceitos biomédicos distintos. Essa etapa garantiu que o aprimoramento subsequente estivesse de acordo com as complexidades médicas.
- Fase 2 (Ajuste Instrucional Abrangente): Um momento pivotal, essa fase submeteu o modelo a um treinamento intensivo em diretrizes biomédicas, fortalecendo sua capacidade de entender, engajar e tratar contextos médicos de forma intuitiva.
Desempenho Comparativo do LLaVA em relação ao LLaVA-Med:
| Iteração do Modelo | Conversa (%) | Descrição (%) | CXR (%) | MRI (%) | Histologia (%) | Anatomia (%) | TC (%) | Acumulado (%) |
|---|---|---|---|---|---|---|---|---|
| LLaVA | 39.4 | 26.2 | 41.6 | 33.4 | 38.4 | 32.9 | 33.4 | 36.1 |
| LLaVA-Med Fase 1 | 22.6 | 25.2 | 25.8 | 19.0 | 24.8 | 24.7 | 22.2 | 23.3 |
| LLaVA-Med Fase 2 | 52.4 | 49.1 | 58.0 | 50.8 | 53.3 | 51.7 | 52.2 | 53.8 |
Descrições das Métricas:
-
Iteração do Modelo: designa a iteração ou fase específica do modelo que está sendo analisada. Inclui o LLaVA principal, o LLaVA-Med após a fase primária e após a fase secundária.
-
Conversa (%): uma métrica que destaca a proficiência do modelo em manter um diálogo contextual e oferecer respostas relevantes.
-
Descrição (%): um indicador da capacidade do modelo de elucidar minuciosamente aspectos visuais médicos, garantindo que os detalhes transmitidos sejam precisos.
-
CXR (%): dedicado a avaliar a precisão do LLaVA-Med ao interpretar radiografias de tórax, uma ferramenta indispensável em diagnósticos clínicos.
-
MRI (%): mede a aptidão do modelo em analisar e explicar resultados de ressonância magnética. As ressonâncias magnéticas, com suas informações detalhadas, são cruciais para diagnósticos médicos e decisões terapêuticas.
-
Histologia (%): um reflexo da eficácia do modelo em analisar estudos microscópicos de tecido, essenciais para identificar irregularidades celulares.
-
Anatomia (%): uma medida da capacidade do LLaVA-Med em elucidar estruturas anatômicas macroscópicas, visíveis sem auxílio microscópico.
-
TC (%): avalia a precisão do modelo ao interpretar tomografias computadorizadas, conhecidas por suas imagens corporais abrangentes em seção transversal.
-
Acumulado (%): uma pontuação consolidada que engloba o desempenho do modelo em diversas categorias.
Referência: Fonte de pesquisa (opens in a new tab)
3. Chatbot Visual LLaVA-Med, em Palavras Simples:
LLaVA-Med não é apenas bom com palavras; ele também é ótimo em entender imagens.
-
Bom em Muitas Coisas: LLaVA-Med sabe muito sobre diferentes imagens médicas. Ele pode analisar imagens de radiografias de tórax a ressonâncias magnéticas e até mesmo de pequenas amostras de tecido.
-
Muitos Dados: O que o torna tão bom? Ele viu e aprendeu com muitas imagens e textos. Assim, ele conhece coisas como radiografias de tórax, exames do corpo e até mesmo imagens simples do corpo.
-
Uso no Mundo Real: Pense nos médicos que analisam centenas de radiografias de tórax. LLaVA-Med pode ajudar, verificando rapidamente essas imagens, identificando problemas e facilitando o trabalho do médico.
-
Como se Compara ao GPT-4: GPT-4 é ótimo com palavras. Mas quando se trata de entender imagens médicas e falar sobre elas, LLaVA-Med faz um trabalho melhor. Ele pode analisar uma imagem médica e falar sobre ela em detalhes.
-
Não é Perfeito: Como tudo, LLaVA-Med tem suas limitações. Às vezes, pode ficar confuso se uma imagem for muito diferente do que ele conhece. Mas, à medida que ele vê mais imagens, ele pode aprender e melhorar.
Você pode testar uma versão online do LLaVA-Med aqui (opens in a new tab).
Como Instalar o LLaVA-Med: Passo a Passo
Colocar o LLaVA-Med para funcionar envolve alguns passos a mais do que o modelo LLaVA de uso geral, dada sua natureza especializada. Aqui está como fazer:
Passo 1: Iniciando o Repositório LLaVA-Med
Clone Facilitado:
Inicie clonando o Repositório LLaVA-Med. Abra o terminal e digite:
git clone https://github.com/microsoft/LLaVA-Med.gitEsse comando busca todos os arquivos necessários diretamente do repositório da Microsoft para a sua máquina.
Passo 2: Acessando o Diretório LLaVA-Med
Essenciais para Navegação:
Após clonar o repositório, seu próximo passo é mudar o diretório de trabalho. Veja como:
cd LLaVA-MedAo executar esse comando, você se posiciona no coração do diretório do LLaVA-Med, pronto para prosseguir para a próxima fase.
Passo 3: Configurando a Base - Instalando Pacotes
Uma Fundação Construída em Dependências:
Todo software intricado vem com seu conjunto de dependências. LLaVA-Med não é exceção. Com o seguinte comando, você instalará tudo o que é necessário para que ele funcione corretamente:
pip install -r requirements.txtLembre-se, não se trata apenas de instalar pacotes. Trata-se de criar um ambiente favorável para que o LLaVA-Med possa mostrar suas capacidades.
Passo 4: Interagindo com o LLaVA-Med
Executando Exemplos de Prompt para Presenciar a Magia:
Pronto para a ação? Comece integrando o modelo LLaVA-Med ao seu script Python:
from LLaVAMed import LLaVAMedColoque o modelo em funcionamento:
model = LLaVAMed()Mergulhe em uma análise de texto médico de exemplo:
text_output = model.analyze_medical_text("Descreva os sintomas de pneumonia.")
print(text_output)E para aqueles interessados em análise de imagem médica:
image_output = model.analyze_medical_image("caminho/para/rx.jpg")
print(image_output)Executando esses comandos revela a capacidade analítica do LLaVA-Med. Por exemplo, a análise de texto médico pode iluminar sintomas, fatores causadores e tratamentos potenciais para pneumonia. Por outro lado, a análise de imagem pode identificar quaisquer discrepâncias ou anormalidades no raio-X. Você pode conferir o Código Fonte do LLaVA-Med no GitHub (opens in a new tab).
Conclusão
Embora a IA em imagiologia médica mostre um imenso potencial em termos de precisão e eficiência, ela ainda não está em um estágio em que possa substituir completamente os médicos humanos. A tecnologia serve como uma ferramenta poderosa para auxiliar no diagnóstico, mas requer a supervisão e a experiência de um profissional médico para fornecer o cuidado mais confiável e abrangente. Portanto, o foco deve estar em criar um ambiente colaborativo onde a IA e a expertise humana possam coexistir para fornecer o mais alto padrão de cuidados de saúde.
Quer ficar por dentro das últimas notícias do LLM? Confira a tabela de classificação mais recente do LLM!
