Como Executar Modelos Mistral Localmente - Um Guia Completo

No cenário em constante evolução da inteligência artificial, a Mistral AI surgiu como um farol de inovação, explorando novos territórios no campo de modelos de linguagem grandes (LLMs). Com a introdução de seus modelos revolucionários, a Mistral AI não apenas avança a fronteira da aprendizagem de máquina, mas também democratiza o acesso à tecnologia de ponta. Este guia tem como objetivo esclarecer as complexidades das ofertas da Mistral AI e fornecer um roteiro abrangente para aproveitar suas capacidades localmente.
O que são esses Modelos da Mistral AI?
A Mistral AI lançou uma série de modelos de linguagem que não são apenas iterações, mas saltos no campo da linguística computacional. No cerne desta série estão o Mistral 7B e o Mixtral 8x7B, cada um projetado para atender a diversas necessidades e capacidades de computação.
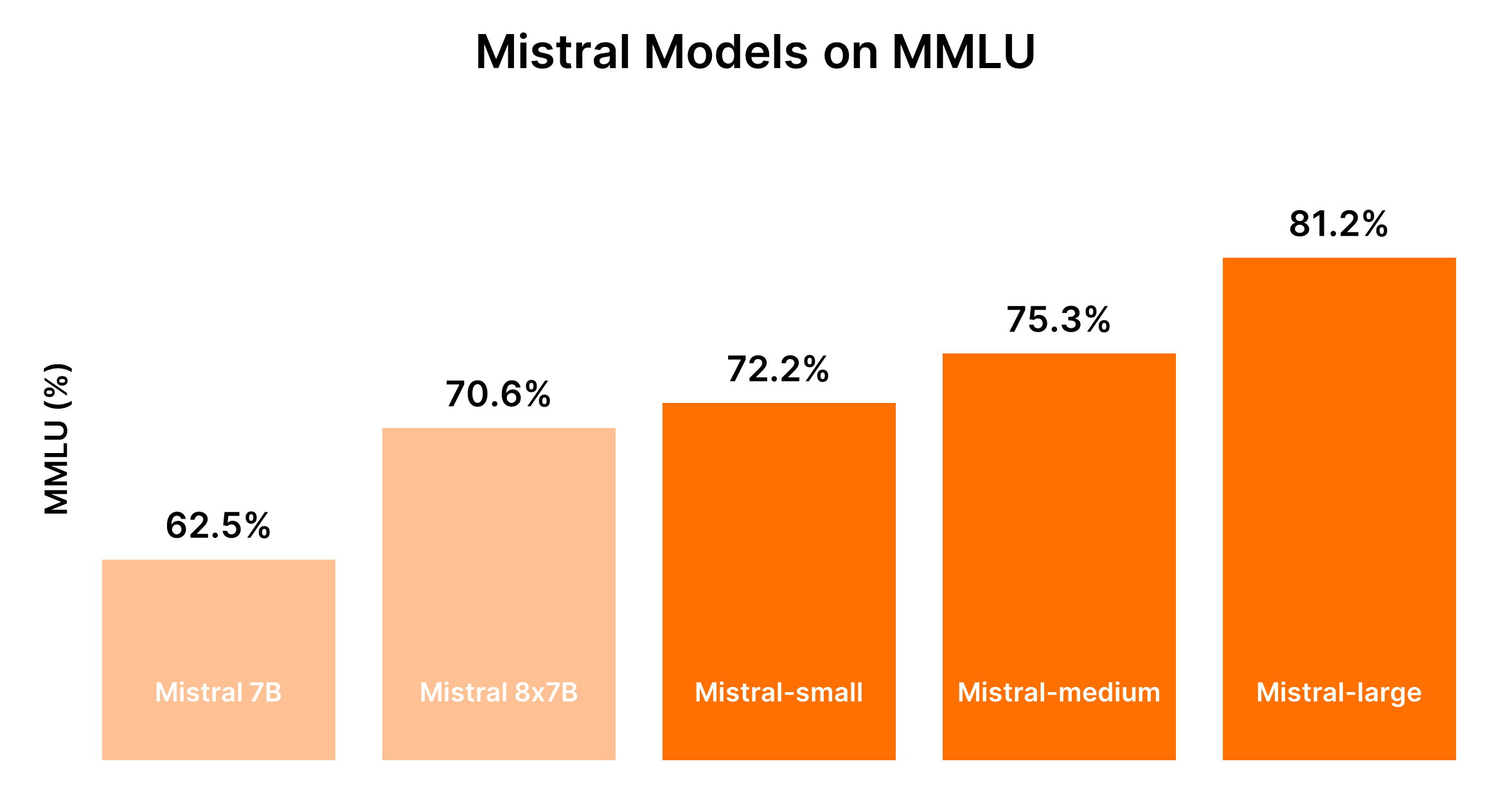
Comparando os Modelos Mistral AI (Mistral 7B vs Mistral 8x7b vs Mistral Small vs Mistral Medium vs Mistral Large)
Entendido. Com base nas informações fornecidas e com foco na criação de tabelas no formato markdown para comparação direta, vamos estruturar a análise comparativa dos modelos da Mistral AI.
Análise Comparativa dos Modelos Mistral AI
A Mistral AI oferece uma variedade de modelos, cada um adaptado para diferentes casos de uso, desde tarefas em massa simples até capacidades complexas de raciocínio. Abaixo estão análises comparativas e resultados de desempenho no formato markdown para uma compreensão clara.
Visão Geral do Modelo e Casos de Uso
| ID do Modelo | Alias | Casos de Uso |
|---|---|---|
| open-mistral-7b | mistral-tiny-2312 | Tarefas simples em massa, como classificação, suporte ao cliente ou geração de texto |
| open-mixtral-8x7b | mistral-small-2312 | Semelhante ao open-mistral-7b, adequado para tarefas simples em massa |
| mistral-small-latest | mistral-small-2402 | Tarefas levemente avançadas requerendo raciocínio mínimo |
| mistral-medium-latest | mistral-medium-2312 | Tarefas intermediárias, como extração de dados, resumir documentos, escrever e-mails |
| mistral-large-latest | mistral-large-2402 | Tarefas complexas que exigem grandes capacidades de raciocínio, como geração de texto sintético, geração de código |
Desempenho e Decisões de Custo
O desempenho dos modelos Mistral é geralmente proporcional ao seu tamanho, onde modelos maiores fornecem capacidades aprimoradas, mas a um custo mais alto. A tabela a seguir resume as classificações de desempenho com base no benchmark MMLU e nas considerações de custo generalizadas.
| Modelo | Classificação de Desempenho | Consideração de Custo |
|---|---|---|
| Mistral 7B (tiny-2312) | 5º | Mais econômico para tarefas simples |
| Mixtral 8x7B (small-2312) | 4º | Economicamente viável para tarefas simples em massa |
| Mistral Small (small-2402) | 3º | Custo moderado, adequado para tarefas com raciocínio mínimo |
| Mistral Medium (medium-2312) | 2º | Custo mais alto, desempenho equilibrado para tarefas intermediárias |
| Mistral Large (large-2402) | 1º | Custos mais elevados, desempenho incomparável para tarefas complexas |
Dado a natureza dinâmica do desempenho dos LLMs e os custos associados, é recomendado consultar benchmarks e preços atuais para uma comparação mais precisa. Para benchmarks atualizados e informações de desempenho, plataformas como o Chatbot Arena Leaderboard (opens in a new tab) da Hugging Face e Artificial Analysis (opens in a new tab) podem fornecer informações valiosas.
Orientação na Decisão: Qual Modelo da Mistral AI Você Deve Escolher?
A escolha do modelo certo depende do equilíbrio entre as necessidades de desempenho e as restrições de custo, considerando a complexidade das tarefas que sua aplicação pretende lidar.
- Para Tarefas Simples: Comece com o Mistral Small ou Mistral 7B para eficiência de custo.
- Para Tarefas Intermediárias a Complexas: Avalie se o desempenho aprimorado do Mistral Medium ou Mistral Large justifica o custo adicional com base nas necessidades específicas da sua aplicação.
Esta comparação estruturada visa facilitar a tomada de decisões informadas ao selecionar entre as ofertas de modelos da Mistral AI, garantindo que o modelo escolhido esteja alinhado tanto com os requisitos funcionais quanto com as restrições orçamentárias do seu projeto.

Parte 1. Como Executar a Mistral Localmente com o Ollama (de Forma Fácil)
Executar modelos da Mistral AI localmente com o Ollama oferece uma maneira acessível de aproveitar o poder desses LLMs avançados em sua própria máquina. Essa abordagem é ideal para desenvolvedores, pesquisadores e entusiastas que desejam experimentar análise de texto orientada por IA, geração de texto e muito mais, sem depender de serviços em nuvem. Aqui está um guia conciso para você começar:
Etapa 1: Baixe o Ollama
- Visite a página de download do Ollama e escolha a versão adequada para o seu sistema operacional. Para usuários do macOS, você baixará um arquivo
.dmg. - Instale o Ollama arrastando o arquivo baixado para o diretório
/Applications.
Etapa 2: Explore os Comandos do Ollama
Abra o seu terminal e digite ollama para ver a lista de comandos disponíveis. Você verá opções como serve, create, show, run, pull e mais.
Passo 3: Instalar o Mistral AI
Para instalar um modelo do Mistral AI, primeiro você precisa encontrar o modelo que deseja instalar. Se você estiver interessado na versão Mistral:instruct, você pode instalá-lo diretamente ou puxá-lo se ele ainda não estiver na sua máquina.
- Para executar diretamente (e baixar, se necessário):
ollama run mistral:instruct - Para pré-baixar o modelo:
ollama pull mistral:instruct
Passo 4: Interagir com o Mistral AI
Depois que o modelo estiver instalado, você pode interagir com ele no modo interativo ou passando inputs diretamente.
-
Para o modo interativo:
ollama run mistral --verboseEm seguida, siga as instruções para inserir suas consultas.
-
Para o modo não-interativo (input direto): Suponha que você tenha um artigo que deseja resumir salvo em
bbc.txt. Você pode passar o conteúdo do artigo diretamente para o Mistral para resumir:ollama run mistral --verbose "Por favor, você pode resumir este artigo: $(cat bbc.txt)"Substitua
"Por favor, você pode resumir este artigo: $(cat bbc.txt)"por qualquer texto relevante para a sua tarefa.
Análise de Saída de Exemplo
Seu terminal exibirá a saída do modelo, incluindo o resumo ou resposta à sua solicitação. É fascinante ver como o Mistral processa e entende consultas complexas, mesmo oferecendo correções quando questionado sobre imprecisões.
Executando o Mistral AI a partir da API HTTP
Ollama também suporta uma API HTTP, permitindo interação programática com os modelos.
- Exemplo de solicitação
curl:curl -X POST http://localhost:11434/api/generate -d '{ "model": "mistral", "prompt": "Qual é o sentimento desta frase: A situação em torno do árbitro assistente de vídeo está em um ponto de crise." }'
Este método retorna respostas JSON que podem ser analisadas programaticamente, oferecendo uma maneira flexível de integrar as capacidades do Mistral AI em aplicativos.
Executar o Mistral AI com o Ollama em uma máquina local abre vastas possibilidades para aproveitar a IA em projetos pessoais, desenvolvimento e pesquisa. A facilidade de instalação e uso, combinada com o poder dos LLMs do Mistral, torna esta uma opção convincente para qualquer pessoa interessada em explorar as fronteiras da tecnologia de IA.
Parte 2. Como Executar o Mistral 7B Localmente no Windows
O Mistral 7B pode ser acessado por meio de várias plataformas, incluindo HuggingFace, Vertex AI, Replicate, Sagemaker Jumpstart e Baseten. O recurso "Models" do Kaggle também oferece uma abordagem simplificada, permitindo que você comece com inferência ou ajuste fino em minutos sem a necessidade de baixar o modelo ou conjunto de dados.
Preliminares para Acessar o Mistral 7B
Antes de começar, verifique se o seu ambiente está atualizado para evitar erros comuns como KeyError: 'mistral':
!pip install -q -U transformers
!pip install -q -U accelerate
!pip install -q -U bitsandbytesImplementando Quantização de 4 Bits
Para agilizar o carregamento do modelo e reduzir o uso de memória, é utilizada a quantização de 4 bits:
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig, pipeline
import torch
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
)Carregando o Mistral 7B nos Notebooks do Kaggle
Os Notebooks do Kaggle facilitam a adição do Mistral 7B por meio de uma interação simples de UI. Após selecionar a variação e versão do modelo apropriadas, você pode facilmente carregar o modelo e o tokenizer para uso:
model_name = "/kaggle/input/mistral/pytorch/7b-v0.1-hf/1"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
load_in_4bit=True,
quantization_config=bnb_config,
torch_dtype=torch.bfloat16,
device_map="auto",
trust_remote_code=True,
)Utilizando a função pipeline, simplifica-se o processo de geração de respostas com base no prompt fornecido.
Inferência de Exemplo
Ao definir um prompt e invocar o pipeline, o Mistral 7B gera respostas coerentes e contextualmente relevantes, ilustrando seu entendimento de conceitos complexos como regularização em aprendizado de máquina:
prompt = "Como cientista de dados, você pode explicar o conceito de regularização em aprendizado de máquina?"
sequences = pipe(
prompt,
do_sample=True,
max_new_tokens=100,
temperature=0.7,
top_k=50,
top_p=0.95,
num_return_sequences=1,
)
print(sequences[0]['generated_text'])Como Fazer o Ajuste Fino do Mistral 7B
O processo de ajuste fino envolve a atualização de bibliotecas, configuração de módulos e adaptação do modelo ao seu conjunto de dados. Usando os Notebooks do Kaggle, chaves de API para serviços como Hugging Face e Weights & Biases são armazenadas e acessadas com segurança. Esta seção detalha as etapas e configurações essenciais para um ajuste fino eficaz, garantindo que você maximize o potencial do modelo em seu conjunto de dados específico.
- Atualize e Instale as Bibliotecas Necessárias: Garante compatibilidade e acesso aos recursos mais recentes para ajuste fino.
- Carregue os Módulos e Configure o Acesso à API: Facilita a interação com serviços externos e repositórios de modelos.
- Configure e Treine o Modelo: Adapta o modelo para se ajustar às nuances do seu conjunto de dados, aproveitando o poder do PEFT (Ajuste Fino com Eficiência de Parâmetros) para treinamento eficiente.
- Avalie e Salve seu Modelo: Avalia o desempenho do modelo e salva o modelo ajustado
O passo a passo detalhado tem como objetivo equipá-lo com as ferramentas e conhecimentos necessários para aproveitar efetivamente as capacidades do modelo Mistral 7B. Desde o acesso ao modelo até o ajuste fino em um conjunto de dados específico, cada etapa é projetada para aprimorar as capacidades de processamento de linguagem natural do seu projeto.
Parte 3. Como Executar o Mixtral 8x7b Localmente com LlamaIndex e Ollama

O poderoso Mistral AI, a potência europeia de IA, recentemente revelou seu modelo "mixture of experts", Mixtral 8x7b. Esse modelo, que conta com oito especialistas, cada um treinado com 7 bilhões de parâmetros, despertou grande interesse por igualar ou até superar o desempenho de GPT-3.5 e Llama2 70b em vários benchmarks.
Passo 1: Instalar Ollama
Ollama, uma ferramenta de código aberto disponível para MacOS, Linux e Windows (por meio do Windows Subsystem For Linux), simplifica o processo de execução de modelos locais. Com o Ollama, você pode iniciar o Mixtral com um único comando:
ollama run mixtralEsse comando faz o download do modelo (o que pode levar algum tempo) e requer uma quantidade significativa de RAM (48GB) para funcionar corretamente. Para sistemas com especificações mais baixas, Mistral 7b é uma alternativa viável.
Passo 2: Instalar Dependências
Para integrar o Mixtral com o LlamaIndex, você precisará de várias dependências. Instale-as usando o pip:
pip install llama-index qdrant_client torch transformersPasso 3: Teste Inicial
Verifique a configuração com um "teste inicial" usando o Ollama e o LlamaIndex:
from llama_index.llms import Ollama
llm = Ollama(model="mixtral")
response = llm.complete("Quem é Laurie Voss?")
print(response)Passo 4: Carregar Dados e Indexá-los
Preparando os Dados:
Use qualquer conjunto de dados para este exemplo; aqui, usamos uma coleção de tweets. O Qdrant, um banco de dados de vetores de código aberto, armazena os dados. Os trechos de código a seguir mostram o processo de carregar e indexar os dados com o Qdrant e o LlamaIndex:
from pathlib import Path
import qdrant_client
from llama_index import VectorStoreIndex, ServiceContext, download_loader
from llama_index.llms import Ollama
from llama_index.storage.storage_context import StorageContext
from llama_index.vector_stores.qdrant import QdrantVectorStore
## Inicialize o Qdrant e carregue os tweets
client = qdrant_client.QdrantClient(path="./qdrant_data")
vector_store = QdrantVectorStore(client=client, collection_name="tweets")
storage_context = StorageContext.from_defaults(vector_store=vector_store)
## Configure o Service Context com o Mixtral e incorpore localmente
llm = Ollama(model="mixtral")
service_context = ServiceContext.from_defaults(llm=llm, embed_model="local")
## Indexe e consulte dados
index = VectorStoreIndex.from_documents(documents, service_context=service_context, storage_context=storage_context)
query_engine = index.as_query_engine()
response = query_engine.query("O que o autor pensa sobre Star Trek? Dê detalhes.")
print(response)Verificando o Índice:
A etapa final envolve o uso do índice pré-construído para responder a consultas. Esse processo não requer o carregamento dos dados novamente, pois eles já estão indexados no Qdrant:
import qdrant_client
from llama_index import VectorStoreIndex, ServiceContext
from llama_index.llms import Ollama
from llama_index.vector_stores.qdrant import QdrantVectorStore
## Carregue o vetor de armazenamento e o Mixtral
client = qdrant_client.QdrantClient(path="./qdrant_data")
vector_store = QdrantVectorStore(client=client, collection_name="tweets")
llm = Ollama(model="mixtral")
service_context = ServiceContext.from_defaults(llm=llm, embed_model="local")
## Carregue o índice e faça consultas
index = VectorStoreIndex.from_vector_store(vector_store=vector_store, service_context=service_context)
query_engine = index.as_query_engine(similarity_top_k=20)
response = query_engine.query("O autor gosta de SQL? Dê detalhes.")
print(response)Parte 4. Como Executar o Mistral 8x7B Localmente com llama.cpp
A execução local de modelos do Mistral AI se tornou mais acessível graças a ferramentas como 'llama.cpp' e o plugin 'llm-llama-cpp'. O lançamento do modelo Mixtral 8x7B, um modelo "sparse mixture of experts" (SMoE) de alta qualidade, marcou um avanço significativo no cenário de IA de código aberto. Aqui está um guia breve sobre como executar o Mixtral 8x7B localmente usando 'llama.cpp' e ferramentas relacionadas.
Instalando e Executando o Mixtral 8x7B Localmente
-
Instale a Ferramenta LLM: Primeiro, certifique-se de ter o LLM instalado em sua máquina. O LLM atua como uma ponte para executar vários modelos de IA localmente.
pipx install llm -
Instale o Plugin
llm-llama-cpp: Esse plugin é necessário para executar o Mixtral e outros modelos compatíveis com 'llama.cpp'.llm install llm-llama-cpp -
Configure o
llama-cpp-python: Para Macs Apple Silicon, a configuração pode incluir a habilitação do suporte ao Metal:CMAKE_ARGS="-DLLAMA_METAL=on" FORCE_CMAKE=1 llm install llama-cpp-pythonAs instruções detalhadas podem variar de acordo com a plataforma, portanto, consulte o README do 'llm-llama-cpp' para obter orientações.
-
Faça o Download do Modelo Mixtral: Você precisará do arquivo GGUF para o Mixtral 8x7B. Escolha um tamanho de arquivo adequado às suas necessidades; por exemplo, a variante de 36GB para a versão Instruct do modelo:
curl -LO 'https://huggingface.co/TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF/resolve/main/mixtral-8x7b-instruct-v0.1.Q6_K.gguf?download=true' -
Execute o Modelo: Com o modelo baixado, você pode executar o Mixtral 8x7B usando a ferramenta 'llm':
llm -m gguf -o path mixtral-8x7b-instruct-v0.1.Q6_K.gguf '[INST] Escreva uma função Python que faça o download de um arquivo de uma URL[/INST]'Este comando especifica o uso do modelo GGUF com a opção
-m ggufe fornece o caminho para o arquivo GGUF baixado com-o path.
Considerações Adicionais
-
Modo Interativo: Se você deseja interagir com o modelo de forma mais conversacional, considere executar o 'llm' no modo interativo. Esse modo permite um diálogo de ida e volta com o modelo de IA.
-
Construção do Prompt: O prefixo
[INST]no exemplo de comando acima indica a natureza baseada em instrução do prompt, adequada para versões de modelos do tipo "instruct". Ajuste seus prompts para corresponder ao formato de entrada esperado pelo modelo para obter resultados ótimos.
Parte 5. Executando o Mistral 7B Localmente em um iPhone

Executar o modelo Mistral 7B em um iPhone envolve alguns passos técnicos, pois os dispositivos iOS geralmente têm mais restrições do que os ambientes de desktop. Aqui está um guia simplificado passo-a-passo:
-
Pré-requisitos:
- Certifique-se de que seu iPhone esteja executando a versão mais recente do iOS para evitar problemas de compatibilidade.
- Instale um ambiente de desenvolvimento de aplicativos iOS, como o Xcode, em seu Mac, para compilar e executar o aplicativo personalizado que utilizará o Mistral 7B.
-
Escolhendo a Opção de Execução: Para implantação no iPhone,
llm-llama-cpppode ser a opção mais adequada devido à sua compatibilidade com ambientes C++, que podem ser integrados a projetos iOS. -
Configurando o Ambiente de Desenvolvimento:
- Faça o download do arquivo GGUF para
llm-llama-cppdo repositório oficial. - Abra o Xcode e crie um novo projeto iOS.
- Integre a biblioteca
llm-llama-cppem seu projeto. Isso pode exigir dependências adicionais, portanto consulte a documentação.
- Faça o download do arquivo GGUF para
-
Codificação:
- Escreva código Swift ou Objective-C para interfacear com a biblioteca C++. Isso pode envolver a criação de um cabeçalho de integração para usar código C++ em projetos Swift.
- Inicialize o modelo dentro do seu aplicativo, lidando com qualquer configuração necessária, como caminho do modelo e parâmetros.
-
Teste e Implantação:
- Teste o aplicativo em seu iPhone, garantindo que o modelo seja executado sem problemas e se comporte conforme o esperado.
- Implante o aplicativo por meio do Xcode, seja para uso pessoal ou, se estiver em conformidade com as diretrizes da Apple, envie-o para a App Store.
Parte 6. Executando o Mistral AI Localmente com a API

Para executar o Mistral AI localmente usando sua API, siga estas etapas, garantindo que você tenha um ambiente capaz de fazer requisições HTTP, como o Postman para testar ou linguagens de programação com capacidade de fazer requisições HTTP (por exemplo, Python com a biblioteca requests).
Pré-requisitos:
- Obtenha uma chave de API (opens in a new tab) se inscrevendo para ter acesso à API do Mistral.
- Certifique-se de que seu ambiente local tenha acesso à internet para se comunicar com os servidores da API do Mistral.
- Instale o plugin
llm-mistralem seu ambiente local. Isso pode envolver adicioná-lo às dependências do seu projeto em caso de projeto de programação. - Configure seu projeto ou ferramenta para usar sua chave de API do Mistral. Geralmente, isso envolve configurar a chave em um arquivo de configuração ou como uma variável de ambiente.
Criar Completude de Chat
Este ponto de extremidade da API permite gerar complementos de texto com base em uma solicitação. A solicitação requer a especificação do modelo, mensagens (prompts) e vários parâmetros para controlar o processo de geração, como temperatura, top_p e max_tokens.
Exemplo de Código Python para Completudes de Chat:
import requests
url = "https://api.mistral.ai/chat/completions"
payload = {
"model": "mistral-small-latest",
"messages": [{"role": "user", "content": "Como começo a usar o Mistral AI?"}],
"temperature": 0.7,
"top_p": 1,
"max_tokens": 512,
"stream": False,
"safe_prompt": False,
"random_seed": 1337
}
headers = {
"Authorization": "Bearer SUA_CHAVE_DE_API",
"Content-Type": "application/json"
}
response = requests.post(url, json=payload, headers=headers)
if response.status_code == 200:
print(response.json())
else:
print("Erro:", response.text)Criar Incorporações
O ponto de extremidade da API de incorporações é usado para converter texto em vetores de alta dimensão. Isso pode ser útil para tarefas como pesquisa semântica, agrupamento ou encontrar textos semelhantes.
Exemplo de Código Python para Criar Incorporações:
import requests
url = "https://api.mistral.ai/embeddings"
payload = {
"model": "mistral-embed",
"input": ["Olá", "mundo"],
"encoding_format": "float"
}
headers = {
"Authorization": "Bearer SUA_CHAVE_DE_API",
"Content-Type": "application/json"
}
response = requests.post(url, json=payload, headers=headers)
if response.status_code == 200:
print(response.json())
else:
print("Erro:", response.text)Listar Modelos Disponíveis
Essa chamada de API é simples e permite que você obtenha uma lista de todos os modelos acessíveis a você. Isso pode ajudar na seleção dinâmica de modelos para várias tarefas com base em suas capacidades ou requisitos.
Exemplo de Código Python para Listar Modelos Disponíveis:
import requests
url = "https://api.mistral.ai/models"
headers = {
"Authorization": "Bearer SUA_CHAVE_DE_API"
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
print(response.json())
else:
print("Erro:", response.text)Esses exemplos fornecem uma base para interagir com a API do Mistral AI, possibilitando a criação de aplicativos sofisticados impulsionados por IA. Lembre-se de substituir "SUA_CHAVE_DE_API" pela sua chave de API real.
Essas etapas oferecem um esboço básico para integrar e utilizar o modelo de IA Mistral 7B localmente em um iPhone e por meio de sua API. Adaptações podem ser necessárias com base nos requisitos específicos do projeto ou nas atualizações da plataforma.