Como o Groq AI Torna Consultas LLM 10x Mais Rápidas

A Groq, uma empresa de soluções de IA generativa, está redefinindo o cenário de inferência de modelos de linguagem grandes (LLM) com seu revolucionário Motor de Inferência da Unidade de Processamento de Linguagem (LPU). Esse acelerador projetado especialmente visa superar as limitações das arquiteturas tradicionais de CPU e GPU, oferecendo velocidade e eficiência sem precedentes no processamento de LLM.
Quer saber as últimas notícias sobre LLM? Confira o ranking mais recente de LLM!

A Arquitetura LPU: Uma Visão Detalhada
No cerne da arquitetura LPU da Groq está um design de núcleo único que prioriza o desempenho sequencial. Essa abordagem permite que a LPU alcance uma notável densidade de computação, com um desempenho máximo de 1 PetaFLOP/s em um único chip. A arquitetura única da LPU também elimina gargalos de memória externa, incorporando 220 MB de SRAM no chip, proporcionando impressionantes 1.5 TB/s de largura de banda de memória.
As capacidades síncronas de rede da LPU permitem escalabilidade perfeita em implantações em larga escala. Com uma largura de banda bidirecional de 1.6 TB/s por LPU, a tecnologia da Groq pode lidar de forma eficiente com as enormes transferências de dados necessárias para a inferência de LLM. Além disso, a LPU suporta uma ampla gama de níveis de precisão, desde FP32 até INT4, permitindo alta precisão mesmo em configurações de precisão mais baixas.
Avaliando o Desempenho do Groq
O Motor de Inferência LPU da Groq tem consistentemente superado gigantes do setor em vários testes comparativos. Em testes internos realizados no modelo Llama-2 70B da Meta AI, a Groq alcançou incríveis 300 tokens por segundo por usuário. Isso representa um salto significativo na velocidade de inferência de LLM, ultrapassando o desempenho de sistemas tradicionais baseados em GPU.
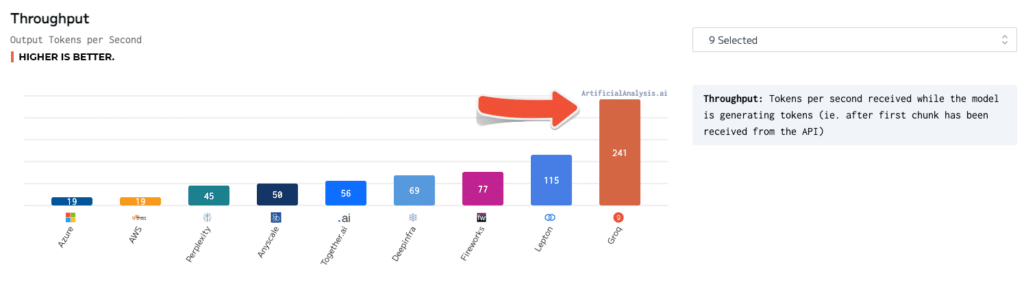
Benchmarks independentes também validaram ainda mais a superioridade do Groq. Em testes realizados pela ArtificialAnalysis.ai, a API do Groq Llama 2 Chat (70B) atingiu um throughput de 241 tokens por segundo, mais que o dobro da velocidade de outros provedores de hospedagem. O Groq também se destacou em outros indicadores-chave de desempenho, como latência versus throughput, tempo de resposta total e variância de throughput.
Para colocar esses números em perspectiva, considere um cenário em que um usuário interage com um chatbot alimentado por IA. Com o Motor de Inferência da LPU da Groq, o chatbot pode gerar respostas a uma taxa de 300 tokens por segundo, possibilitando conversas praticamente instantâneas. Em contraste, um sistema baseado em GPU pode atingir apenas 50-100 tokens por segundo, resultando em atrasos perceptíveis e em uma experiência do usuário menos envolvente.
Groq vs Outras Tecnologias de IA

Ao ser comparada às GPUs da NVIDIA, a LPU da Groq demonstra uma clara vantagem no desempenho INT8, que é crucial para inferência de LLM em alta velocidade. Em um benchmark comparando a LPU com a GPU A100 da NVIDIA, a LPU alcançou um aumento de velocidade de 3,5 vezes no modelo Llama-2 70B, processando 300 tokens por segundo em comparação com 85 tokens por segundo do A100.
A tecnologia da Groq também se destaca em relação a outros modelos de IA como o ChatGPT e o Gemini do Google. Embora números de desempenho específicos para esses modelos não estejam disponíveis publicamente, a velocidade e a eficiência demonstradas pelo Groq sugerem que ele tem potencial para superá-los em aplicações do mundo real.
Utilizando o Groq AI
A Groq oferece um conjunto abrangente de ferramentas e serviços para facilitar a implantação e utilização de sua tecnologia LPU. O conjunto GroqWare, que inclui o Groq Compiler, oferece uma experiência simplificada para começar a usar modelos rapidamente. Aqui está um exemplo de como compilar e executar um modelo usando o Groq Compiler:
# Compile o modelo
groq compile model.onnx -o model.groq
# Execute o modelo na LPU
groq run model.groq -i input.bin -o output.binPara aqueles que procuram mais personalização, a Groq também permite a codificação manual da arquitetura Groq, possibilitando o desenvolvimento de aplicativos personalizados e otimização máxima de desempenho. Aqui está um exemplo de montagem Groq codificada manualmente para uma multiplicação simples de matrizes:
; Multiplicação de matrizes na Groq LPU
; Supõe que as matrizes A e B estão carregadas na memória
; Carregue as dimensões da matriz
ld r0, [n]
ld r1, [m]
ld r2, [k]
; Inicialize a matriz de resultado C
mov r3, 0
; Loop externo sobre as linhas de A
mov r4, 0
loop_i:
; Loop interno sobre as colunas de B
mov r5, 0
loop_j:
; Acumule o produto escalar
mov r6, 0
mov r7, 0
loop_k:
ld r8, [A + r4 * m + r7]
ld r9, [B + r7 * k + r5]
mul r10, r8, r9
add r6, r6, r10
add r7, r7, 1
cmp r7, r2
jlt loop_k
; Armazene o resultado em C
st [C + r4 * k + r5], r6
add r5, r5, 1
cmp r5, r2
jlt loop_j
add r4, r4, 1
cmp r4, r0
jlt loop_iDesenvolvedores e pesquisadores também podem aproveitar a tecnologia poderosa do Groq por meio da Groq API, que fornece acesso a capacidades de inferência em tempo real. Aqui está um exemplo de como usar a Groq API para gerar texto usando o modelo Llama-2 70B:
import groq
# Inicialize o cliente Groq
client = groq.Client(api_key="sua_chave_api")
# Configure o modelo e os parâmetros
model = "llama-2-70b"
prompt = "Era uma vez, em uma terra distante..."
max_tokens = 100
# Gere o texto
response = client.generate(model=model, prompt=prompt, max_tokens=max_tokens)
# Imprima o texto gerado
print(response.text)Possíveis Aplicações e Impacto
Os tempos de resposta quase instantâneos habilitados pelo Motor de Inferência LPU da Groq estão desbloqueando novas possibilidades em várias indústrias. No campo das finanças, a tecnologia da Groq pode ser aproveitada para detecção de fraudes em tempo real e avaliação de riscos. Ao processar grandes volumes de dados de transações e identificar anomalias em milissegundos, as instituições financeiras podem prevenir atividades fraudulentas e proteger os ativos de seus clientes.
Na área da saúde, o LPU da Groq pode revolucionar o atendimento ao paciente, permitindo análise em tempo real de dados médicos. Desde o processamento de imagens médicas até a análise de registros eletrônicos de saúde, a tecnologia da Groq pode auxiliar os profissionais de saúde no diagnóstico rápido e preciso, melhorando os resultados dos pacientes.
Veículos autônomos também podem se beneficiar imensamente das capacidades de inferência de alta velocidade da Groq. Ao processar dados de sensores e tomar decisões em frações de segundos, os sistemas de IA alimentados pela Groq podem aprimorar a segurança e a confiabilidade dos carros autônomos, abrindo caminho para um futuro de transporte inteligente.
Conclusão
O Motor de Inferência LPU da Groq representa um salto significativo no campo da aceleração de IA. Com sua arquitetura inovadora, benchmarks impressionantes e conjunto abrangente de ferramentas e serviços, a Groq capacita desenvolvedores e organizações a ultrapassar os limites do que é possível com modelos de linguagem avançados.
À medida que a demanda por inferência de IA em tempo real continua a crescer, a Groq está bem posicionada para liderar o avanço na habilitação da próxima geração de soluções alimentadas por IA. Desde chatbots e assistentes virtuais até sistemas autônomos e além, as aplicações potenciais da tecnologia da Groq são vastas e transformadoras.
Com seu compromisso de democratizar o acesso à IA e fomentar a inovação, a Groq não está apenas revolucionando a paisagem técnica, mas também moldando o futuro de como interagimos e nos beneficiamos da inteligência artificial. À medida que estamos no limiar de uma era impulsionada pela IA, a tecnologia inovadora da Groq está prestes a ser um catalisador para avanços e descobertas sem precedentes nos anos futuros.
Quer ficar por dentro das últimas notícias sobre LLM? Confira a tabela de líderes mais recente do LLM!