LLaVA-Med : Le grand pas en avant dans l'imagerie biomédicale

Le monde de l'imagerie médicale est en train de connaître un changement de paradigme. Les jours où les professionnels de la santé dépendaient uniquement de leur vue perçante et de leurs années d'expérience pour interpréter les scintigraphies médicales sont révolus. Entrez LLaVA-Med, une variante spécialisée du célèbre modèle LLaVA, conçu exclusivement pour le secteur biomédical. Cet outil puissant n'est pas simplement une autre technologie ; il représente l'avenir du diagnostic et de la planification du traitement. Que ce soit pour les radiographies, les IRM ou les scans 3D complexes, LLaVA-Med offre des connaissances inégalées, comblant l'écart entre les pratiques traditionnelles et les technologies d'IA de pointe.
Imaginez-vous avoir un assistant qui peut fournir une analyse approfondie de toute image ou texte médical à portée de main. C'est LLaVA-Med pour vous. Offrant une combinaison d'exactitude et de capacités multimodales, il est destiné à être un compagnon indispensable pour les professionnels de la santé du monde entier. Embarquons pour un voyage à la découverte de ce qui rend cet outil si exceptionnel.
Vous voulez connaître les dernières nouvelles sur LLM ? Consultez le dernier classement LLM !
Qu'est-ce que LLaVA-Med ?
LLaVA-Med est une variante unique du modèle LLaVA, spécifiquement adaptée au secteur biomédical. Conçu pour interpréter et analyser des images et des textes médicaux, il constitue un outil précieux pour les professionnels de la santé. Que vous examiniez des radiographies, des IRM ou des scans 3D complexes, LLaVA-Med offre des informations détaillées qui peuvent aider au diagnostic et à la planification du traitement.
Microsoft a affiné le modèle LLaVA open source, créant LLaVA-Med, un modèle de vision-langage capable d'interpréter des images biomédicales. Imaginez affiner ce modèle pour lire des études de votre institution, générant des textes à la fois précis et adaptés à votre langage et à votre tonalité. pic.twitter.com/rnSOWITTLB
— Paulo Kuriki, MD (@kuriki) 8 octobre 2023
Ce qui rend LLaVA-Med unique
-
Affiné pour les données médicales : Contrairement au modèle LLaVA généraliste, LLaVA-Med est entraîné sur un ensemble de données spécialisé comprenant des revues médicales, des notes cliniques et une vaste gamme d'images médicales.
-
Grande précision : LLaVA-Med affiche des taux de précision impressionnants lors de l'interprétation d'images médicales, surpassant souvent les autres logiciels d'imagerie médicale.
-
Capacités multimodales : LLaVA-Med peut analyser à la fois le texte et les images, ce qui en fait un outil idéal pour interpréter les dossiers des patients, qui contiennent souvent un mélange de notes écrites et d'images médicales.
Évaluation de LLaVA-Med : à quel point est-il bon ?
Certainement, j'intégrerai les informations du tableau fourni dans le texte.
1. Compétence de LLaVA-Med dans les interprétations biomédicales visuelles :
Enracinée dans le vaste modèle LLaVA, l'excellence de LLaVA-Med est particulièrement mise en avant dans l'interprétation des données visuelles biomédicales.
-
Jeux de données de référence pour l'évaluation : LLaVA-Med, ainsi que d'autres modèles, sont évalués sur différents jeux de données, avec des benchmarks spécifiques tels que VQA-RAD, SLAKE et PathVQA, qui testent la capacité du modèle à répondre visuellement à des questions en radiologie, en pathologie, et plus encore.
-
Résultats de l'affinage supervisé : Le tableau présente les résultats des expériences d'affinage supervisées avec différentes méthodes :
| Méthode | VQA-RAD (Réf) | VQA-RAD (Ouvert) | VQA-RAD (Fermé) | SLAKE (Réf) | SLAKE (Ouvert) | SLAKE (Fermé) | PathVQA (Réf) | PathVQA (Ouvert) | PathVQA (Fermé) |
|---|---|---|---|---|---|---|---|---|---|
| LLaVA | 50,00 | 65,07 | 78,18 | 63,22 | 7,74 | 63,20 | |||
| LLaVA-Med (LLaVA) | 61,52 | 84,19 | 83,08 | 85,34 | 37,95 | 91,21 | |||
| LLaVA-Med (Vicuna) | 64,39 | 81,98 | 84,71 | 83,17 | 38,87 | 91,65 | |||
| LLaVA-Med (BioMed) | 64,75 | 83,09 | 87,11 | 86,78 | 39,60 | 91,09 |
Description des métriques :
-
Méthode : Ceci indique la version ou l'approche spécifique du modèle qui est évaluée. Il englobe diverses itérations et sources de LLaVA et LLaVA-Med.
-
VQA-RAD (Réf, Ouvert, Fermé) : Métriques pour la réponse visuelle à une question en radiologie. 'Réf' fait référence au score de référence, 'Ouvert' au score des questions ouvertes et 'Fermé' au score des questions fermées.
-
SLAKE (Réf, Ouvert, Fermé) : Métriques pour le benchmark SLAKE. 'Réf' représente le score de référence, 'Ouvert' correspond au score des questions ouvertes et 'Fermé' est pour le score des questions fermées. Please provide the French translation for this markdown file. If there is a frontmatter, make sure you translate language parameter to the matching fr as well. For the code, do not translate code, only translate comments. Do not translate the content of sample prompt. Here is the file: 4. PathVQA (Ref, Open, Closed): Metrics related to Pathology Visual Question Answering. 'Ref' indicates the reference score, 'Open' stands for the open-ended questions score, and 'Closed' signifies the closed-ended questions score.
Reference: Research Source (opens in a new tab)
By juxtaposing LLaVA-Med's results derived from various methods, it's evident that the model exhibits formidable performance in visual biomedical interpretations, especially when evaluated against benchmarks like VQA-RAD and SLAKE. This proficiency underscores its potential in aiding medical professionals in making more informed decisions based on visual data.
2. LLaVA-Med's Proficiency in Instruction-Following:
Originating from the extensive LLaVA model, LLaVA-Med's expertise is pronounced due to its tailored emphasis on biomedical nuances.
-
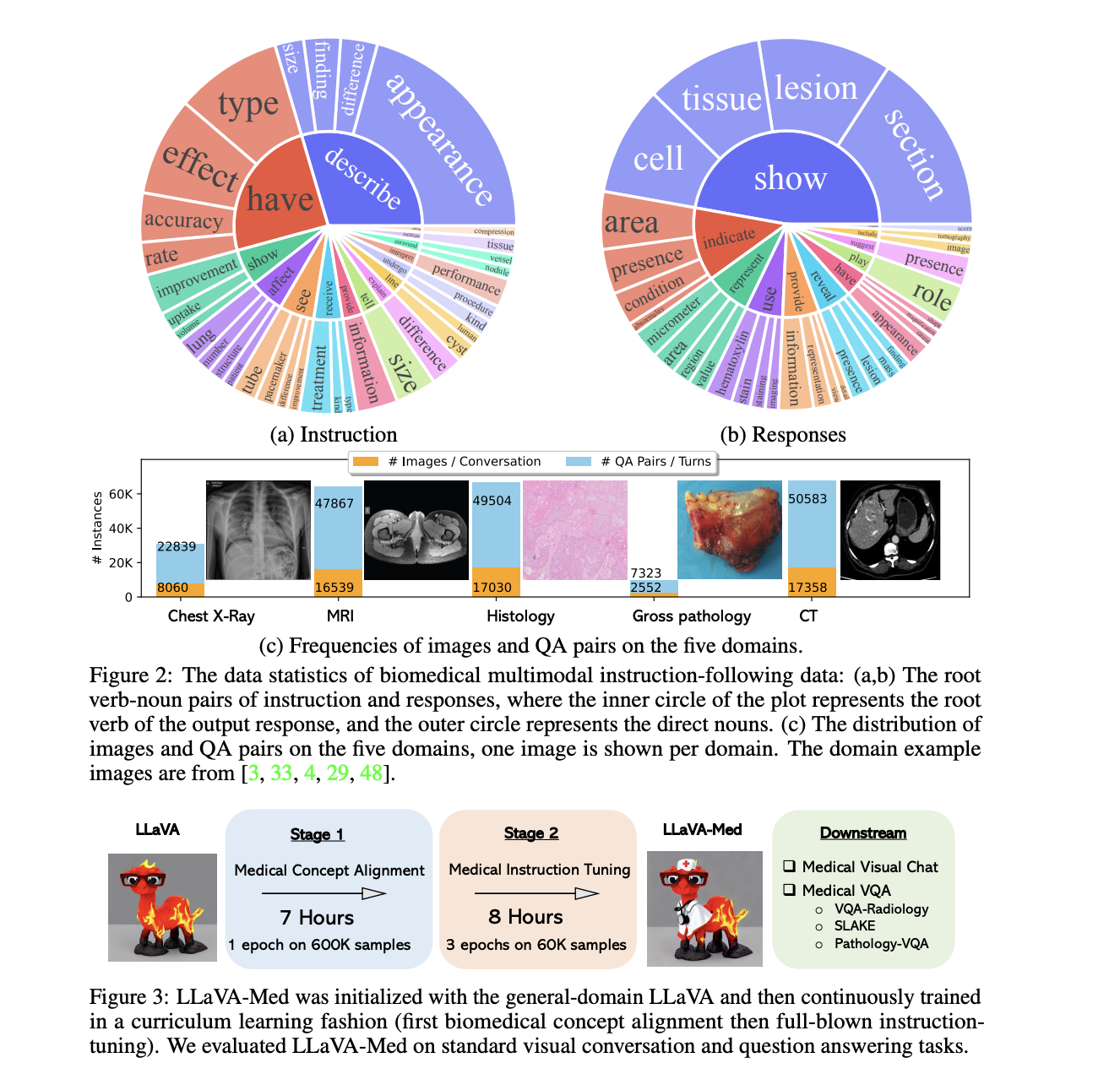
Dataset for Model Refinement: LLaVA-Med's enhancement utilized the Biomedical multimodal instruction-following dataset. Encompassing diverse real-world biomedical contexts, this dataset ensures LLaVA-Med's adeptness in medical knowledge articulation and comprehension.
-
Insights into the Dual-Phase Adaptation:
- Phase 1 (Biomedical Concept Integration): This foundational phase was crucial. It was directed at merging LLaVA's comprehensive knowledge with distinct biomedical concepts. This step ensured the subsequent refinement was in line with medical intricacies.
- Phase 2 (Comprehensive Instructional Tuning): A pivotal juncture, this stage subjected the model to intensive training on biomedical directives, fortifying its ability to intuitively understand, engage, and address medical contexts.
Comparative Performance of LLaVA versus LLaVA-Med:
| Model Iteration | Conversation (%) | Description (%) | CXR (%) | MRI (%) | Histology (%) | Gross (%) | CT (%) | Cumulative (%) |
|---|---|---|---|---|---|---|---|---|
| LLaVA | 39.4 | 26.2 | 41.6 | 33.4 | 38.4 | 32.9 | 33.4 | 36.1 |
| LLaVA-Med Phase 1 | 22.6 | 25.2 | 25.8 | 19.0 | 24.8 | 24.7 | 22.2 | 23.3 |
| LLaVA-Med Phase 2 | 52.4 | 49.1 | 58.0 | 50.8 | 53.3 | 51.7 | 52.2 | 53.8 |
Metric Descriptions:
-
Model Iteration: Désigne l'itération ou la phase spécifique du modèle en cours d'examen. Il comprend l'ensemble LLaVA englobant LLaVA-Med post la phase principale et post la phase secondaire.
-
Conversation (%): Une mesure mettant en évidence la compétence du modèle à maintenir un dialogue contextuel et à fournir des réponses pertinentes.
-
Description (%): Un indicateur de la capacité du modèle à élucider de manière approfondie les images médicales, garantissant que les détails transmis sont précis.
-
CXR (%): Dédié à l'évaluation de l'exactitude de LLaVA-Med lors de l'interprétation des radiographies thoraciques, un outil indispensable dans les diagnostics cliniques.
-
MRI (%): Mesure l'aptitude du modèle à analyser et à expliquer les résultats de l'imagerie par résonance magnétique. Les IRM, avec leurs aperçus détaillés, sont essentiels pour le diagnostic médical et les décisions thérapeutiques.
-
Histology (%): Un reflet de l'efficacité du modèle dans l'examen minutieux des études histologiques microscopiques, essentielles pour identifier les irrégularités cellulaires.
-
Gross (%): Une mesure de la capacité de LLaVA-Med à élucider les structures anatomiques visibles à l'œil nu, sans assistance microscopique.
-
CT (%): Évalue la précision du modèle dans l'interprétation des scanners tomographiques informatisés, connus pour leurs visuels corporels complets et en coupe transversale.
-
Cumulative (%): Un score consolidé, englobant les performances du modèle dans diverses catégories.
Reference: Source de recherche (opens in a new tab)
3. LLaVA-Med Visual Chatbot, en termes simples:
LLaVA-Med n'est pas seulement bon avec les mots; il est aussi très doué pour comprendre les images.
-
Bon dans de nombreux domaines: LLaVA-Med en sait beaucoup sur les différentes images médicales. Il peut regarder des images, des radiographies aux IRM et même des images de tissus minuscules.
-
Beaucoup de données: Ce qui le rend si bon? Il a vu et appris à partir de nombreuses images et textes. Ainsi, il sait des choses comme les radiographies, les scanners corporels et même les simples images du corps.
-
Utilisations dans le monde réel: Pensez aux médecins qui regardent des centaines de radiographies. LLaVA-Med peut aider en vérifiant rapidement ces images, en signalant les problèmes et en facilitant le travail du médecin.
-
Comparaison avec GPT-4: GPT-4 est bon avec les mots. Mais quand il s'agit de comprendre les images médicales et d'en parler, LLaVA-Med fait un meilleur travail. Il peut regarder une image médicale et en parler en détail.
-
Ce n'est pas parfait: Comme tout, LLaVA-Med a ses limites. Parfois, il peut se tromper si une image est trop différente de ce qu'il connaît. Mais à mesure qu'il voit plus d'images, il peut apprendre et s'améliorer.
Vous pouvez tester une version en ligne de LLaVA-Med ici (opens in a new tab).
Comment installer LLaVA-Med: Étape par étape
Mettre en place LLaVA-Med nécessite quelques étapes de plus que le modèle polyvalent LLaVA, compte tenu de sa nature spécialisée. Voici comment procéder:
Étape 1: Lancement du référentiel LLaVA-Med
Clonage simplifié:
Démarrez les choses en clonant le référentiel LLaVA-Med. Ouvrez votre terminal et tapez:
git clone https://github.com/microsoft/LLaVA-Med.gitCette commande récupère tous les fichiers nécessaires directement depuis le référentiel Microsoft sur votre machine.
Étape 2: Plonger dans le répertoire LLaVA-Med
Essentiel du déplacement:
Après avoir cloné le référentiel, la prochaine étape consiste à changer de répertoire de travail. Voici comment procéder:
cd LLaVA-MedEn exécutant cette commande, vous vous positionnez au cœur du répertoire de LLaVA-Med, prêt à passer à la phase suivante.
Étape 3: Configuration de la base - Installation des packages
Une fondation construite sur des dépendances
Chaque logiciel complexe est livré avec son lot de dépendances. LLaVA-Med ne fait pas exception. Avec la commande suivante, vous installerez tout ce dont il a besoin pour fonctionner correctement :
pip install -r requirements.txtN'oubliez pas que ce n'est pas seulement une question d'installation de packages. Il s'agit de créer un environnement propice pour que LLaVA-Med puisse mettre en valeur ses capacités.
Étape 4: Interagir avec LLaVA-Med
Lancer des exemples pour voir la magie :
Prêt pour l'action ? Commencez par intégrer le modèle LLaVA-Med dans votre script Python :
from LLaVAMed import LLaVAMedLancez le modèle :
model = LLaVAMed()Plongez-vous dans une analyse de texte médical :
text_output = model.analyze_medical_text("Décrivez les symptômes de la pneumonie.")
print(text_output)Et pour ceux qui s'intéressent à l'analyse d'images médicales :
image_output = model.analyze_medical_image("chemin/vers/radiographie.jpg")
print(image_output)L'exécution de ces commandes révèle les capacités analytiques de LLaVA-Med. Par exemple, l'analyse de texte médical peut mettre en lumière les symptômes, les facteurs causaux et les traitements potentiels de la pneumonie. D'autre part, l'analyse d'image peut détecter d'éventuelles anomalies ou différences sur la radiographie. Vous pouvez consulter le code source GitHub de LLaVA-Med (opens in a new tab).
Conclusion
Bien que l'IA en imagerie médicale montre un immense potentiel en termes de précision et d'efficacité, elle n'en est pas encore au stade où elle peut complètement remplacer les médecins. La technologie est un outil puissant pour faciliter le diagnostic, mais elle nécessite la supervision et l'expérience d'un professionnel de la santé pour fournir des soins fiables et holistiques. Par conséquent, l'accent devrait être mis sur la création d'un environnement de collaboration où l'IA et l'expertise humaine peuvent coexister pour offrir la meilleure qualité de soins.
Envie de connaître les dernières actualités sur LLM ? Consultez le dernier classement LLM !
