A Era dos Modelos de Linguagem Grandes de 1-bit: Microsoft Apresenta o BitNet b1.58
Published on
Introdução
Pesquisadores da Microsoft apresentaram uma nova variante revolucionária de Modelos de Linguagem Grandes (LLMs) de 1-bit chamada BitNet b1.58, em que cada parâmetro do modelo é ternário, assumindo valores de 1. Esse LLM de 1.58-bit iguala o desempenho de LLMs Transformer de precisão total (FP16 ou BF16) com o mesmo tamanho de modelo e tokens de treinamento, enquanto sendo significativamente mais econômico em termos de latência, uso de memória, taxa de transferência e consumo de energia. O BitNet b1.58 representa um avanço importante para tornar os LLMs tanto com alto desempenho quanto altamente eficientes.

O que é o BitNet b1.58?
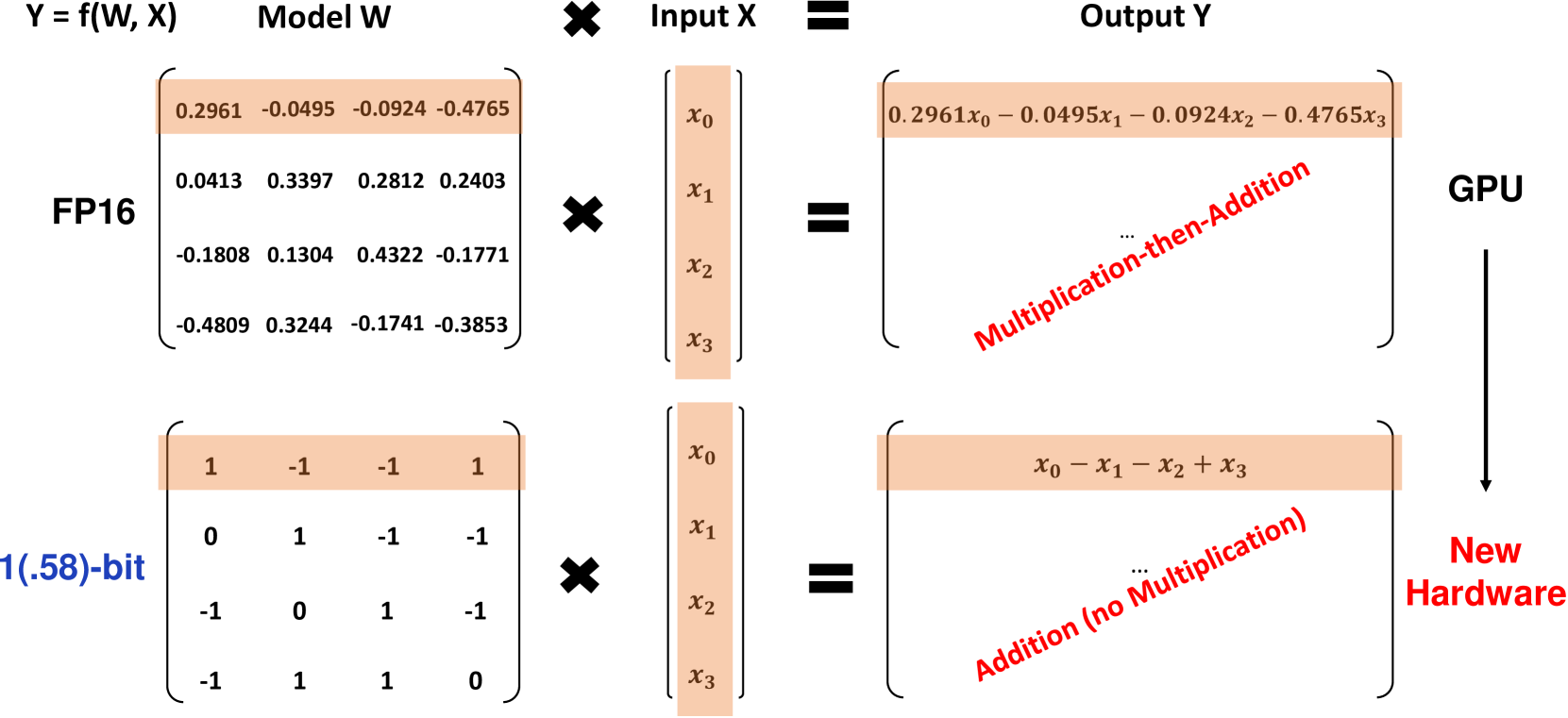
O BitNet b1.58 baseia-se na arquitetura original do BitNet, um modelo Transformer que substitui as camadas padrão nn.Linear por camadas BitLinear. Ele é treinado do zero com pesos de 1.58-bit e ativações de 8-bit. Comparado ao BitNet de 1-bit original, o b1.58 introduz algumas modificações importantes:
-
Ele usa uma função de quantização absmean para restringir os pesos a 1. Isso arredonda cada peso para o inteiro mais próximo entre esses valores após a escala pelo valor absoluto médio.
-
Para as ativações, ele as dimensiona para o intervalo [-sa, sa] por token, simplificando a implementação em comparação com o BitNet original.
-
Ele adota componentes da arquitetura LLaMA de código aberto popular, incluindo RMSNorm, ativações SwiGLU, incorporação rotativa e remove os vieses. Isso permite uma integração fácil com software LLM existente.
A adição do valor 0 aos pesos possibilita a filtragem de características, aumentando a capacidade de modelagem em comparação com modelos puramente de 1-bit. Experimentos mostraram que o BitNet b1.58 iguala as baselines FP16 em perplexidade e desempenho final a partir de um tamanho de parâmetro de 3B.
Resultados de Desempenho
Os pesquisadores compararam o BitNet b1.58 a uma baseline FP16 LLM LLaMA reproduzida em vários tamanhos de modelo, de 700M a 70B parâmetros. Ambos foram pré-treinados no mesmo conjunto de dados RedPajama por 100B tokens e avaliados em perplexidade e uma variedade de tarefas de linguagem sem treinamento específico.
As principais conclusões incluem:
-
O BitNet b1.58 iguala a perplexidade da baseline FP16 LLaMA em tamanho 3B, enquanto é 2,71 vezes mais rápido e usa 3,55 vezes menos memória da GPU.
-
Um BitNet b1.58 de 3,9B supera o LLaMA de 3B em perplexidade e tarefas finais com menor latência e custo de memória.
-
Em tarefas de linguagem sem treinamento específico, a diferença de desempenho entre o BitNet b1.58 e o LLaMA diminui à medida que o tamanho do modelo aumenta, com o BitNet igualando o LLaMA no tamanho de 3B.
-
Ampliando para 70B, o BitNet b1.58 alcança um aumento de velocidade de 4,1 vezes em relação à baseline FP16. As economias de memória também aumentam com a escala.
-
O BitNet b1.58 usa 71,4 vezes menos energia para multiplicação de matrizes. A eficiência energética de ponta a ponta aumenta com o tamanho do modelo.
-
Em duas GPUs A100 de 80GB, um BitNet b1.58 de 70B suporta tamanhos de lote 11 vezes maiores do que o LLaMA, permitindo uma taxa de transferência 8,9 vezes maior.
Os resultados demonstram que o BitNet b1.58 oferece uma melhoria de Pareto em relação aos LLMs FP16 de última geração - é mais eficiente em termos de latência, memória e energia, ao mesmo tempo que iguala a perplexidade e desempenho das tarefas finais em uma escala suficiente. Por exemplo, um BitNet b1.58 de 13B é mais eficiente do que um LLM FP16 de 3B, um BitNet de 30B é mais eficiente do que um FP16 de 7B e um BitNet de 70B é mais eficiente do que um modelo FP16 de 13B.
Quando treinado em 2T tokens seguindo a receita StableLM-3B, o BitNet b1.58 superou o StableLM-3B de zero-shot em todas as tarefas avaliadas, mostrando uma forte generalização.
As tabelas abaixo fornecem dados mais detalhados sobre as comparações de desempenho entre o BitNet b1.58 e a baseline FP16 LLaMA:
| Modelos | Tamanho | Memória (GB) | Latência (ms) | PPL |
|---|---|---|---|---|
| LLaMA LLM | 700M | 2,08 (1,00x) | 1,18 (1,00x) | 12,33 |
| BitNet b1.58 | 700M | 0,80 (2,60x) | 0,96 (1,23x) | 12,87 |
| LLaMA LLM | 1,3B | 3,34 (1,00x) | 1,62 (1,00x) | 11,25 |
| BitNet b1.58 | 1,3B | 1,14 (2,93x) | 0,97 (1,67x) | 11,29 |
| LLaMA LLM | 3B | 7,89 (1,00x) | 5,07 (1,00x) | 10,04 |
| BitNet b1.58 | 3B | 2,22 (3,55x) | 1,87 (2,71x) | 9,91 |
| BitNet b1.58 | 3,9B | 2,38 (3,32x) | 2,11 (2,40x) | 9,62 |
Tabela 1: Comparação de perplexidade e custo entre BitNet b1.58 e LLaMA LLM.
| Modelos | Tamanho | ARCe | ARCc | HS | BQ | OQ | PQ | WGe | Média |
|---|---|---|---|---|---|---|---|---|---|
| LLaMA LLM | 700M | 54,7 | 23,0 | 37,0 | 60,0 | 20,2 | 68,9 | 54,8 | 45,5 |
| BitNet b1.58 | 700M | 51,8 | 21,4 | 35,1 | 58,2 | 20,0 | 68,1 | 55,2 | 44,3 |
| LLaMA LLM | 1,3B | 56,9 | 23,5 | 38,5 | 59,1 | 21,6 | 70,0 | 53,9 | 46,2 |
| BitNet b1.58 | 1,3B | 54,9 | 24,2 | 37,7 | 56,7 | 19,6 | 68,8 | 55,8 | 45,4 |
| LLaMA LLM | 3B | 62,1 | 25,6 | 43,3 | 61,8 | 24,6 | 72,1 | 58,2 | 49,7 |
| BitNet b1.58 | 3B | 61,4 | 28,3 | 42,9 | 61,5 | 26,6 | 71,5 | 59,3 | 50,2 |
| BitNet b1.58 | 3,9B | 64,2 | 28,7 | 44,2 | 63,5 | 24,2 | 73,2 | 60,5 | 51,2 |
Tabela 2: Precisão em tarefas finais de BitNet b1.58 e LLaMA LLM.
A latência de decodificação e o consumo de memória do BitNet b1.58 em diferentes tamanhos de modelo estão mostrados na Figura 1. O aumento de velocidade aumenta com o tamanho do modelo, chegando a 4,1 vezes com 70B de parâmetros em comparação com a baseline FP16. As economias de memória também aumentam com a escala.
Consulte a legenda Consulte a legenda Figura 1: Latência de decodificação (esquerda) e consumo de memória (direita) do BitNet b1.58 em diferentes tamanhos de modelo. Em termos de eficiência energética, o BitNet b1.58 usa 71,4 vezes menos energia para multiplicação de matrizes em comparação com os LLMs FP16. O custo energético de ponta a ponta em diferentes tamanhos de modelo é ilustrado na Figura 2, mostrando que o BitNet b1.58 se torna cada vez mais eficiente em escalas maiores.
Consultar legenda
Consultar legenda
Figura 2: Consumo de energia do BitNet b1.58 em comparação com o LLaMA LLM. Esquerda: Componentes da energia das operações aritméticas. Direita: Custo energético de ponta a ponta em diferentes tamanhos de modelo.
O throughput é outra vantagem chave do BitNet b1.58. Com duas GPUs A100 de 80GB, um BitNet b1.58 de 70B suporta tamanhos de lote 11 vezes maiores do que um LLaMA LLM de 70B, resultando em um throughput 8,9 vezes maior, conforme mostrado na Tabela 3.
| Modelos | Tamanho | Tamanho Máximo de Lote | Throughput (tokens/s) |
|---|---|---|---|
| LLaMA LLM | 70B | 16 (1,0x) | 333 (1,0x) |
| BitNet b1.58 | 70B | 176 (11,0x) | 2977 (8,9x) |
Tabela 3: Comparação do throughput entre o BitNet b1.58 de 70B e o LLaMA LLM.
Implicações e Direções Futuras
A arquitetura e os resultados do BitNet b1.58 têm implicações significativas para o futuro dos LLMs:
-
Isso estabelece uma nova fronteira de Pareto e uma lei de escala para LLMs que são tanto de alto desempenho quanto altamente eficientes. LLMs de 1,58 bits podem ser comparáveis às baselines FP16 com custos de inferência dramaticamente mais baixos.
-
A redução drástica de memória permite a execução de LLMs muito maiores em uma determinada quantidade de hardware. Isso é especialmente impactante para arquiteturas intensivas em memória, como a mistura de especialistas.
-
Ativações de 8 bits podem dobrar o comprimento do contexto possível com um determinado orçamento de memória em comparação com 16 bits. Compressão adicional para 4 bits ou menos é possível no futuro.
-
A eficiência excepcional de LLMs de 1,58 bits em dispositivos de CPU abre a possibilidade de implantação de LLMs poderosos em dispositivos de borda/móveis, onde CPUs são o principal processador.
-
O novo paradigma de baixa bitagem de computação do BitNet b1.58 motiva o design de aceleradores de IA personalizados e sistemas otimizados especificamente para LLMs de 1 bit, para aproveitar ao máximo o potencial.
A Microsoft vê os LLMs de 1 bit como um caminho altamente promissor para tornar os LLMs dramaticamente mais eficientes em termos de custo, preservando suas capacidades. Eles vislumbram uma era em que os modelos de 1 bit alimentem aplicações desde o data center até a borda. No entanto, alcançar esse futuro exigirá um co-design das arquiteturas dos modelos, hardware e sistemas de software para aproveitar totalmente as propriedades únicas desses modelos. O BitNet b1.58 estabelece um ponto de partida empolgante para esta nova era de LLMs.
Conclusão
O BitNet b1.58 representa uma grande descoberta ao levar modelos de linguagem grandes até o limite da quantização, ao mesmo tempo que preserva o desempenho. Ao utilizar pesos ternários 1 e ativações de 8 bits, ele iguala os LLMs FP16 em perplexidade e desempenho final com uso de memória, latência e consumo de energia dramaticamente menores.
A arquitetura de 1,58 bits estabelece uma nova fronteira de Pareto para LLMs, onde modelos maiores podem ser executados a uma fração do custo. Isso abre novas possibilidades, como suporte nativo a contextos mais longos, implantação de LLMs poderosos em dispositivos de borda e motiva o design de hardware personalizado para IA de baixa bitagem.
O trabalho da Microsoft demonstra que LLMs agressivamente quantizados não são apenas viáveis, mas estabelecem uma lei de escala superior em comparação com modelos FP16. Com um maior co-design de arquiteturas, hardware e software, os LLMs de 1 bit têm o potencial de impulsionar o próximo grande salto em capacidades de IA com custo efetivo, da nuvem à borda. O BitNet b1.58 fornece um ponto de partida impressionante para esta nova e empolgante era de modelos de linguagem grandes ultraeficientes.