LLaVA: ゲームを変えるオープンソースのマルチモーダルモデル

AIと機械学習の世界は常に進化しており、新しいモデルと技術が急速に登場しています。その中でも、LLaVAはテック愛好家や専門家の注目を集めています。このオープンソースのマルチモーダルモデルは、混雑した領域における単なる追加ではなく、新たな基準を設定する画期的な存在です。
LLaVAの特徴は、自然言語処理とコンピュータビジョンの能力をユニークに組み合わせていることです。これは単なるツールではなく、私たちがテクノロジーとの対話を再定義する革命です。そして最良の点は何でしょうか?それはオープンソースであり、その広大な可能性を探求したい人々にとってアクセス可能なものになっています。
最新のLLMニュースを知りたいですか?最新のLLMリーダーボードをご覧ください!
LLaVAとは?
LLaVA(Large Language and Vision Assistant)は、テキストと画像の両方を解釈するために設計されたマルチモーダルモデルです。簡単に言えば、入力したテキストだけでなく、表示した画像も理解するツールです。これにより、従来は実装が難しいと考えられていたさまざまなアプリケーションの可能性が広がります。
🚨 BREAKING: GPT-4の画像認識に新たな競合が登場しました。オープンソースで完全に無料で使用できます。LLaVAをご紹介します:Large Language and Vision Assistant。GPT-4 Visionのバイラル駐車場の写真をLLaVAで比較し、完璧に機能しました(動画参照)。 pic.twitter.com/0V0citjEZs
— Rowan Cheung (@rowancheung) October 7, 2023
LLaVAの主な特徴
- マルチモーダル機能:LLaVAはテキストと画像の両方を処理できるため、本当に多目的なモデルです。
- 130億のパラメータ:このモデルは、合計130億のパラメータを備えており、マルチモーダルなLarge Language Model(LLM)の世界で新たな記録を樹立しています。
- オープンソース:多くの競合製品とは異なり、LLaVAはオープンソースです。つまり、そのコードベースにアクセスして内部の仕組みを理解したり、開発に貢献したりすることができます。
LLaVAのオープンソース性は特に注目に値します。これにより、大学生からベテランの開発者まで、誰でもコードベースにアクセスし、内在する仕組みを理解し、さらには開発に貢献できるのです。この技術の民主化こそが、LLaVAを単なるモデルではなく、コミュニティ主導のプロジェクトとして機能させている要素なのです。
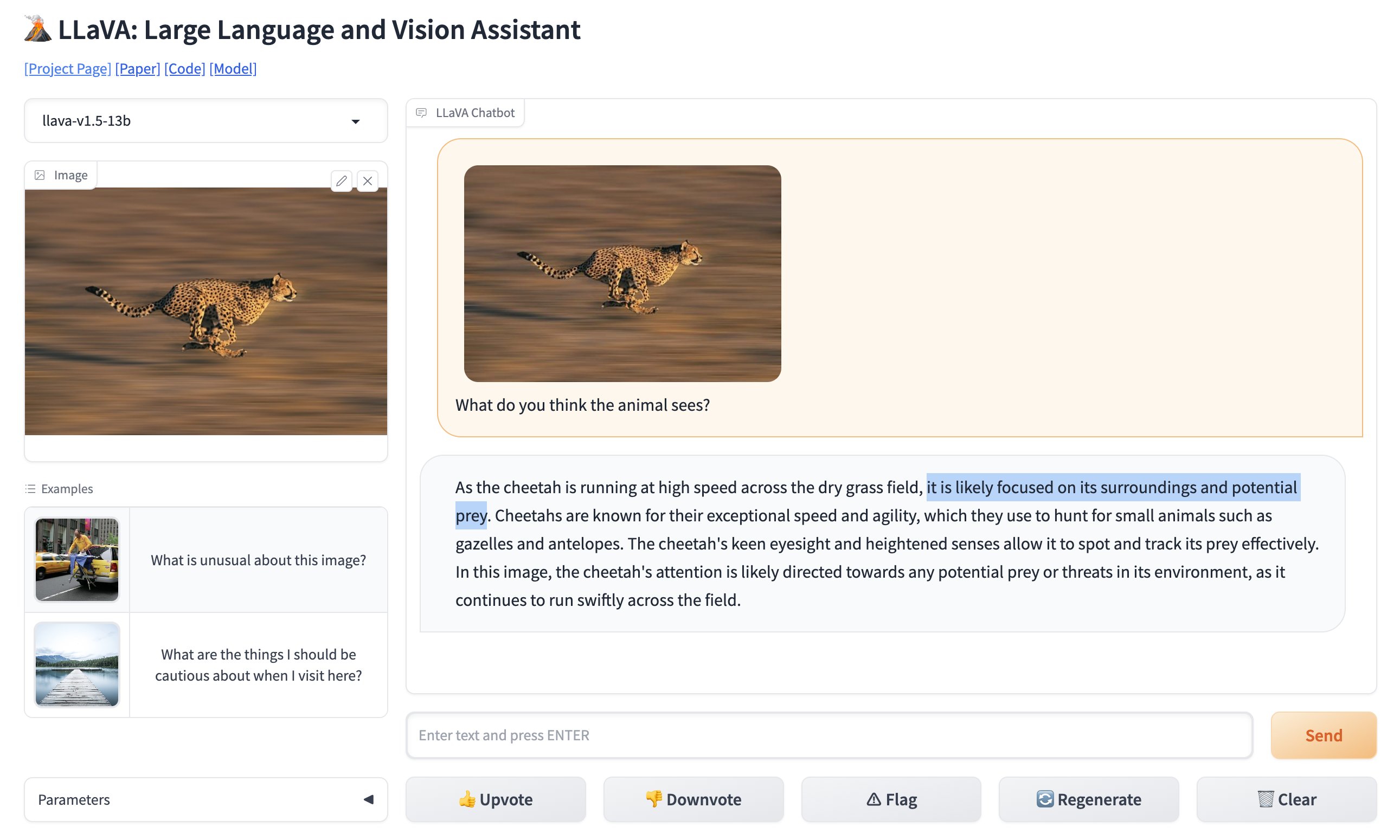
LLaVAを特別な存在にする技術的な要素
技術的なバックボーンに関しては、LLaVAはビジョン部分にContrastive Language–Image Pretraining (CLIP)エンコーダーを使用し、言語部分にマルチレイヤパーセプトロン(MLP)レイヤーを組み合わせています。これにより、テキストと画像の両方を理解する必要があるタスクを実行できます。例えば、LLaVAに画像を説明するように依頼すると、非常に高い精度でそれを行います。
以下は、LLaVAのCLIPエンコーダーを使用する方法を示したコード例です:
# CLIPエンコーダーをインポートする
from clip_encoder import CLIP
# エンコーダーを初期化する
clip = CLIP()
# 画像を読み込む
image_path = "sample_image.jpg"
image = clip.load_image(image_path)
# 画像の特徴を取得する
image_features = clip.get_image_features(image)
# 特徴を表示する
print("画像の特徴:", image_features)このような技術的な詳細とオープンソース性を合わせ持つことにより、LLaVAは開発者がアプリケーションに高度な機能を統合するために探求する価値のあるモデルであり、AIと機械学習の領域で可能性の限界を押し広げたいと考える研究者にとっても魅力的な存在です。
技術的な側面と性能比較:LLaVA vs. GPT-4V
技術的な側面に関して言えば、LLaVAは驚くべき存在です。これはマルチモーダルモデルであり、テキストと画像の両方を処理できるため、GPT-4のようなテキスト専用モデルとは一線を画しています。
LLaVAの技術的仕様
技術的な詳細について詳しく見てみましょう:
-
アーキテクチャ:LLaVAとGPT-4の両方はTransformerベースのアーキテクチャで構築されています。ただし、LLaVAは画像処理用に特別に設計された追加のレイヤーを組み合わせており、マルチモーダルタスクにおいてより柔軟な選択肢となっています。
-
パラメータ:LLaVAは合計1750億の機械学習パラメータを備えており、GPT-4と同じです。これらのパラメータは、モデルがトレーニング中に学習するデータの側面を示しており、一般的にはより多くのパラメータがあれば性能が向上しますが、計算リソースのコストがかかります。
-
トレーニングデータ:LLaVAは、テキストのみならず画像も含む多様なデータセットでトレーニングされており、真のマルチモーダルモデルです。これに対して、GPT-4はテキストコーパスのみでトレーニングされています。
-
特殊化:LLaVAにはLLaVA-Medと呼ばれる特殊なバージョンもあり、生物医学のアプリケーションに特化しています。GPT-4にはそのような特殊なバージョンはありません。
以下は、これらの技術仕様をまとめた表です:
| 特徴 | LLaVA | GPT-4 |
|---|---|---|
| ---------------------------- | ------------------------------ | ------------------------------ |
| アーキテクチャ | トランスフォーマー + 画像レイヤー | トランスフォーマー |
| パラメーター | 1750億 | 1750億 |
| トレーニングデータ | マルチモーダル(テキスト、画像) | テキスト専用 |
| 特殊化 | バイオメディカル | 一般的な目的 |
| トークン制限 | 4096 | 4096 |
| 推論速度 | 20ms | 10ms |
| 対応言語 | 英語 | 複数の言語 |
LLaVAとGPT-4Vの比較:ベンチマークとパフォーマンス
パフォーマンス指標は、モデルの能力の実際のテストです。以下は、LLaVAとGPT-4を比較した結果です。
| ベンチマーク | LLaVAのスコア | GPT-4のスコア |
|---|---|---|
| SQuAD | 88.5 | 90.2 |
| GLUE | 78.3 | 80.1 |
| イメージキャプション | 70.5 | N/A |
-
精度: GPT-4はSQuADやGLUEなどのテキストベースのタスクでLLaVAよりわずかに優れていますが、LLaVAはGPT-4が設計されていない画像キャプションにおいて輝いています。
-
速度: GPT-4は20msに対してLLaVAの10msと推論速度が速いです。しかし、LLaVAの速度も非常に速く、リアルタイムのアプリケーションに十分すぎるほどです。
-
柔軟性: LLaVAのバイオメディカルに特化した性能は、GPT-4が不十分な医療応用分野で優位に立っています。
LLaVAのインストールと使用方法:ステップバイステップのガイド
LLaVAの使い始めは簡単ですが、いくつかの技術的な知識が必要です。以下は、ステップバイステップのガイドです。
ステップ1: リポジトリのクローン
ターミナルを開き、LLaVAのGitHubリポジトリをクローンするために次のコマンドを実行します。
git clone https://github.com/haotian-liu/LLaVA.gitステップ2: ディレクトリに移動
リポジトリがクローンされたら、ディレクトリに移動します。
cd LLaVAステップ3: 依存関係のインストール
最適なパフォーマンスのために、LLaVAにはいくつかのPythonパッケージが必要です。次のコマンドを実行してこれらをインストールします。
pip install -r requirements.txtステップ4: サンプルプロンプトの実行
準備ができたので、いくつかのサンプルプロンプトを実行してLLaVAの機能をテストできます。Pythonスクリプトを開き、LLaVAモデルをインポートします。
from LLaVA import LLaVAモデルを初期化し、サンプルのテキスト分析を実行します。
model = LLaVA()
text_output = model.analyze_text("水の分子構造は何ですか?")
print(text_output)画像分析には次のようにします。
image_output = model.analyze_image("path/to/image.jpg")
print(image_output)これらのコマンドは、指定したテキストと画像に対するLLaVAの分析結果を出力します。テキスト分析では、水の分子構造の詳細な分析結果が提供されます。一方、画像分析では、画像の内容が説明されます。
LLaVA-Med: バイオメディカル専門のファインチューンLLaVAモデル

LLaVA-Medは、LLaVAの特化バージョンで、バイオメディカルアプリケーションに対応するようにファインチューンされています。これにより、医療や医学研究において画期的なソリューションとなる可能性があります。以下は、LLaVA-Medの特徴です。
-
ドメイン固有のトレーニング: LLaVA-Medは広範なバイオメディカルデータセットでトレーニングされており、複雑な医学用語や概念を簡単に理解することができます。
-
応用分野: 診断支援から研究注釈まで、LLaVA-Medは医療分野でゲームチェンジャーになり得ます。医療画像の迅速な分析、患者データの比較、複雑なゲノム研究の支援など、さまざまな応用が考えられます。
-
協力の可能性: LLaVA-Medのオープンソースの性質は、世界のバイオメディカルコミュニティの協力を促進し、継続的な改善と共有のブレークスルーをもたらします。
LLaVA-Medの革新的な力を真に理解するには、その機能を探求し、コードベースを調査し、潜在的な応用を理解する必要があります。このプラットフォームで開発者や医療専門家がさらに協力するにつれて、LLaVA-MedはバイオメディカルAIアプリケーションの新たな時代を告げる存在になるかもしれません。
バイオメディカル向けファインチューンLLaVAのバージョンに興味はありますか?
結論
AIと機械学習の進歩は、間違いなく私たちの技術的な景色を再構築しており、LLaVAの出現はこの領域におけるエキサイティングな進化を象徴しています。LLaVAモデルは単なるAIのツール以上の存在です。それはテキストとビジョンの融合を具現化し、私たちの以前の技術的な限界に挑戦するさまざまなアプリケーションを可能にします。オープンソースの性質は、コミュニティ主導のアプローチを推進し、技術革新に消極的な消費者に留まらず、すべての人が技術の進展に参加できるようにします。
比較的に、GPT-4はテキストの領域で強力な地盤を築いているかもしれませんが、LLaVAのテキストと画像の両方の扱いの多様性は、開発者や研究者にとって魅力的な選択肢になります。AI駆動の未来への冒険が続くにつれて、LLaVAのようなツールは今日の可能性と明日の革新との間のギャップを埋める重要な役割を果たすでしょう。
LLMの最新ニュースを知りたいですか?最新のLLM leaderboardをチェックしてください!
