Zephyr-7b:言語モデルの新たなフロンティア

人工知能の進歩に目を注いでいるなら、おそらくZephyr-7bについて聞いたことがあるでしょう。これはただの言語モデルではありません。AIの領域における画期的な進歩です。チャットボット以上のものとして設計されたZephyr-7bは、パフォーマンス、効率性、実用性の新たな基準を築いています。
AIが私たちの日常生活にますます統合される世界で、オープンソース人工知能の未来がもたらす可能性を象徴する存在として、Zephyr-7bが際立っています。開発者、テクノロジーエンスージアスト、AIの最先端に興味を持つ人々にとって、この記事はZephyr-7bの理解を深めるための包括的なガイドとなるでしょう。
最新のLLMニュースを知りたいですか?最新のLLMランキングをチェックしてください:/llm-leaderboard!
Zephyr-7bとは?
Zephyr-7bは、その前任であるMistral-7B-v0.1から改良された言語モデルです。ただのモデルではありません。役立つアシスタントとして機能するように設計されています。しかし、それを他のモデルとは何か違うものにしているのは何でしょうか?その答えは、その訓練方法である「Direct Preference Optimization (DPO)」にあります。この技術により、Zephyr-7bはこれまで以上にパフォーマンスが向上し、より役立つ存在になりました。
- モデルタイプ:7BパラメータのGPTライクモデル
- 対応言語:主に英語
- ライセンス:CC BY-NC 4.0
Zephyr-7bの独自の特徴
Zephyr-7bを他のチャットボットと異なる存在にしているのは、その独自の特徴です。役立つ、効率的、そして非常に多目的に使えるように設計されています。
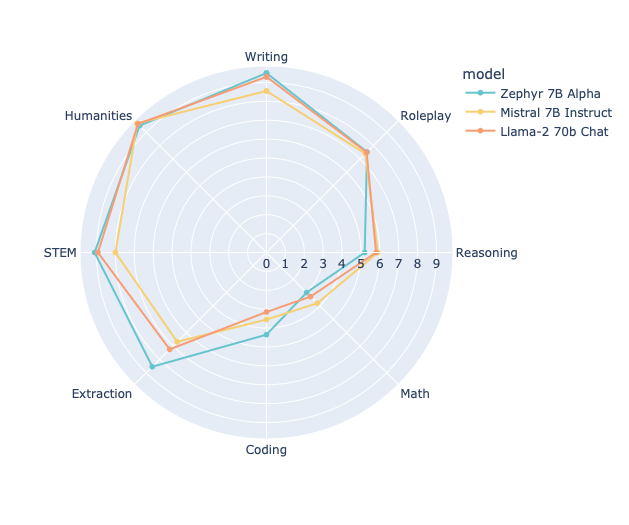
- MTベンチにおけるパフォーマンス:Zephyr-7bは、llama2-70bなどの他のモデルを上回る優れたパフォーマンスを示しています。
- トレーニングデータ:モデルは、公開されているデータと合成データのミックスでトレーニングされており、堅牢さと多機能性を持っています。
- コスト効率:トレーニングの合計計算コストは約500ドルで、パワフルで経済的です。
Direct Preference Optimization (DPO)の役割
DPOは、Zephyr-7bの形成において重要なトレーニング手法です。他のトレーニング手法とは異なり、DPOはモデルの応答を人間の好みにより近づけることに焦点を当てています。これにより、ベンチマークで優れたパフォーマンスを発揮するだけでなく、実用性でも優れているモデルが生まれました。
次のコードスニペットは、Zephyr-7bでDPOがどのように機能するかをイメージすることができます:
import torch
from transformers import pipeline
pipe = pipeline("text-generation", model="HuggingFaceH4/zephyr-7b-alpha", torch_dtype=torch.bfloat16, device_map="auto")
messages = [
{
"role": "system",
"content": "You are a friendly chatbot who always responds in the style of a pirate",
},
{"role": "user", "content": "How many helicopters can a human eat in one sitting?"},
]
prompt = pipe.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])Zephyr-7bの技術仕様:知っておくべきこと
Zephyr-7bの優れた性能を理解するためには、技術仕様が重要です。このセクションでは、言語モデルの密集した領域でこのモデルを際立たせる詳細について掘り下げます。
モデルタイプとパラメータ
Zephyr-7bは、7,000,000,000のパラメータを持つGPTライクモデルです。言語モデルの世界では、パラメータの数がモデルの複雑さと能力の指標となります。
- モデルタイプ:GPTライクで7Bのパラメータ
- 対応言語:主に英語
- ライセンス:CC BY-NC 4.0
トレーニングデータと方法論:Zephyr-7bの基盤
Zephyr-7bの最も興味深い側面の1つは、そのトレーニングデータと方法論です。他のモデルが公開されているデータだけに頼るのとは異なり、Zephyr-7bは公開されているデータと合成データのミックスでトレーニングされています。この多様なトレーニングデータは、堅牢性と多機能性に貢献しています。
- トレーニングデータ:公開データと合成データのミックス
- トレーニング方法論:Direct Preference Optimization (DPO)
以下は、使用されたトレーニングハイパーパラメータの概要です:
- 学習率:5e-07
- トレーニングバッチサイズ:2
- 評価バッチサイズ:4
- シード:42
- オプティマイザ:ベータ=(0.9,0.999)およびイプシロン=1e-08のAdam
評価指標:数字は偽らない
Zephyr-7bは、その能力をテストするために厳密な評価を受けています。モデルはさまざまな評価指標で評価されており、その数値は非常に印象的です。
- 損失:0.4605
- 報酬/選択された回数:-0.5053
- 報酬/拒否された回数:-1.8752
- 報酬/正答率:0.7812
- 報酬/マージン:1.3699
これらの評価指標は、モデルのパフォーマンスを検証するだけでなく、優れている点や改善の余地がある点を示しています。
Zephyr-7bの始め方:ステップバイステップガイド
Zephyr-7bに興奮しているのであれば、どのように手に入れるかを知りたいかもしれません。それでは、運が良いです!このセクションでは、この画期的なモデルを始めるための手順をご案内します。
リポジトリとデモ:始めるための出発点
まず、公式のリポジトリとデモをチェックする必要があります。これらのプラットフォームは、Zephyr-7bにダイブするために必要なすべてのリソースを提供します。
Zephyr-7b の実行: 必要とするコード
Zephyr-7bを実行するには、Transformersのpipeline()関数を使用することで、簡単なプロセスです。以下は、モデルを実行する方法を示すサンプルコードです。
from transformers import pipeline
import torch
# パイプラインを初期化
pipe = pipeline("text-generation", model="HuggingFaceH4/zephyr-7b-alpha", torch_dtype=torch.bfloat16, device_map="auto")
# メッセージのプロンプトを作成
messages = [
{"role": "system", "content": "あなたはフレンドリーなチャットボットです。"},
{"role": "user", "content": "ジョークを教えてください。"},
]
# 応答を生成
prompt = pipe.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
# 生成されたテキストを表示
print(outputs[0]["generated_text"])Zephyr-7bの実際のアプリケーションと制限事項
技術的な詳細に迷い込むことは簡単ですが、任意の言語モデルの真のテストは実際のアプリケーションです。 Zephyr-7bも例外ではなく、実用性を考慮して設計されています。
チャットと会話インタフェース
Zephyr-7bの主な応用の一つは、チャットと会話インタフェースです。このモデルは、UltraChatデータセットのバリアントで微調整されており、さまざまな会話シナリオを処理することに優れています。カスタマーサービスボットやインタラクティブなゲームを構築する場合でも、Zephyr-7bはあなたをカバーしてくれます。
テキスト生成とコンテンツ作成
Zephyr-7bが輝く別の領域は、テキスト生成です。記事の自動生成、ウェブサイトの動的な応答の作成、さらにはコードの作成まで、Zephyr-7bのテキスト生成の機能はタスクに対応しています。
制限事項: 注意が必要な点
Zephyr-7bは強力なツールですが、その制限事項を認識することが重要です。RLHFなどの手法を使用して人間の好みに合わせて調整することがないため、適切に管理されていない場合に問題のある出力を生成する可能性があります。実世界のアプリケーションでZephyr-7bを展開する際には、十分なフィルタリングメカニズムを常に確保してください。
Zephyr-7b の将来: 次のステップは?
私たちは将来を見据えながら、Zephyr-7bはまさに始まりに過ぎないことが明らかです。継続的な研究と開発により、このモデルのさらに高度なバージョンが期待されており、言語モデルの領域で可能なものの境界をさらに em> em> em> em> em> em> em> em>まで押し広げることができます。
今後の機能と改善
現在のZephyr-7bのバージョンは印象的ですが、いくつかの機能と改良が進行中です。これには、以下が含まれますが、これに限定されません:
- 人間らしい対話のための改善されたアラインメント技術
- 英語以外の複数の言語への展開
- 複雑なクエリとタスクのより堅牢な処理
広い影響: 新たな基準を打ち立てる
Zephyr-7bはただのモデルではありません。これはオープンソースAIの世界で可能なことの声明です。パフォーマンス、効率性、ユーティリティにおいて新たな基準を設定することで、Zephyr-7bは将来のモデルを作り出し、人工知能の景観を形作っています。
結論: Zephyr-7b の重要性
言語モデルで溢れかえる世の中で、Zephyr-7bは革新と実用性の灯台として際立っています。独自のトレーニング方法から多様な応用範囲まで、このモデルはAIの分野でゲームチェンジャーです。
高度なAIをプロジェクトに統合したい開発者であるか、最新の進歩を探求したいテクノロジーエンスージアストであるかにかかわらず、Zephyr-7bは誰にでも何かを提供します。その技術的な能力、実世界での応用、将来のポテンシャルは、探求する価値のあるモデルです。
オープンソースAIの未来に飛び込む準備ができているなら、Zephyr-7bはあなたの切符です。革命をお見逃しなく。今日からZephyr-7bで始めましょう!
最新のLLMニュースを知りたいですか?最新の LLM リーダーボードをチェックしてください!
