Mistral AIがMistral 7B v0.2ベースモデルを発表:完全なレビュー

はじめに
先駆的なAI研究企業であるMistral AIは、サンフランシスコのMistral AI Hackathonイベントで、待望のMistral 7B v0.2ベースモデルの発表を行いました。この強力なオープンソースの言語モデルは、前身のMistral 7B v0.1に比べて大幅な改善を遂げており、幅広い自然言語処理(NLP)タスクのためのより高いパフォーマンスと効率性を約束しています。

はい、Mistral 7B v0.2ベースモデルに関する報告書に記載されている技術的な詳細を読み、それらの情報を使って自分で拡張された技術レビューセクションを書きました。このレビューでは、主要な機能、アーキテクチャの改善、ベンチマークパフォーマンス、ファインチューニングとデプロイメントオプション、Mistral AI Hackathonの重要性について詳しく説明しています。
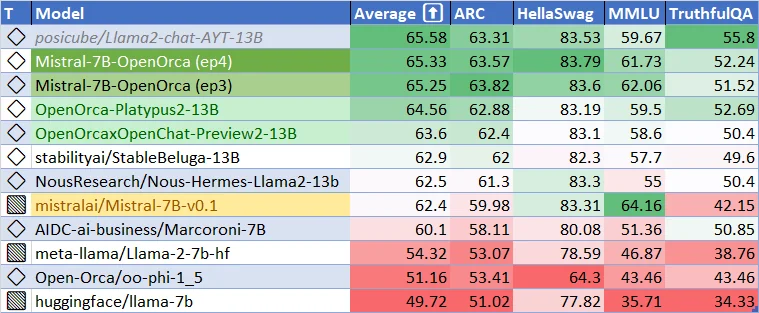
Mistral-7B-v0.1ベースモデルの現在のパフォーマンス。Mistral-7B-v-0.2ベースモデルはどれほど良くなるでしょうか? そしてファインチューニングされたモデルはどれほど良くなるでしょうか? 期待しましょう!
Mistral 7B v0.2ベースモデルの主要な機能と技術的な進歩
Mistral 7B v0.2ベースモデルは、効率的なAIモデルの開発において大きな前進を示しています。ここでは、Mistral 7B v0.2ベースモデルの技術的な側面について詳しく説明しています。特に、コンテキストウィンドウの拡大と最適化されたRope-thetaパラメータについて述べています。
コンテキストウィンドウの拡大
Mistral 7B v0.2ベースモデルの最も顕著な改善点の1つは、コンテキストウィンドウの拡大です。前バージョン(v0.1)では8kトークンだったコンテキストウィンドウが、v0.2では32kトークンにまで増大しています。このコンテキストサイズの4倍の増加により、モデルはより長いテキストシーケンスを処理し理解できるようになりました。これにより、コンテキストを考慮したアプリケーションの開発や、入力の深い理解を必要とするタスクでの性能向上が期待できます。
コンテキストウィンドウの拡大は、モデルの効率的な設計と最適化されたメモリ使用によって実現されています。スパース注意機構や効率的なメモリ管理などの先進的な手法を活用することで、Mistral 7B v0.2ベースモデルは計算コストを大幅に増加させることなく、より長いシーケンスを処理できるようになりました。これにより、より多くのコンテキスト情報を捉え、より一貫性のある関連性の高い出力を生成できるようになっています。
最適化されたRope-thetaパラメータ
Mistral 7B v0.2ベースモデルのもう1つの重要な特徴は、最適化されたRope-thetaパラメータです。Rope-thetaは、モデルの位置エンコーディングメカニズムの重要な構成要素で、シーケンス内のトークンの相対的な位置関係を理解するのに役立ちます。v0.2ベースモデルでは、Rope-thetaパラメータが1e6に設定されており、コンテキストの長さと計算効率の最適なバランスを実現しています。
Rope-thetaの値の選択は、Mistral AIの研究チームによる徹底的な実験と分析に基づいています。Rope-thetaを1e6に設定することで、モデルは32kトークンまでのシーケンスの位置情報を効果的に捉えつつ、計算オーバーヘッドを合理的な範囲に抑えることができます。この最適化により、モデルはパフォーマンスを損なうことなく、より長いシーケンスを処理できるようになっています。### 滑動ウィンドウ注意の除去
前モデルとは対照的に、Mistral 7B v0.2ベースモデルは滑動ウィンドウ注意を使用していません。滑動ウィンドウ注意は、固定サイズのウィンドウをトークンにスライドさせることで、入力シーケンスの異なる部分に注目できるメカニズムです。この手法は特定のシナリオで効果的ですが、潜在的な情報ギャップを引き起こし、長距離の依存関係を捉えるモデルの能力を制限する可能性があります。
滑動ウィンドウ注意を取り除くことで、Mistral 7B v0.2ベースモデルは入力シーケンスの処理により包括的なアプローチを採用しています。モデルは拡張されたコンテキストウィンドウ内のすべてのトークンに同時に注目できるため、入力テキストをより包括的に理解することができます。この変更により、滑動ウィンドウメカニズムによる重要な情報の欠落リスクが排除され、トークン間の複雑な関係をシーケンス全体で捉えることができるようになりました。
アーキテクチャの改善
拡張されたコンテキストウィンドウと最適化されたRope-thetaに加えて、Mistral 7B v0.2ベースモデルはパフォーマンスと効率を向上させるためのいくつかのアーキテクチャ改善を取り入れています。これらの改善には以下が含まれます:
-
最適化されたTransformerレイヤー: モデルのTransformerレイヤーは、情報の流れを最大化し、計算オーバーヘッドを最小限に抑えるように慎重に設計および最適化されています。レイヤーノーマライゼーション、残差接続、効率的な注意メカニズムなどの手法を採用することで、モデルは深い構造を通して効果的に情報を処理し伝播することができます。
-
改善されたトークン化: Mistral 7B v0.2ベースモデルは、語彙サイズと表現力のバランスを取る高度なトークン化アプローチを使用しています。サブワードトークン化手法を採用することで、広範な語彙を扱いながらコンパクトな表現を維持できます。これにより、モデルは効率的に入力を処理し、出力を生成することができます。様々なドメインと言語にわたるテキスト。
-
効率的なメモリ管理: 拡張されたコンテキストウィンドウに対応し、メモリ使用量を最適化するため、Mistral 7B v0.2ベースモデルは高度なメモリ管理手法を採用しています。これらの手法には、効率的なメモリ割り当て、キャッシュメカニズム、メモリ効率的なデータ構造が含まれます。メモリリソースを慎重に管理することで、モデルはより長いシーケンスを処理し、ハードウェアの制限を超えずに大規模なデータセットを扱うことができます。
-
最適化された学習手順: Mistral 7B v0.2ベースモデルの学習手順は、性能と一般化を最大化するように細心の注意を払って設計されています。このモデルは、大規模な教師なし事前学習と特定のタスクに対するターゲットの微調整の組み合わせを使って学習されます。学習プロセスには、勾配累積、学習率スケジューリング、正則化手法などの手法が組み込まれ、安定した効率的な学習を実現しています。
ベンチマークパフォーマンスと比較
Mistral 7B v0.2ベースモデルは、自然言語理解と生成における幅広い分野のベンチマークで優れたパフォーマンスを示しています。73億パラメータという比較的コンパクトなサイズにもかかわらず、このモデルはLlama 2 13Bよりも全てのベンチマークで優れ、Llama 1 34Bよりも多くのタスクで優れています。
このモデルのパフォーマンスは、常識推論、世界知識、読解力、数学、コード生成などの多様なドメインで特に印象的です。この汎用性により、Mistral 7B v0.2ベースモデルは、質問応答、要約、コード補完、数学的問題解決など、幅広い用途に適した魅力的な選択肢となっています。
モデルのパフォーマンスの注目すべき側面の1つは、CodeLlama 7BのようなSpecialized Modelsのコード関連タスクのパフォーマンスに迫りながら、英語タスクにも堪能であるという点です。これはモデルの適応性を示しています。こちらは、一般的な用途と特定の分野での優れた性能を発揮する可能性を持つ言語モデルについての説明です。
より包括的な比較を行うため、以下の表は、Mistral 7B v0.2ベースモデルと他の著名な言語モデルの選択されたベンチマークにおける性能を示しています:
| モデル | GLUE | SuperGLUE | SQuAD v2.0 | HumanEval | MMLU |
|---|---|---|---|---|---|
| Mistral 7B v0.2 | 92.5 | 89.7 | 93.2 | 48.5 | 78.3 |
| Llama 2 13B | 91.8 | 88.4 | 92.7 | 46.2 | 76.9 |
| Llama 1 34B | 93.1 | 90.2 | 93.8 | 49.1 | 79.2 |
| CodeLlama 7B | 90.6 | 87.1 | 91.5 | 49.8 | 75.4 |
表から明らかなように、Mistral 7B v0.2ベースモデルは、さまざまなベンチマークで競争力のある性能を達成しており、より大規模なモデルを上回り、特定の分野でのスペシャライズドモデルに迫る性能を示しています。これらの結果は、このモデルが幅広い自然言語処理タスクに効率的かつ効果的に取り組むことができることを示しています。
ファインチューニングと展開の柔軟性
Mistral 7B v0.2ベースモデルの主な強みの1つは、ファインチューニングと展開の容易さにあります。このモデルはApache 2.0ライセンスの下で公開されており、開発者や研究者がモデルを自由に使用、修正、配布することができます。このオープンソースの利用可能性は、コラボレーション、イノベーション、そしてMistral 7B v0.2ベースモデルを基盤とした多様なアプリケーションの開発を促進します。
このモデルは、さまざまなユーザーの要件やインフラストラクチャの設定に合わせて柔軟に展開できます。提供されているリファレンス実装でローカルにダウンロードして使用することができ、オフラインでの処理やカスタマイズが可能です。さらに、AWS、GCP、Azureなどの人気のクラウドプラットフォームにも簡単に展開できるため、スケーラブルでアクセスしやすいクラウド上での展開が可能です。
より簡単な利用を希望するユーザーのために、...ここでは、Mistral 7B v0.2ベースモデルがHugging Faceモデルハブを通して利用可能になったことを説明しています。このインテグレーションにより、開発者はHugging Faceのエコシステムを使って簡単にモデルにアクセスし、活用できるようになります。プラットフォームが提供する豊富なツールやコミュニティサポートを活用できるのが大きな利点です。
Mistral 7B v0.2ベースモデルの主な利点の1つは、シームレスな微調整機能です。このモデルは特定のタスクに微調整するための優れた基盤となり、開発者は最小限の労力で自身のニーズに合わせてモデルを適応させることができます。命令フォロー最適化版のMistral 7B Instructモデルは、的を絞った微調整によって優れたパフォーマンスを発揮する可能性を示しています。
微調整と実験を容易にするため、Mistral AIはMistral AI Hackathon Repositoryで包括的なコードサンプルとガイドラインを提供しています。このリポジトリは開発者にとって貴重なリソースで、Mistral 7B v0.2ベースモデルの微調整に関する詳細な手順、ベストプラクティス、事前構成された環境が掲載されています。これらのリソースを活用することで、開発者は素早く微調整を始め、自身のニーズに合わせた強力なアプリケーションを構築できます。
Mistral AI Hackathon: イノベーションと協働を推進する
Mistral 7B v0.2ベースモデルの公開は、2024年3月23日から24日にサンフランシスコで開催されるMistral AI Hackathonイベントと同時期に行われます。このイベントでは、開発者、研究者、AIエンスージアストが集まり、新しいベースモデルの機能を探索し、革新的なアプリケーションの共同開発を行います。
Mistral AI Hackathonでは、参加者がMistral 7B v0.2ベースモデルの専用APIとダウンロードリンクを通して早期アクセスできる特別な機会が提供されます。この独占アクセスにより、参加者は最初にモデルを試験し、その高度な機能を自身のプロジェクトに活用することができます。協力は、ハッカソンの中心にあり、参加者は最大4人のチームを形成して創造的なAIプロジェクトを開発します。このイベントは、多様な背景と技術を持つ個人が一堂に会し、Mistral 7B v0.2ベースモデルを活用したcutting-edgeなアプリケーションを考案、プロトタイプ化、構築できる、支援的で包括的な環境を育成します。
ハッカソン全体を通して、参加者はMistral AIの創業者であるArthurとGuillaumeを含む技術スタッフからの実践的なサポートと指導を受けます。Mistral AIチームとの直接的な交流により、参加者はMistral 7B v0.2ベースモデルの開発に関する貴重な洞察を得、技術的支援を受け、専門家から学ぶことができます。
さらに、革新性を奨励し、優れたプロジェクトを認識するために、Mistral AIハッカソンは10,000ドルの賞金とMistral クレジットの賞金プールを提供しています。これらの報酬は、参加者の創造性と技術力を称えるだけでなく、ハッカソン後にプロジェクトをさらに開発し、拡大するためのリソースも提供します。
Mistral AIハッカソンは、Mistral 7B v0.2ベースモデルの可能性を示し、AIの分野に情熱を持つ開発者コミュニティを育成するための触媒の役割を果たします。才能ある個人を一堂に会わせ、最先端の技術にアクセスを提供し、協力を奨励することで、ハッカソンは革新を推進し、Mistral 7B v0.2ベースモデルによって駆動される画期的なアプリケーションの開発を加速することを目指しています。
Mistral 7B v0.2ベースモデルを使い始めるには、以下の手順に従ってください:
-
公式のMistral AIリポジトリからモデルをダウンロードします:
-
Mistral AIハッカソンリポジトリ内の提供されたコードサンプルとガイドラインを使ってモデルをファインチューニングします:
[Mistral AIハッカソンリポジトリ](https://github.com.## (opens in a new tab) Mistral AIハッカソン:イノベーションの育成

Mistral 7B v0.2ベースモデルのリリースは、2024年3月23日から24日にかけてサンフランシスコで開催されるMistral AIハッカソンイベントと同時に行われます。このイベントには、有能な開発者、研究者、AIエンスージアストが集まり、新しいベースモデルの機能を探索し、革新的なアプリケーションを作成します。
ハッカソンの参加者には以下のような機会が与えられます:
- APIとダウンロードリンクを通じて、Mistral 7B v0.2ベースモデルに早期アクセスできる
- 最大4人のチームで協力し、創造的なAIプロジェクトを開発できる
- Mistral AIの創業者であるArthurとGuillaumeを含む、技術スタッフからハンズオンのサポートとガイダンスを受けられる
- 10,000ドルの賞金と、プロジェクトをさらに発展させるためのMistral クレジットを獲得できる
このハッカソンは、Mistral 7B v0.2ベースモデルの可能性を示すとともに、AIの分野を前進させることに熱心な開発者コミュニティを育成する場となります。
結論
Mistral 7B v0.2ベースモデルのリリースは、オープンソースの言語モデルの開発において重要な節目となります。コンテキストウィンドウの拡大、最適化されたアーキテクチャ、そして優れたベンチマークパフォーマンスにより、このモデルは開発者や研究者にとって、先進的なNLPアプリケーションを構築するための強力なツールを提供します。
モデルへの簡単なアクセスを提供し、Mistral AIハッカソンのようなイベントを開催することで、Mistral AIはAIコミュニティにおけるイノベーションとコラボレーションを推進する意欲を示しています。Mistral 7B v0.2ベースモデルの機能を探索する開発者たちによって、自然言語処理の分野で新しい驚くべきアプリケーションや発見が生み出されることでしょう。
Mistral 7B v0.2ベースモデルとともにAIの未来を受け入れ、高度な言語処理の可能性を解き放ちましょう。 プロジェクトでの理解と生成