Groq AIがLLMクエリを10倍高速化する方法

ジェネレーティブAIソリューション企業のGroqは、その革新的な言語処理ユニット(LPU)インファレンスエンジンで、大規模言語モデル(LLM)インファレンスの景観を再定義しています。この目的別に設計されたアクセラレーターは、従来のCPUおよびGPUアーキテクチャの限界を克服し、LLM処理における前例のないスピードと効率を実現しています。
最新のLLMニュースを知りたいですか? 最新のLLMリーダーボードをチェックしてください!

LPUアーキテクチャ: 深掘り
Groqのコアとなるのは、シーケンシャルなパフォーマンスを重視するシングルコアデザインのLPUです。このアプローチにより、LPUは1チップあたり1ペタフロップ/秒の最高パフォーマンスを達成する高密度コンピューティングを実現しています。LPUの独自のアーキテクチャは、220MBのオンチップSRAMを組み込むことで外部メモリのボトルネックを排除し、1.5TB/sものメモリ帯域幅を提供しています。
LPUの同期ネットワーク機能により、大規模な展開でも seamless なスケーラビリティを実現しています。LPU 1台あたり 1.6TB/sの双方向帯域幅を持つことで、Groqの技術はLLMインファレンスに必要な大量のデータ転送を効率的に処理できます。さらに、LPUはFP32からINT4まで幅広い精度レベルをサポートし、低精度設定でも高精度を維持できます。
Groqのパフォーマンスベンチマーク
Groqのコアとなるのは、シーケンシャルなパフォーマンスを重視するシングルコアデザインのLPUです。このアプローチにより、LPUは1チップあたり1ペタフロップ/秒の最高パフォーマンスを達成する高密度コンピューティングを実現しています。LPUの独自のアーキテクチャは、220MBのオンチップSRAMを組み込むことで外部メモリのボトルネックを排除し、1.5TB/sものメモリ帯域幅を提供しています。以下は、提供されたマークダウンファイルの日本語翻訳です。コードについては、コメントのみ翻訳しています。ファイルの先頭に追加のコメントは付けていません。
Groqのベンチマーク Meta AIのLlama-2 70Bモデルに対して行った内部テストでは、Groqが1ユーザーあたり秒間300トークンという驚くべき速度を達成しました。これは、従来のGPUベースのシステムを大きく上回るLLMの推論速度の飛躍的な向上を示しています。
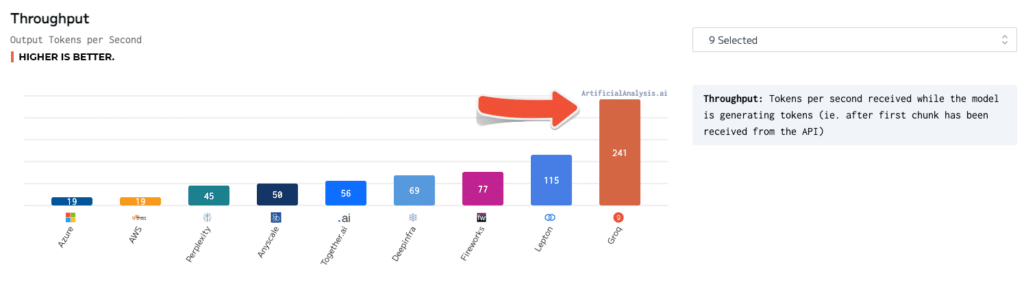
独立したベンチマークでも、Groqの優位性が確認されています。ArtificialAnalysis.aiが行ったテストでは、Groqのllama 2 Chat (70B) APIが秒間241トークンの処理能力を発揮し、他のホスティングプロバイダーの2倍以上の速度を記録しました。Groqはレイテンシーvsスループット、総応答時間、スループットのばらつきなどの主要なパフォーマンス指標でも優れた結果を示しました。
これらの数値を具体的な場面で考えてみましょう。AIチャットボットとユーザーが対話する場合、Groqのlpu推論エンジンにより、チャットボットは秒間300トークンの速度で応答を生成できます。これにより、ほぼ即時の会話が可能になります。一方、GPUベースのシステムでは、50-100トークン/秒程度しか達成できず、明らかな遅延が生じ、ユーザー体験が損なわれます。
Groqと他のAI技術の比較

NVIDIA GPUと比較すると、Groqのlpuはint8パフォーマンスで明確な優位性を示しています。これはLLM推論に不可欠です。llama-2 70Bモデルのベンチマークでは、lpuがA100 GPUの3.5倍の速度、秒間300トークンの処理能力を発揮しました。
Groqの技術はChatGPTやGoogleのGeminiなどの他のAIモデルにも勝る可能性があります。これらのモデルの具体的なパフォーマンス数値は公開されていませんが、Groqの実証された速度と効率性から、実用アプリケーションでの優位性が示唆されます。
Groq AIの活用
Groqは、デプロイを容易にするための包括的なツールとサービスを提供しています。以下は、日本語への翻訳版です。コードの部分は翻訳していません。
Groqの LPU技術の紹介と活用について。GroqWareスイート(Groq Compilerを含む)は、モデルを迅速に立ち上げるためのワンクリック体験を提供します。Groq Compilerを使ってモデルをコンパイルし実行する例は以下の通りです:
# モデルのコンパイル
groq compile model.onnx -o model.groq
# LPU上でモデルを実行
groq run model.groq -i input.bin -o output.binより高度なカスタマイズを求める場合、GroqではハンドコーディングによるGroq アーキテクチャへのアクセスも可能で、カスタマイズアプリケーションの開発や最大限のパフォーマンス最適化が行えます。簡単な行列乗算のGroqアセンブリコードの例は以下の通りです:
; Groq LPU上での行列乗算
; 行列A, Bがメモリにロードされていることを前提とする
; 行列サイズの読み込み
ld r0, [n]
ld r1, [m]
ld r2, [k]
; 結果行列Cの初期化
mov r3, 0
; Aの行ループ
mov r4, 0
loop_i:
; Bの列ループ
mov r5, 0
loop_j:
; 内積の計算
mov r6, 0
mov r7, 0
loop_k:
ld r8, [A + r4 * m + r7]
ld r9, [B + r7 * k + r5]
mul r10, r8, r9
add r6, r6, r10
add r7, r7, 1
cmp r7, r2
jlt loop_k
; 結果をCに格納
st [C + r4 * k + r5], r6
add r5, r5, 1
cmp r5, r2
jlt loop_j
add r4, r4, 1
cmp r4, r0
jlt loop_i開発者や研究者はGroqのパワフルな技術をGroq APIを通じてリアルタイムの推論機能にアクセスできます。Llama-2 70Bモデルを使ってテキストを生成する例は以下の通りです:
import groq
# Groqクライアントの初期化
client = groq.Client(api_key="your_api_key")
# モデルとパラメータの設定
model = "llama-2-70b"
prompt = "Once upon a time, in a land far, far away..."
max_tokens = 100
# テキスト生成
response = client.generate(model=model, prompt=prompt, max_tokens=max_tokens)
# 生成されたテキストの表示
print(response.text)潜在的な用途と影響GroqのLPUインフェレンスエンジンによる瞬時に近い応答時間は、さまざまな業界で新しい可能性を開いています。金融の分野では、Groqの技術を活用して、リアルタイムの不正検知や リスク評価を行うことができます。膨大な取引データを処理し、ミリ秒単位で異常を検出することで、金融機関は不正行為を防ぎ、顧客の資産を保護することができます。
医療の分野では、GroqのLPUが医療データのリアルタイム分析を可能にすることで、患者ケアを革新的に変えることができます。医療画像の処理から電子カルテの分析まで、Groqの技術は医療従事者が迅速かつ正確な診断を下すのを支援し、患者の転帰改善につながります。
自動運転車も、Groqの高速インファレンス機能から大きな恩恵を受けることができます。センサーデータの処理と瞬時の判断により、Groq搭載のAIシステムは自動運転車の安全性と信頼性を高め、知的な交通システムの実現に道を開きます。
結論
GroqのLPUインファレンスエンジンは、AIアクセラレーションの分野で大きな前進を示しています。革新的なアーキテクチャ、優れたベンチマーク、包括的なツールとサービスを備えたGroqは、大規模言語モデルの可能性を最大限に引き出すことができます。
リアルタイムのAIインファレンスに対する需要が高まる中、Groqは次世代のAI駆動型ソリューションを実現するリーディング企業として位置づけられています。チャットボットやバーチャルアシスタント、自律システムなど、Groqの技術の適用範囲は広く、変革的です。
AIアクセスの民主化と革新の促進に尽力するGroqは、技術的な景観を革新するだけでなく、人工知能との関わり方と恩恵を形作っています。AIの時代の扉を開く中で、Groqの画期的な技術は中心的な役割を果たすことが期待されています。未曾有の進歩と発見への触媒となることでしょう。
最新のLLMニュースを学びたいですか? 最新のLLMリーダーボードをチェックしてください!