画期的なSSM-Transformerモデル「Jamba」の紹介

AI21 Labsは、革命的なMambaアーキテクチャに基づく世界初の製品レベルのモデル「Jamba」を発表しました。Mambaの Structured State Space (SSM)テクノロジーと従来のTransformerアーキテクチャを巧みに融合することで、純粋なSSMモデルの限界を克服し、優れたパフォーマンスと効率性を実現しています。
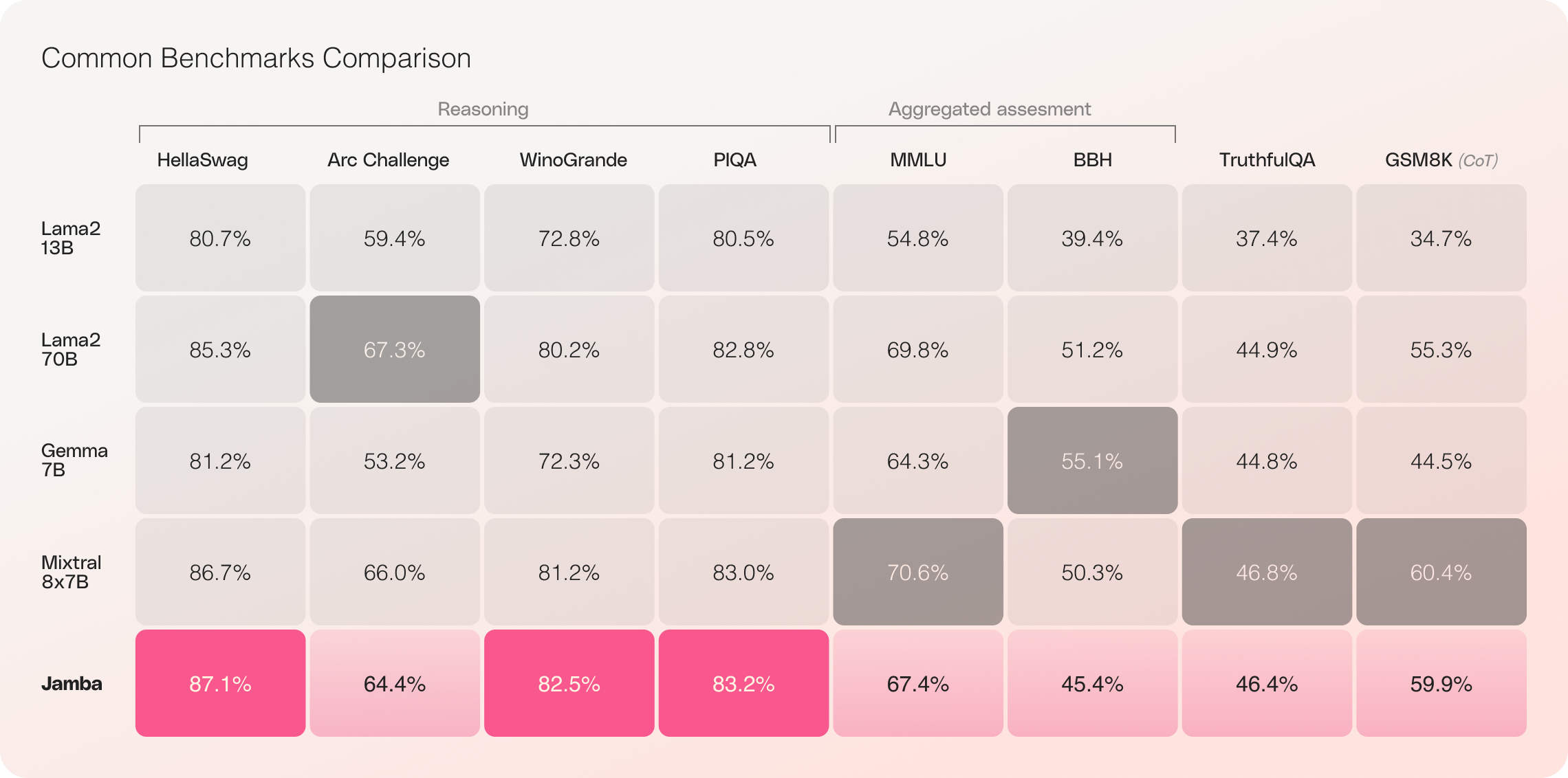
256Kものコンテキストウィンドウと驚くべきスループット向上を誇るJambaは、AI業界の地平を一新し、研究者、開発者、ビジネスユーザーに新たな可能性を開きます。Jambaは幅広いベンチマークで優れた結果を示し、同クラスの最先端モデルに匹敵する、あるいはそれを凌駕する性能を発揮しています。
TLDR: Jambaには安全性の調整メカニズムやガードレールがなく、Apache-2.0オープンソースライセンスを使用しています。

Jambaの主な特徴
- 世界初の製品レベルのMambaベースモデル: Jambaは、SSM-Transformerハイブリッドアーキテクチャを製品レベルの規模と品質で実現しています。
- 並外れたスループット: Jambaは、Mixtral 8x7Bに比べて長いコンテキストで3倍のスループットを達成し、効率性の新基準を打ち立てています。
- 大規模なコンテキストウィンドウ: 256Kものコンテキストウィンドウを持つJambaは、ウィンドウ、Jambaは広範なコンテキスト処理機能へのアクセスを民主化します。
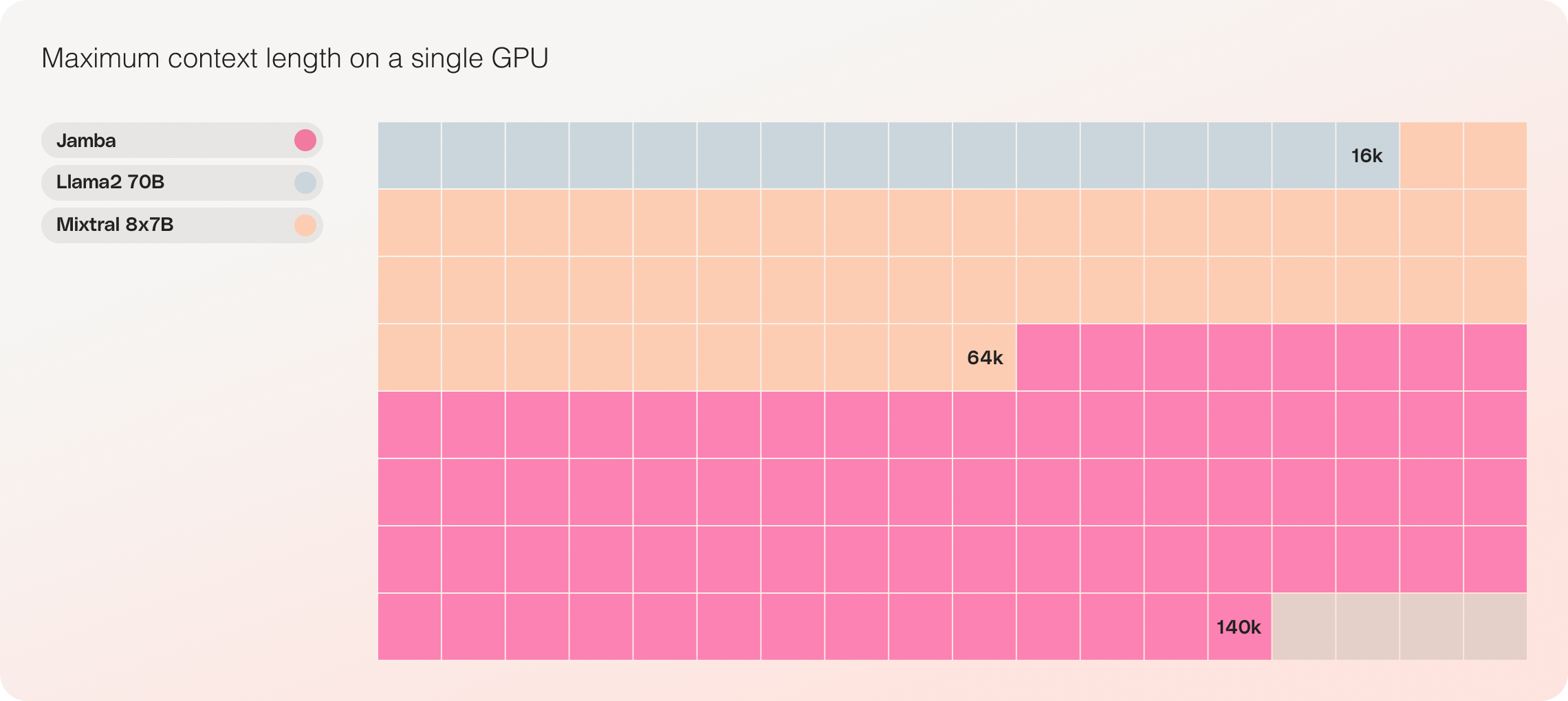
- 単一GPUの互換性: Jambaは、単一のGPUに最大140Kのコンテキストを収容できる唯一のモデルであり、展開と実験をより容易にします。
- オープンソースの利用可能性: Apache 2.0ライセンスの下でオープンな重みで公開されたJambaは、AIコミュニティからのさらなる最適化と発見を呼び起こします。
- 今後のNVIDIA APIカタログ統合: JambaはまもなくNVIDIA AIエンタープライズソフトウェアプラットフォームを使用してデプロイできるNVIDIA NIM推論マイクロサービスとしてNVIDIA APIカタログから利用可能になります。
Jamba: MambaとTransformer アーキテクチャの最良の組み合わせ
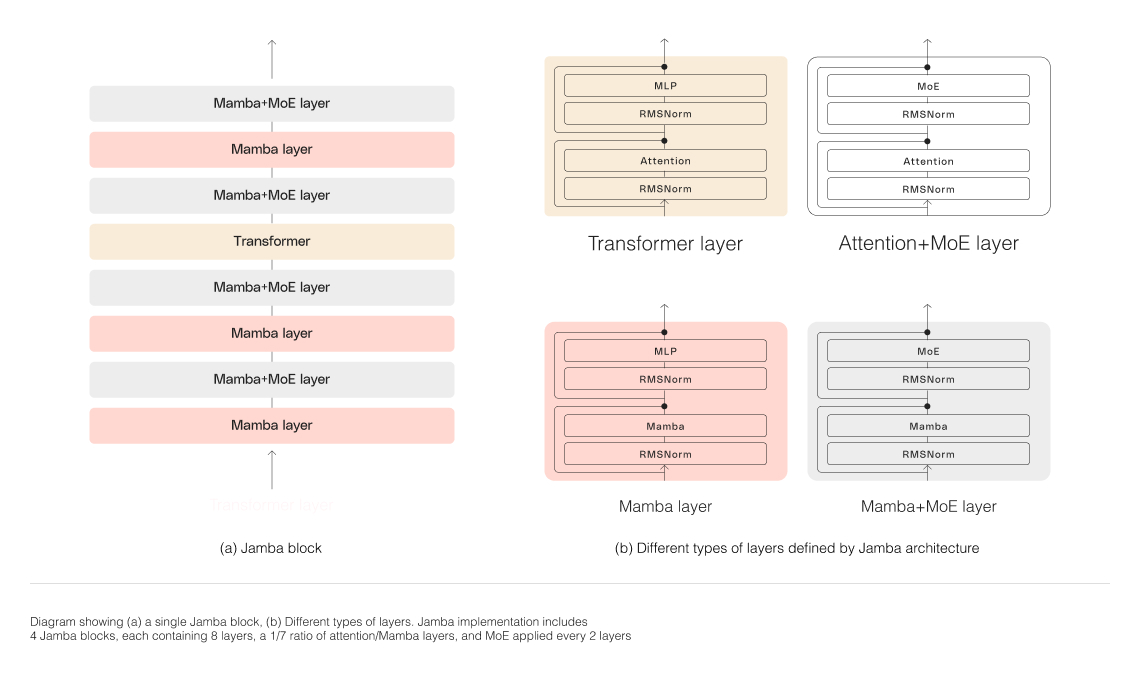
Jambaは、MambaをTransformer アーキテクチャに組み込み、ハイブリッドSSM-Transformerモデルを本番品質にスケーリングすることで、LLMイノベーションの重要なマイルストーンを表しています。
従来のTransformer ベースのLLMは2つの主要な課題に直面しています:
- 大きなメモリフットプリント: Transformerのメモリフットプリントはコンテキスト長に依存して増加するため、大量のハードウェアリソースなしでは長いコンテキストウィンドウや多数の並列バッチを実行するのが困難です。
- 長いコンテキストでの推論が遅い: Transformerの注意メカニズムは系列長に対して二次的にスケールするため、各トークンが前の全系列に依存するため、スループットが低下します。
Mambaは、カーネギーメロン大学とプリンストン大学の研究者によって提案されたものですが、これらの欠点に対処しています。ただし、全コンテキストにわたる注意がないため、特に再現率関連のタスクでは、最高の既存モデルの出力品質に匹敵するのが難しくなっています。

Jamba vs Mamba vs Transformerジャンバの複合アーキテクチャ、Transformerと Mambaおよび専門家の混合(MoE)層で構成されています。メモリ、スループット、パフォーマンスを同時に最適化しています。MoE層により、ジャンバは推論時に52Bパラメータの12Bしか使用しないため、同等サイズのTransformer単独モデルよりも効率的です。
ジャンバの複合アーキテクチャのスケーリング
ジャンバの複合構造を正常にスケーリングするために、AI21 Labsは以下のようなコアアーキテクチャの革新を実装しました:
-
ブロックとレイヤーのアプローチ: ジャンバのアーキテクチャはブロックとレイヤーのアプローチを採用し、Transformerとmambaアーキテクチャを seamlessly統合しています。各ジャンバブロックには注意層かMamba層が含まれ、その後にマルチレイヤーパーセプトロン(MLP)が続きます。全体としては8層に1つがTransformerレイヤーとなっています。
-
専門家の混合(MoE)の活用: MoE層を使うことで、ジャンバはモデルパラメータの総数を増やしつつ、推論時に使用するアクティブなパラメータ数を削減しています。これにより、計算要件の増加なしにモデル容量を高めることができます。MoEレイヤーと専門家の数は、単一の80GBGPUでモデルの品質とスループットを最大化しつつ、一般的な推論ワークロードのためのメモリを十分に残すように最適化されています。
ジャンバの優れたパフォーマンスと効率性
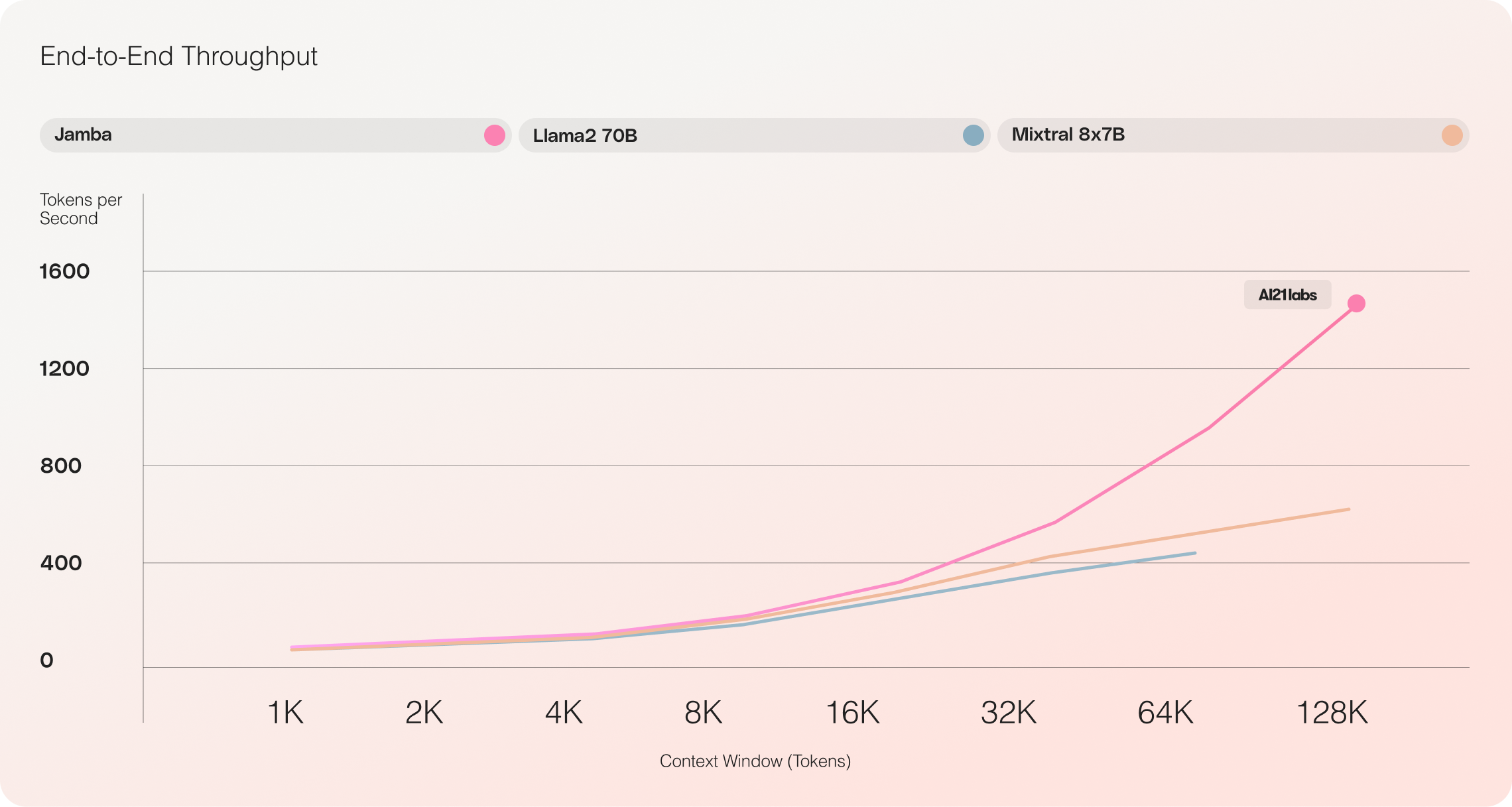
ジャンバ vs Llama 70B vs Mixtral 8x7B
ジャンバの初期評価では、スループットと効率性などの主要指標で優れた結果が得られています。このブレークスルー技術に関するコミュニティの継続的な実験と最適化により、これらのベンチマークはさらに改善されると期待されています。
- 効率性: ジャンバは...ここは日本語の翻訳です。コードの部分は翻訳していません。
elivers 3倍のスループットを持ち、Mixtral 8x7BのようなTransformer系モデルよりも効率的です。 2. コストパフォーマンス: 単一のGPUで14万文脈をフィットさせる能力により、Jambaは同サイズの他のオープンソースモデルと比べてより手頃な導入と実験の機会を提供します。
さらなる最適化、例えばMoEのパラレル化の強化や高速なMambaの実装などにより、これらの印象的な性能向上がさらに期待できます。
Jambaを始めよう
Jambaは現在Hugging Faceで利用可能で、Apache 2.0ライセンスの下でオープンな重みで公開されています。ベースモデルとして、Jambaはファインチューニング、トレーニング、カスタムソリューションの開発の基盤として機能することを意図しています。責任あり安全な使用のための適切な安全装置を追加することが不可欠です。
Jambaの命令バージョンは近日中にAI21プラットフォームのベータ版で利用可能になる予定です。プロジェクトを共有したり、フィードバックを提供したり、質問をするには、Discordでの議論に参加してください。
結論
Jambaの登場は、ハイブリッドSSM-Transformerアーキテクチャの膨大な可能性を示す重要な一歩です。Mambaとトランスフォーマーの長所を組み合わせ、効率性とパフォーマンスを最適化することで、JambaはそのサイズクラスのAIモデルの新しい基準を設定しました。
文脈処理能力、スループット、コストパフォーマンスの点で印象的なJambaは、研究者、開発者、企業がAIの可能性の限界を押し広げることを可能にするでしょう。コミュニティがJambaの革新を探求し、構築を続けるにつれ、人工知能の未来を形作る新しいAIアプリケーションの波が到来することが期待されます。