LLaVA-Med:バイオメディカルイメージングにおける次なる大飛躍

医療イメージングの世界はパラダイムシフトを目撃しています。かつて医療従事者は、目の鋭さや長年の経験にのみ頼って医療スキャンを解釈していましたが、それは過去のものとなりました。ここに、バイオメディカルセクター専用に設計された名高いLLaVAモデルの特殊なバリエーションであるLLaVA-Medが登場します。この強力なツールは単なるテクノロジーの一部ではありません。それは診断と治療計画の未来を代表するものです。X線、MRI、複雑な3Dスキャンに関わらず、LLaVA-Medは類まれな洞察を提供し、従来の方法と最先端のAI技術との間にあるギャップを埋め合わせます。
医療画像やテキストの詳細な分析を指先で提供できるアシスタントがあると想像してみてください。それがLLaVA-Medです。正確さと多重モーダルの機能を組み合わせた、世界の医療専門家にとって不可欠なパートナーになることでしょう。このツールがいかに特別かを発見する旅に出かけましょう。
最新のLLMニュースを知りたいですか?最新のLLMリーダーボードをチェックしてください!
LLaVA-Medとは?
LLaVA-Medは、バイオメディカルセクターに特化して構築されたLLaVAモデルの特別なバリエーションです。これは医療従事者にとって貴重なツールであり、医療画像やテキストの解釈と分析に特化しています。X線、MRI、複雑な3Dスキャンなどに目を通す場合、LLaVA-Medは診断と治療計画に役立つ詳細な洞察を提供します。
Microsoftはオープンソースの#LLaVAを微調整して、バイオメディカルイメージを解釈できるビジョン言語モデルであるLLaVA-Medを作成しました。このモデルを微調整して、あなたの機関の研究を読み、正確であなたの言語とトーンに合わせたテキストを生成すると想像してみてください。 pic.twitter.com/rnSOWITTLB
— Paulo Kuriki, MD (@kuriki) October 8, 2023
LLaVA-Medの特長
-
医療データに適応された微調整:汎用のLLaVAモデルとは異なり、LLaVA-Medは医学ジャーナル、臨床ノート、さまざまな医療画像から構成される専門データセットでトレーニングされています。
-
高い精度: LLaVA-Medは、医療画像の解釈において優れた精度を誇り、他の医療画像ソフトウェアを上回ることが多いです。
-
多重モーダルの機能:LLaVA-Medはテキストと画像の両方を分析することができるため、しばしば書かれたメモと医療画像の両方を含む患者記録の解釈に理想的です。
LLaVA-Medの評価:その実力はいかに?
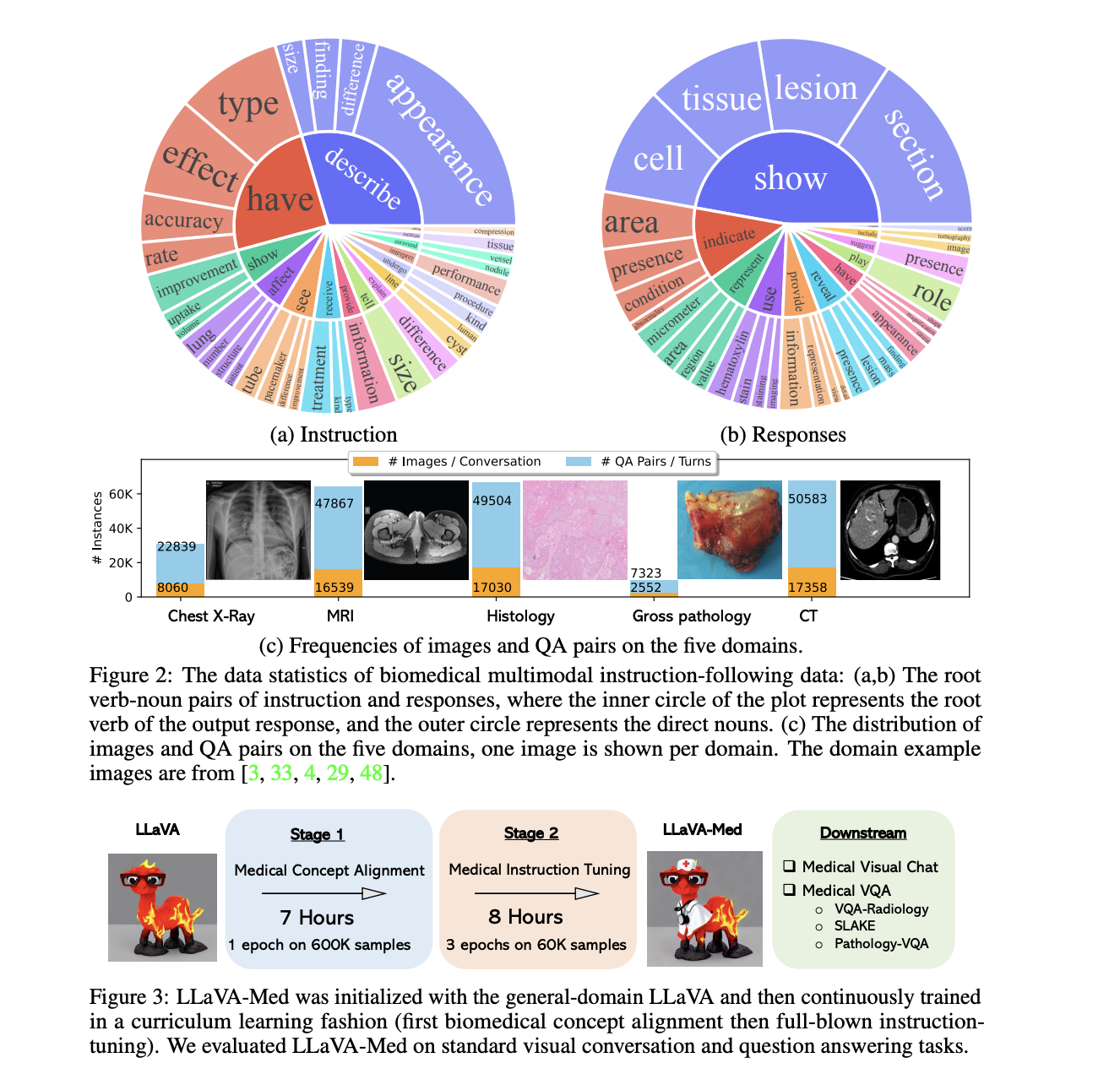
提供された表の情報をテキストに統合します。
1. LLaVA-Medのビジュアルバイオメディカル解釈の熟練度:
LLaVA-Medは、広範なLLaVAモデルを基盤とし、ビジュアルバイオメディカルデータの解釈能力を独自に持っています。
-
評価用ベンチマークデータセット:LLaVA-Medおよび他のモデルは、VQA-RAD、SLAKE、PathVQAなど、放射線学、病理学などのビジュアル質問応答能力をテストする特定のベンチマークデータセットで評価されています。
-
監督付き微調整の結果: 以下の表は、さまざまな手法での監督付き微調整実験の結果を示しています。
| 手法 | VQA-RAD(参照) | VQA-RAD(オープン) | VQA-RAD(クローズ) | SLAKE(参照) | SLAKE(オープン) | SLAKE(クローズ) | PathVQA(参照) | PathVQA(オープン) | PathVQA(クローズ) |
|---|---|---|---|---|---|---|---|---|---|
| LLaVA | 50.00 | 65.07 | 78.18 | 63.22 | 7.74 | 63.20 | |||
| LLaVA-Med(LLaVA) | 61.52 | 84.19 | 83.08 | 85.34 | 37.95 | 91.21 | |||
| LLaVA-Med(Vicuna) | 64.39 | 81.98 | 84.71 | 83.17 | 38.87 | 91.65 | |||
| LLaVA-Med(BioMed) | 64.75 | 83.09 | 87.11 | 86.78 | 39.60 | 91.09 |
メトリクスの説明:
-
手法: 評価されるモデルの特定のバージョンやアプローチを示します。LLaVAとLLaVA-Medのさまざまなイテレーションやソースが含まれます。
-
VQA-RAD(参照、オープン、クローズ): 放射線学におけるビジュアル質問応答のためのメトリクス。 '参照'は参照スコアを、'オープン'はオープンエンドの質問スコアを、'クローズ'はクローズエンドの質問スコアを指します。
-
SLAKE(参照、オープン、クローズ): SLAKEベンチマークのメトリクス。 '参照'は参照スコアを、'オープン'はオープンエンドの質問スコアを、'クローズ'はクローズエンドの質問スコアを意味します。
-
PathVQA(参照、オープン、クローズド):病理学的視覚問題への関連メトリクス。「参照」は参照スコアを示し、「オープン」はオープンエンドの質問スコアを示し、「クローズド」はクローズドエンドの質問スコアを示します。
参考文献:研究ソース (opens in a new tab)
LLaVA-Medの様々な方法による結果を並べることで、このモデルがビジュアルバイオメディカル解釈において優れた性能を発揮していることが明らかになります。特に、VQA-RADやSLAKEなどのベンチマークに対して評価された場合、その高い能力が医療専門家が視覚データに基づいてより情報豊かな意思決定を行う上での潜在能力を示しています。
2. LLaVA-Medの指示に従った能力:
LLaVAモデルを元にしたLLaVA-Medの専門知識は、バイオメディカルの微妙なニュアンスに特化しているため、はっきりとしています。
-
モデルの改良のためのデータセット:LLaVA-Medの改良には、バイオメディカルの多様な多言語指示に関するデータセットが使用されました。さまざまな現実世界のバイオメディカルの文脈を包含しているこのデータセットは、LLaVA-Medが医療の知識の表現と理解において優れた能力を持つことを保証しています。
-
二段階の適応に関する洞察:
- 第1フェーズ(バイオメディカル概念の統合):この基盤となるフェーズは重要でした。LLaVAの包括的な知識と異なるバイオメディカル概念を統合することを目指していました。このステップにより、次の改良が医療の複雑さに合わせて行われることが保証されました。
- 第2フェーズ(包括的な指示の調整):重要な瞬間であるこの段階では、モデルをバイオメディカルの指示について集中的にトレーニングし、医療の文脈を直感的に理解し、関与し、対応できるように強化しました。
LLaVAとLLaVA-Medの比較パフォーマンス:
| モデルのイテレーション | 会話(%) | 説明(%) | CXR(%) | MRI(%) | 組織学(%) | 大まかな構造(%) | CT(%) | 累積(%) |
|---|---|---|---|---|---|---|---|---|
| LLaVA | 39.4 | 26.2 | 41.6 | 33.4 | 38.4 | 32.9 | 33.4 | 36.1 |
| LLaVA-Med フェーズ 1 | 22.6 | 25.2 | 25.8 | 19.0 | 24.8 | 24.7 | 22.2 | 23.3 |
| LLaVA-Med フェーズ 2 | 52.4 | 49.1 | 58.0 | 50.8 | 53.3 | 51.7 | 52.2 | 53.8 |
メトリックの説明:
-
モデルのイテレーション:調査対象のモデルの特定のイテレーションまたはフェーズを示します。LLaVA、プライマリフェーズを経たLLaVA-Med、およびセカンダリフェーズを経たLLaVA-Medが含まれます。
-
会話(%):コンテキストに即した対話を維持し、関連する回答を提供するモデルの能力を示すメトリックです。
-
説明(%):医療視覚の徹底的な説明能力を示すマーカーで、伝えられた詳細が正確であることを保証します。
-
CXR(%):臨床診断において不可欠なツールである胸部X線の解釈におけるLLaVA-Medの正確さを評価するためのメトリックです。
-
MRI(%):磁気共鳴画像の結果を分析し、説明するモデルの能力を測定するメトリックです。MRIは詳細な洞察を持ち、医学診断および治療的な決定に重要です。
-
組織学(%):細胞の異常を特定するために重要な顕微組織学研究を細かく調べるモデルの効果を反映するメトリックです。
-
大まかな構造(%):顕微鏡的な支援なしで見える大まかな解剖構造を解説するLLaVA-Medの能力を測定する指標です。
-
CT(%):包括的な断面画像を持つコンピュータ断層撮影の解釈におけるモデルの精度を評価するメトリックです。
-
累積(%):異なるカテゴリ全体でのモデルのパフォーマンスをまとめた総合スコアです。
参考文献:研究ソース (opens in a new tab)
3. LLaVA-Medビジュアルチャットボット、簡単に説明すると:
LLaVA-Medは単なる言葉遣いだけでなく、画像の理解にも優れています。
-
さまざまなことに優れている:LLaVA-Medはさまざまな医療画像について多くの知識を持っています。X線からMRI、そして微小な組織画像まで、画像を見ることができます。
-
多くのデータ:それがなぜそんなに優れているのか?それは多くの画像とテキストを見て学んできたからです。したがって、X線や体のスキャンなどのことについてなどのことを知っています。
-
現実世界での利用:何百ものX線を見る医師を考えてみてください。LLaVA-Medはこれらの画像を素早くチェックし、問題を指摘し、医師の仕事を容易にすることができます。
-
GPT-4との比較:GPT-4は言葉遣いに長けています。しかし、医療画像の理解とその話になると、LLaVA-Medの方がより優れています。医療画像を見て詳細に話すことができます。
-
完璧ではない:すべてのものと同様に、LLaVA-Medにも限界があります。時には、知っているものとは異なる画像に混乱することもあります。しかし、より多くの画像を見ることで学び、より良くなることができます。
LLaVA-Medのインストール方法:ステップバイステップ
LLaVA-Medを立ち上げるには、汎用のLLaVAモデルとは異なる特殊な性格を持つため、いくつかのステップが必要です。以下に手順を示します:
ステップ1:LLaVA-Medリポジトリの初期化
クローニングが簡単:
まず、LLaVA-Medリポジトリをクローンすることから始めましょう。ターミナルを起動し、次のコマンドを入力します:
git clone https://github.com/microsoft/LLaVA-Med.gitこのコマンドは、必要なすべてのファイルをMicrosoftのリポジトリから直接マシンに取得します。
ステップ2:LLaVA-Medディレクトリにダイブ
ナビゲーションの基本事項:
リポジトリをクローンしたら、次に作業ディレクトリを切り替える必要があります。以下のように実行します:
cd LLaVA-Medこのコマンドを実行することで、LLaVA-Medのディレクトリの中心に位置し、次のフェーズに進む準備が整います。
ステップ3:基盤の準備 - パッケージのインストール
依存関係に基づく基盤:
細密なソフトウェアにはそれぞれの依存関係があります。LLaVA-Medも例外ではありません。次のコマンドを使用して、スムーズに動作するために必要なすべてのものをインストールします:
pip install -r requirements.txt覚えておいてください、これは単にパッケージのインストールについてだけではありません。LLaVA-Medがその機能を示すための好都合な環境を作り出すことに関わるのです。
ステップ4:LLaVA-Medとの関わり合い
魔法を目撃するためのサンプルプロンプトの実行:
行動の準備ができましたか?まず、LLaVA-MedモデルをPythonスクリプトに統合してみましょう:
from LLaVAMed import LLaVAMedモデルの実行:
model = LLaVAMed()サンプルの医療テキスト分析に潜り込みます:
text_output = model.analyze_medical_text("Describe the symptoms of pneumonia.")
print(text_output)そして、医療画像分析に興味がある方には:
image_output = model.analyze_medical_image("path/to/xray.jpg")
print(image_output)これらのコマンドを実行すると、LLaVA-Medの分析能力が明らかになります。例えば、医療テキスト分析では肺炎の症状、原因、潜在的な治療法が明らかになるかもしれません。一方、画像分析ではX線の不一致や異常を特定することができます。LLaVA-Med GitHubソースコード (opens in a new tab)をチェックしてみてください。
結論
医療画像のAIは、正確性と効率性の面で非常に有望ですが、まだ人間の医師を完全に代替できるほどの段階にはありません。この技術は、診断を支援するための強力なツールとして機能しますが、信頼性と包括的なケアを提供するためには医療専門家の監督と経験が必要です。したがって、重点はAIと人間の専門知識が共存し、最高品質の医療を提供するための協力的な環境を作ることにあるべきです。
最新のLLMニュースを知りたいですか?最新のLLMリーダーボードをチェックしてください!
