ミストラルモデルをローカルで実行する方法-完全ガイド

人工知能の急速な進化の中で、ミストラルAIは大規模言語モデル(LLM)の領域で新しい領域を切り拓いて革新の灯台となっています。画期的なモデルの導入により、ミストラルAIは機械学習のフロンティアを進めるだけでなく、先端技術へのアクセスを民主化しています。このガイドでは、ミストラルAIの提供する機能の複雑さを明らかにし、それらの機能をローカルで活用するための包括的なロードマップを提供することを目指しています。
これらのミストラルAIモデルとは何ですか?
ミストラルAIは、単なるイテレーションではなく、計算言語学の飛躍である一連の言語モデルを発表しました。このスイートの中心には、ミストラル7Bとミストラル8x7Bがあり、それぞれ異なるニーズと計算能力に対応しています。
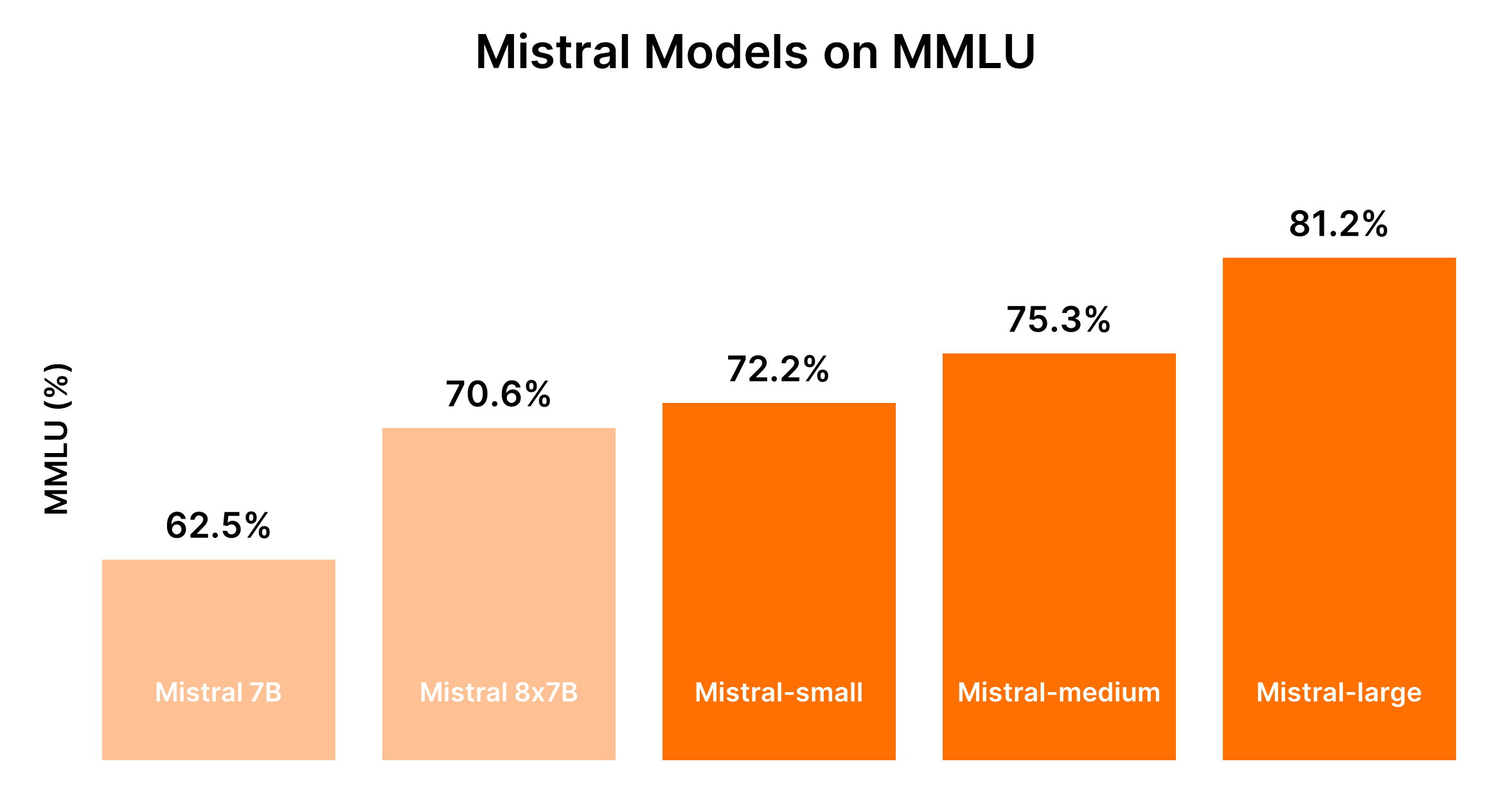
ミストラルAIモデルの比較(ミストラル7B vs ミストラル8x7B vs ミストラルスモール vs ミストラルミディアム vs ミストラルラージ)
了解しました。提供された入力に基づいて、マークダウン形式で直接比較するためのテーブルを作成することに重点を置いて、ミストラルAIモデルの比較分析を構造化します。
ミストラルAIモデルの比較分析
ミストラルAIは、シンプルな一括タスクから複雑な推論能力までを対象としたさまざまなモデルを提供しています。以下は、明確な理解を得るためのマークダウン形式での比較分析とパフォーマンスの出力です。
モデルの概要と使用例
| モデルID | 別名 | 使用例 |
|---|---|---|
| open-mistral-7b | mistral-tiny-2312 | 分類、顧客サポート、テキスト生成などのシンプルな一括タスク |
| open-mixtral-8x7b | mistral-small-2312 | open-mistral-7bと同様のシンプルな一括タスクに適しています |
| mistral-small-latest | mistral-small-2402 | 最小限の推論が必要なやや高度なタスク |
| mistral-medium-latest | mistral-medium-2312 | データの抽出、文書の要約、メールの作成などの中程度のタスク |
| mistral-large-latest | mistral-large-2402 | 合成テキスト生成、コード生成など、大規模な推論能力が必要な複雑なタスク |
パフォーマンスとコストのトレードオフ
ミストラルモデルのパフォーマンスは一般的にサイズに比例し、より大きなモデルほど高度な機能を提供しますが、コストも高くなります。以下の表は、MMLUベンチマークと一般的なコストの考慮に基づいたパフォーマンスのランキングをまとめたものです。
| モデル | パフォーマンスのランキング | コストの考慮 |
|---|---|---|
| ミストラル7B (tiny-2312) | 5位 | シンプルなタスクに最もコスト効果がある |
| ミストラル8x7B (small-2312) | 4位 | 一括のシンプルなタスクにコスト効果がある |
| ミストラルスモール (small-2402) | 3位 | 程度の推論が必要なタスクに中程度のコストが適しています |
| ミストラルミディアム (medium-2312) | 2位 | 中程度のコストでバランスの取れたパフォーマンスを提供する |
| ミストラルラージ (large-2402) | 1位 | 複雑なタスクに最も高コストで非凡なパフォーマンスを提供する |
LLMのパフォーマンスと関連するコストの動的な性質を考慮すると、最も正確な比較のために現在のベンチマークと価格情報を参照することをお勧めします。最新のベンチマークとパフォーマンスに関する情報については、Hugging FaceのChatbot Arena Leaderboard (opens in a new tab)とArtificial Analysis (opens in a new tab)などのプラットフォームが貴重な情報源となります。
決定支援:どのミストラルAIモデルを選ぶべきか?
適切なモデルを選択するには、パフォーマンスのニーズとコスト制約をバランスさせ、アプリケーションが処理するタスクの複雑さを考慮する必要があります。
- シンプルなタスクの場合: コスト効率のためにミストラルスモールまたはミストラル7Bから開始します。
- 中程度から複雑なタスクの場合: ミストラルミディアムまたはミストラルラージのパフォーマンスの向上が、特定のアプリケーションのニーズに応じて追加の費用を正当化するかどうかを評価します。
この構造化された比較分析により、ミストラルAIのモデル提供から適切なモデルを選択する際に、機能要件と予算制約の両方に合致するモデルが選ばれるよう支援します。

パート1. Ollamaを使ったローカルでのミストラル実行方法(簡単な方法)
Ollamaを使用してローカルでミストラルAIモデルを実行すると、クラウドサービスに頼らずに、高度なLLMのパワーを手元のマシンで利用できる簡単な方法が提供されます。これは、AIによるテキスト分析や生成などを実験したい開発者、研究者、愛好家にとって理想的なアプローチです。以下は、始めるための簡潔なガイドです:
ステップ1:Ollamaのダウンロード
- Ollamaのダウンロードページにアクセスし、オペレーティングシステムに適したバージョンを選択します。macOSユーザーの場合、
.dmgファイルをダウンロードします。 - ダウンロードしたファイルを
/ApplicationsディレクトリにドラッグしてOllamaをインストールします。
ステップ2:Ollamaコマンドの探索
オープンなターミナルを開いて、利用可能なコマンドのリストを表示するためにollamaを入力します。serve、create、show、run、pullなどのオプションが表示されます。
ステップ3:Mistral AIのインストール
Mistral AIモデルをインストールするには、まず、インストールしたいモデルを見つける必要があります。Mistral:instructバージョンに興味がある場合、既にマシンにインストールされていない場合は、直接インストールするか、Pullすることができます。
- 直接実行して(必要ならダウンロード):
ollama run mistral:instruct - モデルの事前ダウンロード:
ollama pull mistral:instruct
ステップ4:Mistral AIとの対話
モデルがインストールされたら、インタラクティブモードまたは直接入力することでそれと対話することができます。
-
インタラクティブモードの場合:
ollama run mistral --verboseその後、プロンプトに従ってクエリを入力してください。
-
非インタラクティブモード(直接入力)の場合:
bbc.txtに要約したい記事が保存されているとします。記事の内容を直接Mistralに渡して要約することができます:ollama run mistral --verbose "Please can you summarise this article: $(cat bbc.txt)""Please can you summarise this article: $(cat bbc.txt)"をタスクに関連するプロンプトに置き換えてください。
サンプルの出力の解析
ターミナルには、モデルの出力が表示されます。要約やプロンプトへの応答などが含まれています。Mistralが複雑なクエリをどのように処理し、不正確な箇所について質問された場合に修正案を提供するかを見るのは興味深いです。
HTTP APIを使用してMistral AIを実行する
Ollamaは、HTTP APIもサポートしており、モデルとプログラムの対話を可能にします。
curlリクエストのサンプル:curl -X POST http://localhost:11434/api/generate -d '{ "model": "mistral", "prompt": "What is the sentiment of this sentence: The situation surrounding the video assistant referee is at crisis point." }'
この方法ではJSONレスポンスが出力され、Mistral AIの機能をアプリケーションに柔軟に組み込むことができます。
ローカルマシンでOllamaを使用してMistral AIを実行することで、AIを個人のプロジェクト、開発、研究に活用する広範な可能性が広がります。簡単なインストールと使用の容易さに加えて、MistralのLLMの強力さが組み合わさっているため、AI技術のフロンティアを探索に興味のあるすべての人にとって魅力的なオプションです。
パート2. WindowsでMistral 7Bをローカルで実行する方法
Mistral 7Bは、HuggingFace、Vertex AI、Replicate、Sagemaker Jumpstart、Basetenなど、複数のプラットフォームからアクセスすることができます。Kaggleの「Models」機能も、モデルやデータセットのダウンロードを必要とせずに、推論やファインチューニングを数分で開始できるようにするシンプルなアプローチを提供しています。
Mistral 7Bにアクセスするための準備
始める前に、環境が最新であることを確認して、KeyError: 'mistral'などの一般的なエラーを回避してください:
!pip install -q -U transformers
!pip install -q -U accelerate
!pip install -q -U bitsandbytes4ビット量子化の実装
モデルの読み込みを高速化し、メモリ使用量を減らすために、4ビット量子化が使用されています:
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig, pipeline
import torch
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
)KaggleノートブックでMistral 7Bを読み込む
Kaggleノートブックでは、シンプルなUIインタラクションを通じてMistral 7Bを追加することができます。適切なモデルバリエーションとバージョンを選択した後、モデルとトークナイザを簡単に読み込んで使用することができます:
model_name = "/kaggle/input/mistral/pytorch/7b-v0.1-hf/1"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
load_in_4bit=True,
quantization_config=bnb_config,
torch_dtype=torch.bfloat16,
device_map="auto",
trust_remote_code=True,
)pipeline関数を利用することで、与えられたプロンプトに基づいて応答を簡単に生成することができます。
サンプルの推論
プロンプトを設定し、パイプラインを呼び出すことで、Mistral 7Bは一貫して意味のあるコンテキストに即した応答を生成し、機械学習の正則化などの複雑な概念の理解を示します:
prompt = "As a data scientist, can you explain the concept of regularization in machine learning?"
sequences = pipe(
prompt,
do_sample=True,
max_new_tokens=100,
temperature=0.7,
top_k=50,
top_p=0.95,
num_return_sequences=1,
)
print(sequences[0]['generated_text'])Mistral 7Bのファインチューニング
ファインチューニングのプロセスには、ライブラリの更新、モジュールの設定、およびモデルのデータセットに合わせた調整が含まれます。Kaggleノートブックでは、Hugging FaceやWeights & BiasesなどのAPIキーを安全に保存してアクセスすることができます。このセクションでは、特定のデータセットでモデルの潜在能力を最大限に引き出すための、効果的なファインチューニングのための重要なステップと設定について詳しく説明しています。
- 必要なライブラリの更新とインストール:ファインチューニングのための互換性と最新の機能へのアクセスを確保します。
- モジュールの読み込みとAPIアクセスの設定:外部サービスやモデルリポジトリとの対話を容易にします。
- モデルの構成とトレーニング:PEFT(パラメータ効率化ファインチューニング)のパワーを活用して、モデルをデータセットのニュアンスに適応させます。
- モデルの評価と保存:モデルのパフォーマンスを評価し、ファインチューニングしたモデルを保存します。
詳細な手順により、Mistral 7Bモデルの能力を有効に活用できるツールと知識を提供することを目指しています。モデルへのアクセスから特定のデータセットでのファインチューニングまで、各ステップはプロジェクトの自然言語処理能力を向上させるために設計されています。
パート3. LlamaIndexとOllamaを使用してMixtral 8x7bをローカルで実行する方法

ヨーロッパのAIパワーハウスであるMistral AIは、最新の「エキスパートのミクスト」モデルであるMixtral 8x7bを発表しました。このモデルは、それぞれ7,000,000,000のパラメータで訓練された8つのエキスパートを特徴としており、GPT-3.5やLlama2 70bの性能を上回るか、あるいはそれに匹敵する性能をさまざまなベンチマークで発揮しています。
ステップ1:Ollamaのインストール
Ollamaは、MacOS、Linux、Windows(Windows Subsystem For Linux経由)で利用できるオープンソースのツールで、ローカルモデルの実行プロセスを簡略化します。Ollamaを使用すると、次のコマンドを実行するだけでMixtralを開始できます。
ollama run mixtralこのコマンドはモデルをダウンロードします(これにはしばらく時間がかかる場合があります)。「スムーズに実行するには48GBのRAMが必要です。スペックの低いシステムでは、Mistral 7bが代替手段となります。
ステップ2:依存関係のインストール
LlamaIndexとMixtralを統合するには、いくつかの依存関係が必要です。pipを使用してそれらをインストールします。
pip install llama-index qdrant_client torch transformersステップ3:スモークテスト
OllamaとLlamaIndexを使用して「スモークテスト」でセットアップを検証します。
from llama_index.llms import Ollama
llm = Ollama(model="mixtral")
response = llm.complete("Who is Laurie Voss?")
print(response)ステップ4:データの読み込みとインデックス化
データの準備:
この例では任意のデータセットを使用します。ここでは、ツイートのコレクションを使用します。データはオープンソースのベクトルデータベースであるQdrantに格納されます。以下のコードスニペットは、QdrantとLlamaIndexを使用してデータの読み込みとインデックス化のプロセスを示しています。
from pathlib import Path
import qdrant_client
from llama_index import VectorStoreIndex, ServiceContext, download_loader
from llama_index.llms import Ollama
from llama_index.storage.storage_context import StorageContext
from llama_index.vector_stores.qdrant import QdrantVectorStore
## Qdrantの初期化とツイートの読み込み
client = qdrant_client.QdrantClient(path="./qdrant_data")
vector_store = QdrantVectorStore(client=client, collection_name="tweets")
storage_context = StorageContext.from_defaults(vector_store=vector_store)
## Mixtralとローカル埋め込みを使用するService Contextの設定
llm = Ollama(model="mixtral")
service_context = ServiceContext.from_defaults(llm=llm, embed_model="local")
## データのインデックス化とクエリ
index = VectorStoreIndex.from_documents(documents, service_context=service_context, storage_context=storage_context)
query_engine = index.as_query_engine()
response = query_engine.query("What does the author think about Star Trek? Give details.")
print(response)インデックスの検証:
最後のステップでは、事前に構築されたインデックスを使用してクエリに回答します。このプロセスでは、データを再読み込みする必要はありません。すでにQdrantにインデックスが作成されています。
import qdrant_client
from llama_index import VectorStoreIndex, ServiceContext
from llama_index.llms import Ollama
from llama_index.vector_stores.qdrant import QdrantVectorStore
## ベクトルストアとMixtralの読み込み
client = qdrant_client.QdrantClient(path="./qdrant_data")
vector_store = QdrantVectorStore(client=client, collection_name="tweets")
llm = Ollama(model="mixtral")
service_context = ServiceContext.from_defaults(llm=llm, embed_model="local")
## インデックスの読み込みとクエリ
index = VectorStoreIndex.from_vector_store(vector_store=vector_store, service_context=service_context)
query_engine = index.as_query_engine(similarity_top_k=20)
response = query_engine.query("Does the author like SQL? Give details.")
print(response)Part 4. How to Run Mistral 8x7B Locally with llama.cpp
Mistral AIモデルをローカルで実行することは、llama.cppやllm-llama-cppプラグインなどのツールのおかげでより簡単になっています。高品質の疎なエキスパートのミクスト(SMoE)モデルであるMixtral 8x7Bモデルのリリースは、オープンライセンスのAIの世界における重要な進歩となりました。以下では、llama.cppや関連するツールを使用して、Mixtral 8x7Bをローカルで実行する方法を簡単に紹介します。
Mixtral 8x7Bのローカルインストールと実行
-
LLMツールのインストール:まず、マシンにLLMがインストールされていることを確認してください。LLMは、さまざまなAIモデルをローカルで実行するためのブリッジとなります。
pipx install llm -
llm-llama-cppプラグインのインストール:このプラグインは、llama.cppで実行されるMixtralやその他のモデルを実行するために必要です。llm install llm-llama-cpp -
llama-cpp-pythonのセットアップ:Apple Silicon Macの場合、Metalのサポートを有効にする必要がある場合があります。CMAKE_ARGS="-DLLAMA_METAL=on" FORCE_CMAKE=1 llm install llama-cpp-python詳細な手順はプラットフォームによって異なる場合があるため、ガイダンスについては
llm-llama-cppのREADMEを参照してください。 -
Mixtralモデルのダウンロード:Mixtral 8x7BのためにGGUFファイルが必要です。必要なファイルサイズを選択してください。例えば、モデルのInstructバージョンに適した36GBのバリアントを選択します。
curl -LO 'https://huggingface.co/TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF/resolve/main/mixtral-8x7b-instruct-v0.1.Q6_K.gguf?download=true' -
モデルの実行:モデルをダウンロードした後、
llmツールを使用してMixtral 8x7Bを実行できます。llm -m gguf -o path mixtral-8x7b-instruct-v0.1.Q6_K.gguf '[INST] Write a Python function that downloads a file from a URL[/INST]'このコマンドでは、GGUFモデルを
-m ggufオプションで使用し、ダウンロードしたGGUFファイルのパスを-o pathで指定しています。
追加の考慮事項
-
インタラクティブモード:より対話的な方法でモデルと対話する場合は、
llmをインタラクティブモードで実行することを検討してください。このモードでは、AIモデルとの応答形式の対話が可能です。 -
プロンプトの構築:上記のコマンド例の中の
[INST]の接頭辞は、インストラクトバージョンのモデルに適した命令ベースのプロンプトを示しています。最適な結果を得るために、モデルの期待される入力形式に合わせてプロンプトを調整してください。
パート5. iPhoneでMistral 7Bをローカルで実行する

iPhoneでMistral 7Bモデルを実行するには、通常、デスクトップ環境よりも制約が多いため、いくつかの技術的な手順が必要です。以下は、簡略化されたステップバイステップガイドです。
-
前提条件:
- 互換性の問題を回避するために、iPhoneが最新のiOSバージョンで実行されていることを確認してください。
- Mistral 7Bを使用するカスタムアプリをコンパイルして実行するために、XcodeなどのMac上のiOSアプリ開発環境をインストールしてください。
-
実行オプションの選択:iPhoneへの展開には、通常C++環境との互換性があるため、「llm-llama-cpp」が最適です。これはiOSプロジェクトに統合することができます。
-
開発環境のセットアップ:
- 公式リポジトリから「llm-llama-cpp」のGGUFファイルをダウンロードしてください。
- Xcodeを開き、新しいiOSプロジェクトを作成してください。
- 「llm-llama-cpp」ライブラリをプロジェクトに統合してください。これには追加の依存関係が必要な場合がありますので、ドキュメントを参照してください。
-
コーディング:
- SwiftまたはObjective-Cのコードを記述して、C++ライブラリとのインターフェースを作成してください。これには、C++コードをSwiftプロジェクトで使用するためにブリッジングヘッダーを作成する場合があります。
- アプリ内でモデルを初期化し、モデルのパスやパラメータなど、必要な構成を処理してください。
-
テストと展開:
- iPhoneでアプリをテストし、モデルが正常に実行され、期待どおりのパフォーマンスを発揮することを確認してください。
- アプリをXcodeを介して個人的な使用のために展開するか、Appleのガイドラインに準拠している場合はApp Storeに提出してください。
パート6. APIを使用してMistral AIをローカルで実行する

Mistral AIをAPIを使用してローカルで実行するには、以下の手順に従ってください。テストやHTTPリクエストの機能を持つプログラミング言語(例:Pythonのrequestsライブラリ)やPostmanなどのHTTPリクエストに対応した環境が必要です。
前提条件:
- APIキーを取得 (opens in a new tab)し、Mistral APIへのアクセスをサインアップしてください。
- ローカル環境がMistral APIサーバーと通信できるように、インターネットに接続されていることを確認してください。
- ローカル環境に
llm-mistralプラグインをインストールしてください。プログラミングプロジェクトの場合は、プロジェクトの依存関係に追加する必要がある場合があります。 - プロジェクトやツールのMistral APIキーを使用するように設定してください。通常、これは設定ファイルまたは環境変数にキーを設定することで行われます。
チャットの補完を作成する
このAPIエンドポイントでは、プロンプトに基づいてテキストの補完を生成することができます。リクエストでは、モデル、メッセージ(プロンプト)、およびテンパレチャ、top_p、max_tokensなど、生成プロセスを制御するためのさまざまなパラメータを指定する必要があります。
チャット補完のサンプルPythonコード:
import requests
url = "https://api.mistral.ai/chat/completions"
payload = {
"model": "mistral-small-latest",
"messages": [{"role": "user", "content": "Mistral AIを使用し始めるにはどうすればよいですか?"}],
"temperature": 0.7,
"top_p": 1,
"max_tokens": 512,
"stream": False,
"safe_prompt": False,
"random_seed": 1337
}
headers = {
"Authorization": "Bearer YOUR_API_KEY",
"Content-Type": "application/json"
}
response = requests.post(url, json=payload, headers=headers)
if response.status_code == 200:
print(response.json())
else:
print("エラー:", response.text)埋め込みを作成する
埋め込みのAPIエンドポイントは、テキストを高次元ベクトルに変換するために使用されます。これは、意味検索、クラスタリング、または類似したテキストの検索などのタスクに役立ちます。
埋め込み作成のサンプルPythonコード:
import requests
url = "https://api.mistral.ai/embeddings"
payload = {
"model": "mistral-embed",
"input": ["こんにちは", "世界"],
"encoding_format": "float"
}
headers = {
"Authorization": "Bearer YOUR_API_KEY",
"Content-Type": "application/json"
}
response = requests.post(url, json=payload, headers=headers)
if response.status_code == 200:
print(response.json())
else:
print("エラー:", response.text)利用可能なモデルの一覧
このAPI呼び出しは簡単で、使用可能なすべてのモデルのリストを取得することができます。これにより、機能や要件に基づいてさまざまなタスクのためにモデルを動的に選択するのに役立ちます。
利用可能なモデルの一覧のサンプルPythonコード:
import requests
url = "https://api.mistral.ai/models"
headers = {
"Authorization": "Bearer YOUR_API_KEY"
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
print(response.json())
else:
print("エラー:", response.text)これらのサンプルは、Mistral AIのAPIと対話するための基盤を提供し、洗練されたAIアプリケーションの作成が可能になります。実際のAPIキーで"YOUR_API_KEY"を置き換えることを忘れないでください。
これらの手順は、Mistral 7B AIモデルをiPhone上およびAPIを介してローカルで利用するための基本的な概要を提供しています。具体的なプロジェクト要件やプラットフォームの更新に基づいて、適応が必要な場合があります。