1ビットLarge Language Models時代:マイクロソフトがBitNet b1.58を紹介
- Name
- Lynn Mikami
Published on
はじめに
マイクロソフトの研究者たちは、BitNet b1.58という画期的な1ビットLarge Language Model(LLM)のバリアントを紹介しました。このモデルでは、モデルのすべてのパラメータが三値(1)の三進数となっています。この1.58ビットのLLMは、フルプレシジョン(FP16またはBF16)のTransforme LLMと同じモデルサイズとトレーニングトークンを持ちながら、遅延、メモリ使用量、スループット、エネルギー消費においてはるかに費用対効果に優れています。BitNet b1.58は、LLMを高性能で高効率にするための大きな前進です。

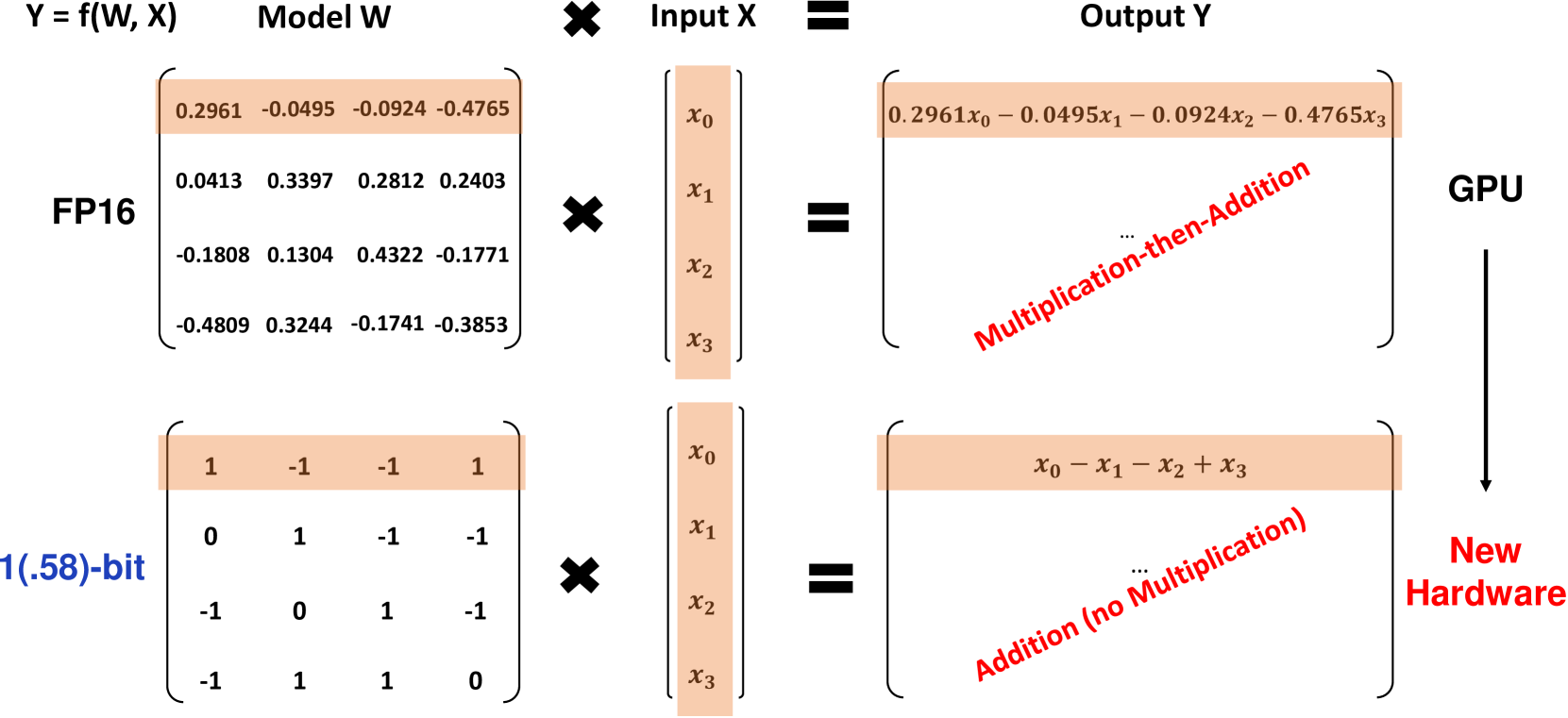
BitNet b1.58とは?
BitNet b1.58は、元々のBitNetアーキテクチャに基づいています。このアーキテクチャは、標準のnn.LinearレイヤーをBitLinearレイヤーで置き換えたTransformerモデルです。1.58ビットの重みと8ビットの活性化関数でトレーニングされています。オリジナルの1ビットのBitNetと比較して、b1.58では次のいくつかの主な変更が行われています。
-
重みにはabsmean量子化関数を使用し、重みを1に制約します。これにより、平均絶対値でスケーリングした後に、最も近い整数の値に丸められます。
-
活性化関数では、トークンごとに範囲[-sa、sa]にスケーリングされるため、オリジナルのBitNetと比較して実装が簡略化されます。
-
人気のあるオープンソースのLLaMAアーキテクチャから、RMSNorm、SwiGLUアクティベーション、回転埋め込み、およびバイアスの削除などのコンポーネントを採用しています。これにより、既存のLLMソフトウェアとの簡単な統合が可能となります。
重みに0の値を追加することで、1ビットのモデルと比較してモデリング能力が向上し、特徴フィルタリングが可能になります。実験結果では、3Bパラメータサイズから始めると、BitNet b1.58はFP16のベースラインとのパープレキシティとエンドタスクのパフォーマンスで一致することが示されています。
パフォーマンス結果
研究者たちは、BitNet b1.58を再現したFP16のLLaMA LLMベースラインと、700Mから70Bパラメータのさまざまなモデルサイズで比較しました。両者は、同じRedPajamaデータセットを使用して100Bトークンで事前トレーニングを行い、パープレキシティとさまざまなゼロショット言語タスクで評価されました。
主な結果は次のとおりです。
-
3BサイズのBitNet b1.58は、FP16のLLaMAベースラインとともにパープレキシティを一致させ、2.71倍の速度向上と3.55倍のGPUメモリ削減を実現しています。
-
3.9BのBitNet b1.58は、パープレキシティとエンドタスクの点で3BのLLaMAを上回り、遅延とメモリのコストを低減しています。
-
ゼロショット言語タスクでは、BitNet b1.58とLLaMAのパフォーマンスの差は、モデルサイズが大きくなるにつれて狭まり、3BサイズでBitNetがLLaMAと一致します。
-
70Bまでスケールアップすると、BitNet b1.58はFP16ベースラインと比較して4.1倍のスピードアップを実現します。メモリの節約効果もスケールに比例して増加します。
-
BitNet b1.58は、行列の乗算に対して71.4倍のエネルギー消費を削減します。エンドツーエンドのエネルギー効率はモデルサイズとともに向上します。
-
2つの80GB A100 GPU上で、70BのBitNet b1.58はLLaMAよりも大きなバッチサイズをサポートし、スループットを8.9倍向上させます。
これらの結果から、BitNet b1.58は、最先端のFP16 LLMに比べてパレート改善を提供し、十分なスケールでのパープレキシティとエンドタスクのパフォーマンスに匹敵する効率を備えていることが示されています。例えば、13BのBitNet b1.58は3BのFP16 LLMよりも効率的であり、30BのBitNetは7BのFP16よりも効率的ですし、70BのBitNetは13BのFP16モデルよりも効率的です。
StableLM-3Bレシピに従って2Tトークンでトレーニングした場合、BitNet b1.58は評価されたすべてのタスクで、StableLM-3Bのゼロショットを上回る性能を発揮し、強力な汎化性能を示しました。
以下の表は、BitNet b1.58とFP16のLLaMAベースラインのパフォーマンス比較の詳細なデータを提供しています。
| モデル | サイズ | メモリ (GB) | 遅延 (ms) | PPL |
|---|---|---|---|---|
| LLaMA LLM | 700M | 2.08 (1.00x) | 1.18 (1.00x) | 12.33 |
| BitNet b1.58 | 700M | 0.80 (2.60x) | 0.96 (1.23x) | 12.87 |
| LLaMA LLM | 1.3B | 3.34 (1.00x) | 1.62 (1.00x) | 11.25 |
| BitNet b1.58 | 1.3B | 1.14 (2.93x) | 0.97 (1.67x) | 11.29 |
| LLaMA LLM | 3B | 7.89 (1.00x) | 5.07 (1.00x) | 10.04 |
| BitNet b1.58 | 3B | 2.22 (3.55x) | 1.87 (2.71x) | 9.91 |
| BitNet b1.58 | 3.9B | 2.38 (3.32x) | 2.11 (2.40x) | 9.62 |
Table 1: BitNet b1.58とLLaMA LLMのパープレキシティとコストの比較。
| モデル | サイズ | ARCe | ARCc | HS | BQ | OQ | PQ | WGe | Avg. |
|---|---|---|---|---|---|---|---|---|---|
| LLaMA LLM | 700M | 54.7 | 23.0 | 37.0 | 60.0 | 20.2 | 68.9 | 54.8 | 45.5 |
| BitNet b1.58 | 700M | 51.8 | 21.4 | 35.1 | 58.2 | 20.0 | 68.1 | 55.2 | 44.3 |
| LLaMA LLM | 1.3B | 56.9 | 23.5 | 38.5 | 59.1 | 21.6 | 70.0 | 53.9 | 46.2 |
| BitNet b1.58 | 1.3B | 54.9 | 24.2 | 37.7 | 56.7 | 19.6 | 68.8 | 55.8 | 45.4 |
| LLaMA LLM | 3B | 62.1 | 25.6 | 43.3 | 61.8 | 24.6 | 72.1 | 58.2 | 49.7 |
| BitNet b1.58 | 3B | 61.4 | 28.3 | 42.9 | 61.5 | 26.6 | 71.5 | 59.3 | 50.2 |
| BitNet b1.58 | 3.9B | 64.2 | 28.7 | 44.2 | 63.5 | 24.2 | 73.2 | 60.5 | 51.2 |
Table 2: BitNet b1.58とLLaMA LLMのエンドタスクにおけるゼロショットの精度。
図1は、異なるモデルサイズでのBitNet b1.58のデコーディングの遅延時間とメモリ使用量を示しています。モデルサイズの拡大に伴い、スピードアップは大きくなり、70BパラメータでFP16ベースラインと比較して4.1倍に達します。メモリの節約効果も拡大します。
キャプションを参照 キャプションを参照 Figure 1: 異なるモデルサイズでのBitNet b1.58のデコーディングの遅延時間(左)とメモリ使用量(右)。 BitNet b1.58は、エネルギー効率の観点から、FP16 LLMに比べて行列の乗算において71.4倍のエネルギーを使用しません。図2に示すモデルサイズ全体にわたるエネルギーコストにおいて、BitNet b1.58はより大規模なスケールでますます効率的になっています。
キャプションを参照してください キャプションを参照してください 図2:BitNet b1.58とLLaMA LLMのエネルギー消費の比較。左:算術演算のエネルギーの構成。右:モデルサイズ全体のエネルギーコスト。
スループットは、BitNet b1.58のもう一つの主な利点です。80GBのA100 GPU 2台で、70BのBitNet b1.58は70BのLLaMA LLMよりも11倍大きなバッチサイズをサポートし、スループットが8.9倍高くなります(表3参照)。
| モデル | サイズ | 最大バッチサイズ | スループット(トークン/秒) |
|---|---|---|---|
| LLaMA LLM | 70B | 16 (1.0x) | 333 (1.0x) |
| BitNet b1.58 | 70B | 176 (11.0x) | 2977 (8.9x) |
表3:70B BitNet b1.58とLLaMA LLMのスループット比較
意義と将来の展望
BitNet b1.58のアーキテクチャと結果は、LLMの将来において重要な意義を持ちます。
-
高性能で高効率なLLMのための新しいパレートフロンティアとスケーリング法を確立します。1.58ビットのLLMは、ダイナミックな低コストの推論コストでFP16の基準に対抗することができます。
-
急激なメモリの削減により、与えられたハードウェア上でより大規模なLLMを実行することが可能になります。特にエキスパートの混合などのメモリ集約型のアーキテクチャには大きな影響があります。
-
8ビットの活性化により、16ビットと比較して与えられたメモリ予算で可能なコンテキストの長さが2倍になります。将来的には4ビットやそれ以下に圧縮することも可能です。
-
1.58ビットのLLMの卓越した効率は、CPUデバイス上での強力なLLMの展開を可能にし、エッジ/モバイルでの展開に適したものとなります。
-
BitNet b1.58の新しい低ビット演算パラダイムは、1ビットのLLMのポテンシャルを最大限に生かすために、カスタムのAIアクセラレータとシステムの設計を促進します。
Microsoftは、1ビットのLLMを非常に有望な進化の方向と考えています。これにより、LLMがデータセンターからエッジまでのアプリケーションを強力にサポートする時代が訪れると予想しています。ただし、この未来を実現するには、これらのモデルのユニークな特性を十分に活用するために、モデルアーキテクチャ、ハードウェア、ソフトウェアシステムを共同設計する必要があります。BitNet b1.58は、この新しいLLM時代の興奮を引き起こす起点となります。
結論
BitNet b1.58は、大規模な言語モデルを量子化の限界まで推進するための大きなブレイクスルーです。3値1の重みと8ビットの活性化を活用することで、メモリ使用量、レイテンシ、エネルギー消費を劇的に削減しながら、FP16のLLMと等しい困惑度とエンドタスクのパフォーマンスを実現しています。
1.58ビットのアーキテクチャは、より大きなモデルをさらに低コストで実行する新しいパレートフロンティアを確立しています。これにより、より長いコンテキストのサポート、エッジデバイスへの強力なLLMの展開など、新たな可能性が開かれます。さらに、低ビットのAIのためにカスタムのハードウェアの設計を推進する動機付けを提供しています。
Microsoftの研究は、積極的に量子化されたLLMが単に可能であるだけでなく、実際にはFP16モデルと比較して優れたスケーリング法を確立していることを示しています。アーキテクチャ、ハードウェア、ソフトウェアのさらなる共同設計により、1ビットのLLMはクラウドからエッジまでのコスト効果の高いAI能力の次の大きな飛躍の可能性を秘めています。BitNet b1.58は、この非常に効率的な大規模言語モデルのエキサイティングな新時代の出発点となります。