LlamaIndex:大規模言語モデルを拡張するLangChainの代替

導入:LlamaIndexとは?
LlamaIndexは、Large Language Models(LLMs)の機能を拡張するために特別に設計された高性能インデックス作成ツールです。単なるクエリ最適化ツールではなく、応答合成、組み合わせ性、効率的なデータ保存など、高度な機能を提供する包括的なフレームワークです。複雑なクエリに対応し、文脈に合った高品質の応答を必要とする場合、LlamaIndexが最適なソリューションです。
本記事では、LlamaIndexのコアコンポーネント、高度な機能、プロジェクトへの効果的な実装方法について、テクニカルな詳細を解説します。また、LangChainなどの類似ツールと比較して、LlamaIndexの機能を完全に理解していただけるようにします。
最新のLLMニュースを知りたいですか?最新のLLMリーダーボードをチェックしてください!
LlamaIndexとは何ですか?
LlamaIndexは、Large Language Models(LLMs)の機能を拡張するために特別に設計された専門ツールです。特定のLLMのインタラクションにおける包括的なソリューションとして機能し、特に正確なクエリと高品質の応答が求められるシナリオで優れた性能を発揮します。
クエリ:データの迅速な取得に最適化されており、速度が重要なアプリケーションに適しています。 応答合成:簡潔で文脈に合った応答を生成するために最適化されています。 組み合わせ性:モジュラーで再利用可能なコンポーネントを使用して、複雑なクエリやワークフローを構築できます。
それでは、LlamaIndexの詳細について見ていきましょう。
LlamaIndexにおけるインデックスとは何ですか?
インデックスはLlamaIndexのコアであり、クエリ対象の情報を保持するデータ構造として機能します。LlamaIndexでは、特定のタスクに最適化された複数の種類のインデックスが提供されています。

LlamaIndexにおけるインデックスの種類
- Vector Store Index: 高次元データに最適化されたk-NNアルゴリズムを使用します。
- Keyword-based Index: テキストベースのクエリにTF-IDFを使用します。
- Hybrid Index: VectorとKeyword-basedインデックスの組み合わせで、バランスの取れたアプローチを提供します。
LlamaIndexにおけるVector Store Index
Vector Store Indexは、高次元データに関連するすべての操作に最適なツールです。特に複雑なデータポイントを扱う機械学習アプリケーションに非常に役立ちます。
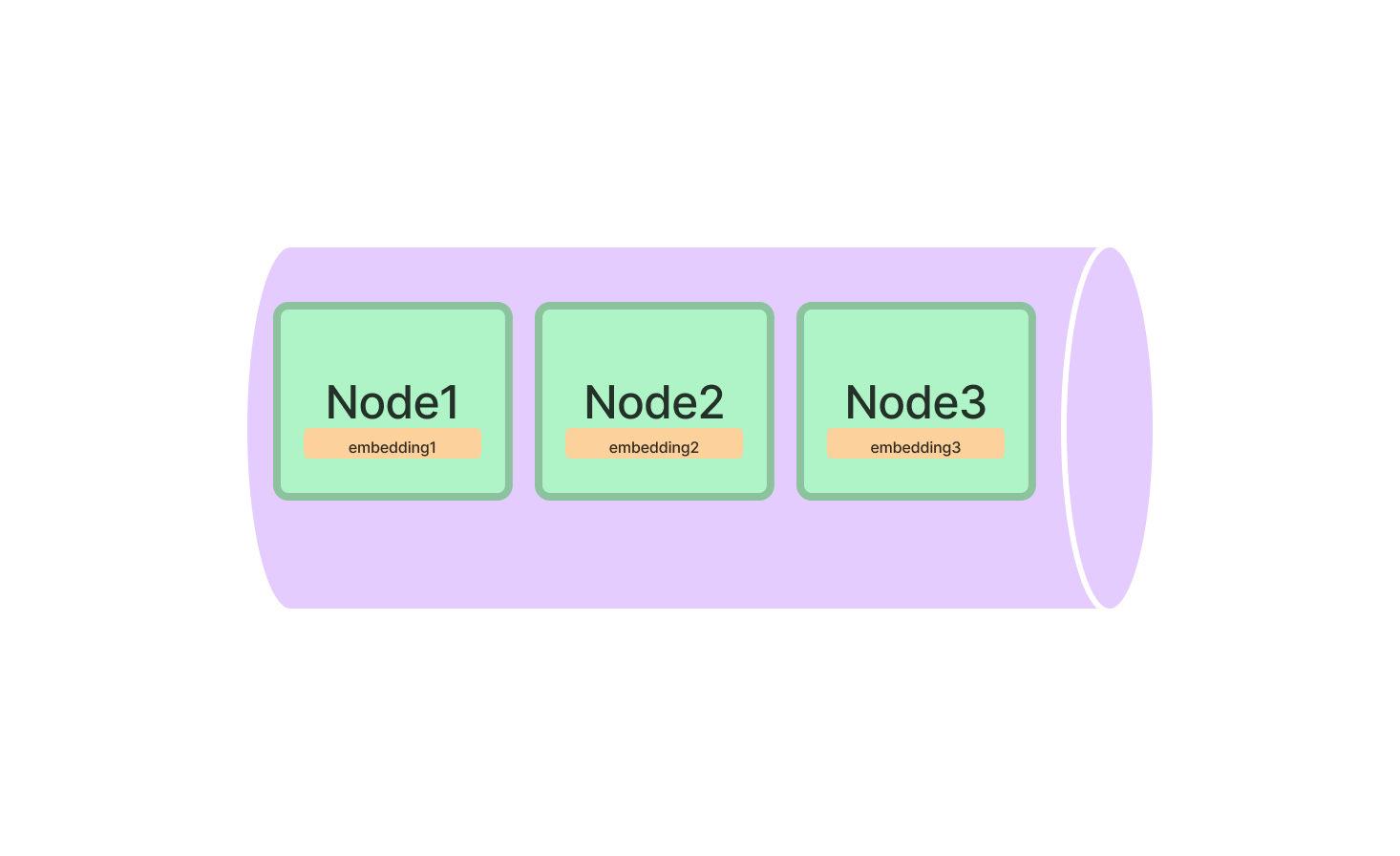
はじめに、LlamaIndexパッケージからVectorStoreIndexクラスをインポートする必要があります。インポートが完了したら、ベクトルの次元を指定して初期化します。
from llamaindex import VectorStoreIndex
vector_index = VectorStoreIndex(dimensions=300)これにより、300次元のVector Store Indexがセットアップされ、高次元データを処理できる状態になります。ここで、インデックスにベクトルを追加し、最も類似したベクトルを検索するクエリを実行できます。
# ベクトルの追加
vector_index.add_vector(vector_id="vector_1", vector_data=[0.1, 0.2, 0.3, ...])
# クエリの実行
query_result = vector_index.query(vector=[0.1, 0.2, 0.3, ...], top_k=5)LlamaIndexにおけるKeyword-based Index
テキストベースのクエリに興味がある場合は、Keyword-based Indexが頼りになるでしょう。TF-IDFアルゴリズムを使用してテキストデータを検索し、自然言語クエリに最適です。
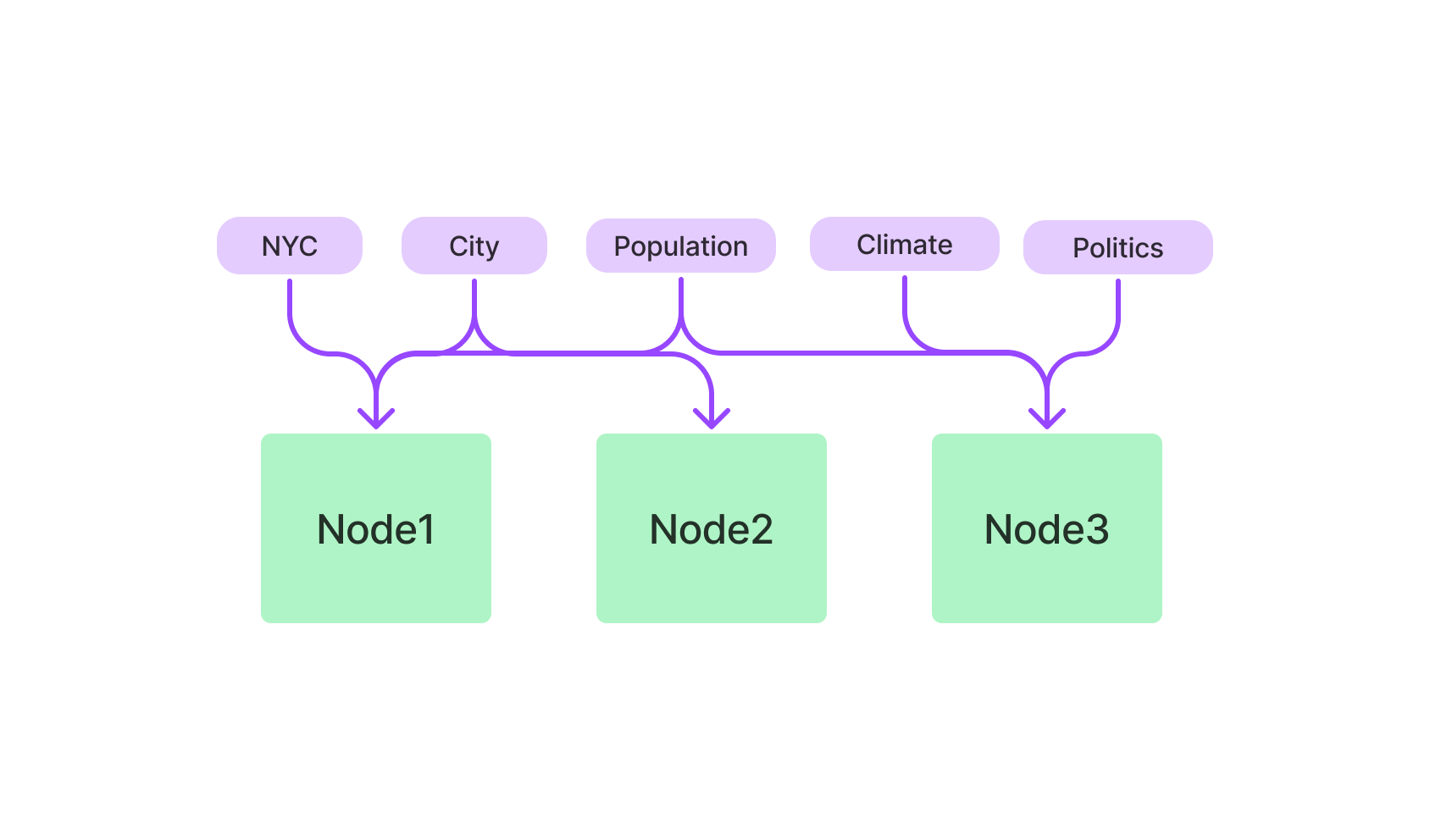
LlamaIndexパッケージからKeywordBasedIndexクラスをインポートし、初期化します。
from llamaindex import KeywordBasedIndex
text_index = KeywordBasedIndex()これで、このインデックスにテキストデータを追加し、テキストベースのクエリを実行する準備が整いました。
# テキストデータの追加
text_index.add_text(text_id="document_1", text_data="This is a sample document.")
# クエリの実行
query_result = text_index.query(text="sample", top_k=3)LlamaIndexのクイックスタート:ステップバイステップガイド
LlamaIndexのインストールと初期化は始まりに過ぎません。その力を最大限に活用するためには、効果的な使用方法を知る必要があります。
LlamaIndexのインストール
まず、マシンにLlamaIndexをインストールしましょう。ターミナルを開いて、次のコマンドを実行します:
pip install llamaindexもしくはcondaを使用している場合:
conda install -c conda-forge llamaindexLlamaIndexの初期化
インストールが完了したら、Python環境でLlamaIndexを初期化する必要があります。これにより、次に続くすべての魔法の舞台が設定されます。
from llamaindex import LlamaIndex
index = LlamaIndex(index_type="vector_store", dimensions=300)ここでindex_typeは設定するインデックスの種類を指定し、dimensionsはVector Store Indexのサイズを指定するためです。
LlamaIndexのVector Store Indexを使用してクエリする方法
LlamaIndexを正常に設定した後は、強力なクエリ機能を探索する準備が整います。Vector Store Indexは、複雑な高次元データを管理するために設計されており、機械学習、データ分析、その他の計算タスクに適したツールです。
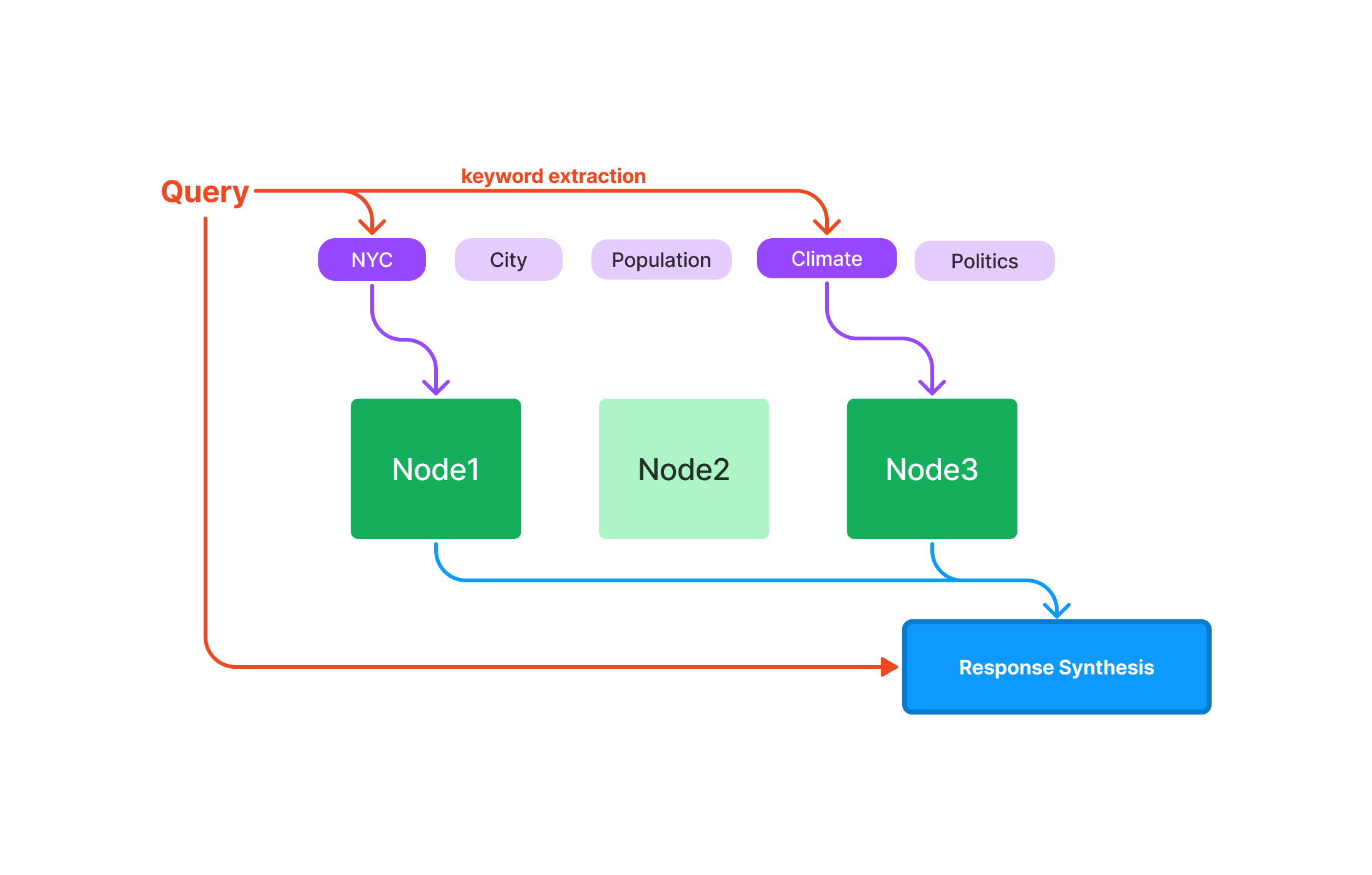
LlamaIndexで最初のクエリを作成する
コードに入る前に、LlamaIndexにおけるクエリの基本要素を理解することが重要です:
-
クエリベクトル: これは、データセット内での類似性を見つけるために興味があるベクトルです。インデックスされたベクトルと同じ次元空間にする必要があります。
-
top_kパラメータ: このパラメータは、クエリベクトルに対して取得したい最も近いベクトルの数を指定します。top_kの "k" は興味がある最近傍のベクトルの数を表します。
最初のクエリを行う手順は以下の通りです。
-
インデックスの初期化: インデックスが読み込まれ、クエリの準備ができていることを確認します。
-
クエリベクトルの指定: クエリベクトルの要素を含むリストまたは配列を作成します。
-
top_kパラメータの設定: 取得する最も近いベクトルの数を決定します。 -
クエリの実行:
queryメソッドを使用して検索を実行します。
以下はこれらの手順を説明するPythonのコードのサンプルです。
# インデックスの初期化(インデックスの名前が 'index' と仮定)
# ...
# クエリベクトルの定義
query_vector = [0.2, 0.4, 0.1, ...]
# 取得する最も近いベクトルの数を設定
top_k = 5
# クエリの実行
query_result = index.query(vector=query_vector, top_k=top_k)LlamaIndexでクエリを微調整する
なぜクエリの微調整が重要なのか?
クエリの微調整により、検索プロセスをプロジェクトの特定の要件に適応させることができます。テキスト、画像、その他のデータの処理において、微調整はクエリの精度と効率を大幅に向上させることができます。
微調整のための主なパラメータ:
-
距離メトリック: LlamaIndexでは、'euclidean'、'cosine'などの異なる距離メトリックから選択できます。
-
ユークリッド距離: ユークリッド空間における2点間の「通常の」直線距離です。ベクトルの大きさが重要な場合にこのメトリックを使用します。
-
コサイン類似度: このメトリックは、2つのベクトル間の角度の余弦を測定します。ベクトルの大きさよりもベクトルの方向に興味がある場合に使用します。
-
-
バッチサイズ: 大規模なデータセットを扱ったり、複数のクエリを実行する必要がある場合は、バッチサイズを設定することで一度に複数のベクトルをクエリすることでプロセスを高速化できます。
微調整の手順ガイド:
クエリの微調整の手順は以下の通りです。
-
距離メトリックの選択:特定のニーズに基づいて 'euclidean' または 'cosine' のいずれかを選択します。
-
バッチサイズの設定:1つのバッチで処理するベクトルの数を決定します。
-
微調整されたクエリの実行:
queryメソッドを再度使用し、新たなパラメータを含めてクエリを実行します。
以下はPythonのコードのスニペットです。
# クエリベクトルの定義
query_vector = [0.2, 0.4, 0.1, ...]
# 取得する最も近いベクトルの数を設定
top_k = 5
# 距離メトリックの選択
distance_metric = 'euclidean'
# バッチサイズの設定
batch_size = 100
# 微調整されたクエリの実行
query_result = index.query(vector=query_vector, top_k=top_k, metric=distance_metric, batch_size=batch_size)これらの微調整テクニックをマスターすることで、LlamaIndexのクエリをよりターゲット指向かつ効率的に行うことができ、高次元データから最も価値を引き出すことができます。
LlamaIndexで何ができるのか?
基本的な部分は把握しましたが、LlamaIndexを使用して実際に何を構築できるのでしょうか?特に、LlamaIndexが大規模な言語モデル(LLM)との互換性を持つことを考慮すると、可能性は広範です。
LlamaIndexを使用した高度な検索エンジン
LlamaIndexの最も魅力的な使い方の一つは、高度な検索エンジンの領域です。関連するドキュメントを取得するだけでなく、クエリのコンテキストを理解する検索エンジンを想像してみてください。LlamaIndexを使用することで、それが実現できます。
以下は、LlamaIndexのキーワードベースのインデックスを使用して基本的な検索エンジンを設定する方法の例です。
# キーワードベースのインデックスの初期化
from llamaindex import キーワードベースのインデックス
search_index = キーワードベースのインデックス()
# ドキュメントの追加
search_index.add_text("doc1", "ラマは素晴らしいです。")
search_index.add_text("doc2", "プログラミングが好きです。")
# クエリの実行
results = search_index.query("ラマ", top_k=2)LlamaIndexを使用した推薦システム
もう一つの魅力的なアプリケーションは、推薦システムの構築です。類似の製品、記事、さらには曲を提案する場合でも、LlamaIndexのベクトルストアインデックスはゲームチェンジャーになるかもしれません。
以下は、基本的な推薦システムの設定方法です。
# ベクトルストアインデックスの初期化
from llamaindex import ベクトルストアインデックス
rec_index = ベクトルストアインデックス(dimensions=50)
# 製品ベクトルの追加
rec_index.add_vector("product1", [0.1, 0.2, 0.3, ...])
rec_index.add_vector("product2", [0.4, 0.5, 0.6, ...])
# 類似した製品を見つけるためのクエリの実行
similar_products = rec_index.query(vector=[0.1, 0.2, 0.3, ...], top_k=5)LlamaIndex vs. LangChain
大規模な言語モデル(LLM)を利用したアプリケーション開発において、フレームワークの選択はプロジェクトの成功に大きな影響を与えることがあります。この領域で注目されている2つのフレームワークはLlamaIndexとLangChainです。両方には独自の機能と利点がありますが、それぞれ異なるニーズに適しており、特定のタスクに最適化されています。このセクションでは、特にチャットボットの開発におけるリトリーバル・オーグメンティッド・ジェネレーション(RAG)の文脈で、これら2つのフレームワークの主な違いを理解するのに役立つ技術的な詳細とサンプルコードを提供します。
主な機能と技術の能力
LangChain
-
汎用フレームワーク: LangChainは、さまざまなアプリケーションのための拡張性のあるツールとして設計されています。データのロード、処理、インデックスへのアクセスだけでなく、LLMとのインタラクションの機能も提供しています。
サンプルコード:
const res = await llm.call("Tell me a joke"); -
柔軟性: LangChainの特徴の1つはその柔軟性です。ユーザーはアプリケーションの動作を広範にカスタマイズすることができます。
-
高レベルなAPI: LangChainは、LLM(Large Language Models)の操作に関わる複雑さの大部分を抽象化し、使いやすくシンプルな高レベルのAPIを提供します。
サンプルコード:
const chain = new SqlDatabaseChain({ llm: new OpenAI({ temperature: 0 }), database: db, sqlOutputKey: "sql", }); const res = await chain.call({ query: "How many tracks are there?" }); -
既製のChain: LangChainには、「SqlDatabaseChain」といった既製のChainが組み込まれており、カスタマイズしたり新しいアプリケーションのベースとして使用したりすることができます。
LlamaIndex
-
検索と検索結果取得に特化: LlamaIndexは、検索と検索結果取得用に設計されています。LLMのクエリや関連するドキュメントの取得について、簡単なインタフェースを提供します。
サンプルコード:
query_engine = index.as_query_engine() response = query_engine.query("Stackoverflow is Awesome.") -
効率性: LlamaIndexはパフォーマンスを最適化しており、大量のデータを迅速に処理する必要があるアプリケーションに向いています。
-
データコネクター: LlamaIndexは、API、PDF、SQLデータベースなど、さまざまなソースからデータを読み込むことができます。これにより、LLMアプリケーションへのシームレスな統合が可能となります。
-
最適化されたインデックス作成: LlamaIndexの主な特徴の1つは、読み込まれたデータをクエリに対して迅速かつ効率的に検索できるように最適化された中間表現に構造化する能力です。
どのフレームワークを使用すべきか?
-
汎用アプリケーション: 柔軟性と多機能性を必要とするチャットボットを作成する場合、LangChainが理想的な選択です。汎用性の高い性質と高レベルのAPIにより、様々なアプリケーションに適しています。
-
検索と検索結果取得の重視: チャットボットの主な機能が検索と情報の取得である場合、LlamaIndexがより適しています。特化したインデックスと検索能力により、このようなタスクには非常に効率的です。
-
両方の組み合わせ: 特定のシナリオでは、両方のフレームワークを使用することがメリットとなる場合があります。LangChainは一般的な機能やLLMとのインタラクションを処理できますし、LlamaIndexは特化した検索と検索結果取得のタスクを管理できます。この組み合わせにより、LangChainの柔軟性とLlamaIndexの効率性を両立させるバランスの取れたアプローチが可能となります。
組み合わせ使用のサンプルコード:
# LangChainを用いた一般的な機能 res = llm.call("Tell me a joke") # LlamaIndexを用いた特化した検索 query_engine = index.as_query_engine() response = query_engine.query("Tell me about climate change.")
どちらを選ぶべきか?LangChainかLlamaIndexか?
LangChainとLlamaIndexの選択、または両方を使用するかどうかは、プロジェクトの特定の要件と目標に基づいて判断すべきです。LangChainはより広範な機能を備えており、汎用性のあるアプリケーションに適しています。一方、LlamaIndexは効率的な検索と検索結果取得に特化しており、データ集約的なタスクに向いています。各フレームワークの技術的なニュアンスと機能を理解することで、チャットボット開発ニーズに最も適した選択を行うことができます。
結論
LlamaIndexについて十分に理解できました。特化したインデックスから多様なアプリケーションまで、またLangChainなどの他のツールとの優位性を備えているLlamaIndexは、LLM(Large Language Models)を扱う人々にとって欠かせないツールです。検索エンジンや推薦システムなど、効率的なクエリ実行とデータ取得が必要なアプリケーションを構築する際にLlamaIndexを活用しましょう。
LlamaIndexに関するFAQ
LlamaIndexについてよく寄せられる質問のいくつかについて説明します。
LlamaIndexは何に使われますか?
LlamaIndexは主にユーザーとLarge Language Modelsの間の中間層として使用されます。クエリの実行、応答の生成、データの統合などに優れた機能を持ち、検索エンジンや推薦システムなどのさまざまなアプリケーションに最適です。
LlamaIndexは無料で使えますか?
はい、LlamaIndexはオープンソースのツールであり、無料で使用することができます。そのソースコードはGitHubで入手でき、開発への貢献も可能です。
GPT IndexとLlamaIndexは何ですか?
GPT Indexはテキストベースのクエリに特化しており、通常GPT (Generative Pre-trained Transformer) モデルと組み合わせて使用されます。一方、LlamaIndexはより多機能であり、テキストベースおよびベクトルベースの両方のクエリを扱うことができます。そのため、さまざまなLarge Language Modelsと互換性があります。
LlamaIndexのアーキテクチャはどのようになっていますか?
LlamaIndexは、ベクトルストアインデックスやキーワードベースのインデックスなど、さまざまなタイプのインデックスを備えたモジュラーアーキテクチャで構築されています。主にPythonで記述されており、k-NN、TF-IDF、BERTの埋め込みなど、複数のアルゴリズムをサポートしています。
最新のLLMニュースを知りたいですか?最新のLLM Leaderboardをご覧ください!
