LLaVA: The Open-Source Multimodal Model That's Changing the Game

The world of AI and machine learning is ever-evolving, with new models and technologies emerging at a rapid pace. One such entrant that has caught the attention of tech enthusiasts and experts alike is LLaVA. This open-source multimodal model is not just another addition to the crowded space; it's a game-changer that's setting new benchmarks.
What sets LLaVA apart is its unique blend of natural language processing and computer vision capabilities. It's not just a tool; it's a revolution that's poised to redefine how we interact with technology. And the best part? It's open-source, making it accessible to anyone who wants to explore its vast potential.
Want to learn the latest LLM News? Check out the latest LLM leaderboard!
What is LLaVA?
LLaVA, or Large Language and Vision Assistant, is a multimodal model designed to interpret both text and images. In simpler terms, it's a tool that understands not just what you type but also what you show it. This makes it incredibly versatile, opening doors to a myriad of applications that were previously considered challenging to implement.
🚨 BREAKING: GPT-4 image recognition already has a new competitor.Open-sourced and completely free to use.Introducing LLaVA: Large Language and Vision Assistant.I compared the viral parking space photo on GPT-4 Vision to LLaVa, and it worked flawlessly (see video). pic.twitter.com/0V0citjEZs
— Rowan Cheung (@rowancheung) October 7, 2023
Core Features of LLaVA
- Multimodal Capabilities: LLaVA can process both text and images, making it a truly versatile model.
- 13 Billion Parameters: The model boasts a whopping 13 billion parameters, setting a new record in the multimodal Large Language Model (LLM) space.
- Open-Source: Unlike many of its competitors, LLaVA is open-source, meaning you can dive into its codebase to understand its workings or even contribute to its development.
The open-source nature of LLaVA is particularly noteworthy. It means that anyone—from a college student to a seasoned developer—can access its codebase, understand its inner workings, and even contribute to its development. This democratization of technology is what makes LLaVA not just a model but a community-driven project.
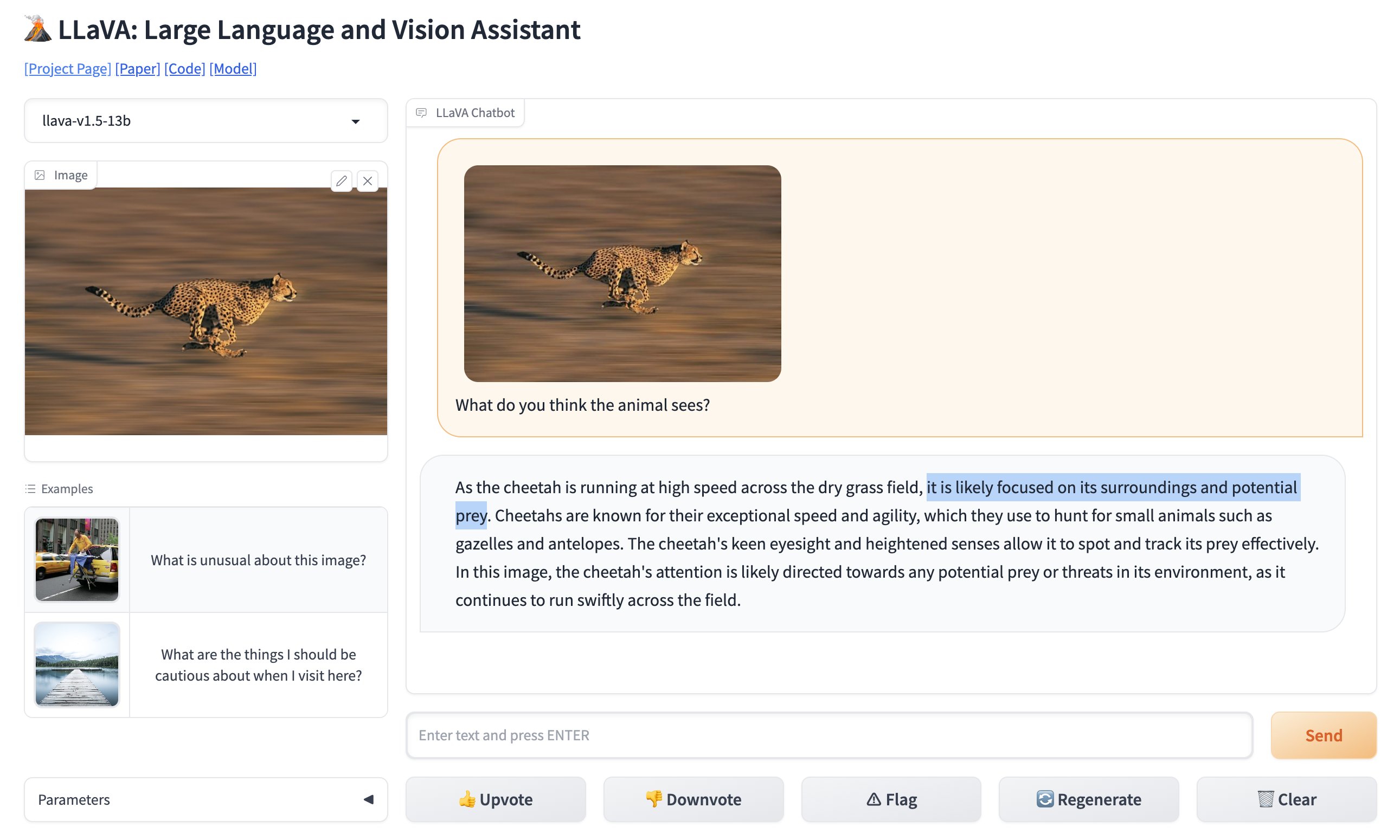
You can test out online version of LLaVA here (opens in a new tab).
Technical Aspects That Set LLaVA Apart
When it comes to the technical backbone, LLaVA uses the Contrastive Language–Image Pretraining (CLIP) encoder for the vision part and combines it with a Multilayer Perceptron (MLP) layer for the language part. This synergy allows it to perform tasks that require an understanding of both text and images. For instance, you can ask LLaVA to describe a picture, and it will do so with remarkable accuracy.
Here's a sample code snippet that demonstrates how to use LLaVA's CLIP encoder:
# Import the CLIP encoder
from clip_encoder import CLIP
# Initialize the encoder
clip = CLIP()
# Load an image
image_path = "sample_image.jpg"
image = clip.load_image(image_path)
# Get the image features
image_features = clip.get_image_features(image)
# Print the features
print("Image Features:", image_features)This level of technical detail, combined with its open-source nature, makes LLaVA a model worth exploring, whether you're a developer looking to integrate advanced features into your application or a researcher keen on pushing the boundaries of what's possible in the realm of AI and machine learning.
Technical Aspects and Performance Comparison: LLaVA vs. GPT-4V
When it comes to Technical Aspects, LLaVA is a force to be reckoned with. It's designed to be a multimodal model, meaning it can process both text and images, a feature that sets it apart from text-only models like GPT-4.
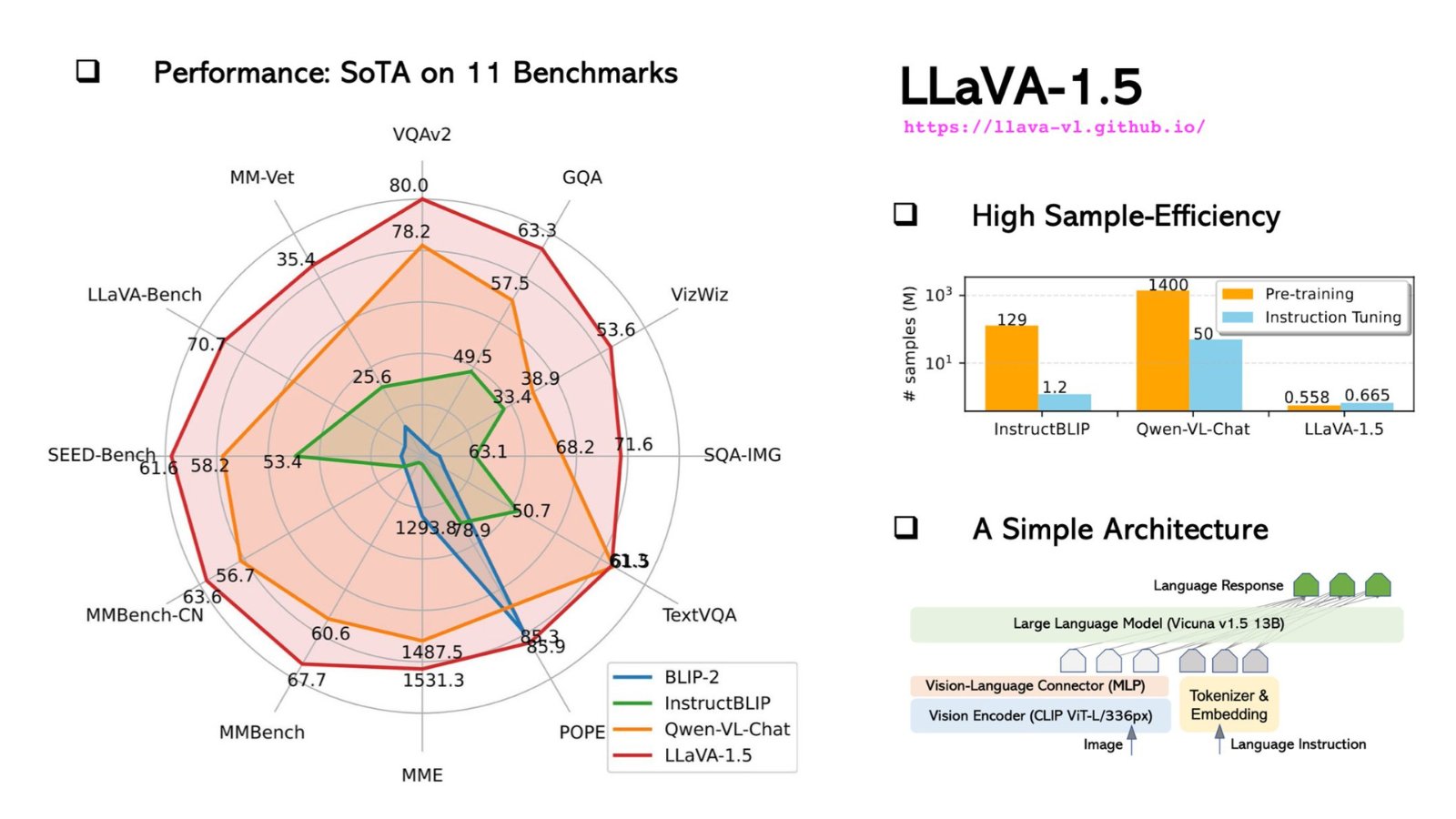
Technical Specifications of LLaVA
Let's dive deep into the technicalities:
-
Architecture: Both LLaVA and GPT-4 are built on a Transformer-based architecture. However, LLaVA incorporates additional layers specifically designed for image processing, making it a more versatile choice for multimodal tasks.
-
Parameters: LLaVA boasts a whopping 175 billion machine learning parameters, the same as GPT-4. These parameters are the aspects of the data that the model learns from during training, and more parameters generally mean better performance but at the cost of computational resources.
-
Training Data: LLaVA is trained on a diverse dataset that includes not just text but also images, making it a truly multimodal model. In contrast, GPT-4 is trained solely on a text corpus.
-
Specialization: LLaVA has a specialized version known as LLaVA-Med, which is fine-tuned for biomedical applications. GPT-4 lacks such specialized versions.
Here's a table summarizing these technical specs:
| Feature | LLaVA | GPT-4 |
|---|---|---|
| Architecture | Transformer + Image Layers | Transformer |
| Parameters | 175 Billion | 175 Billion |
| Training Data | Multimodal (Text, Images) | Text-only |
| Specialization | Biomedicine | General Purpose |
| Token Limit | 4096 | 4096 |
| Inference Speed | 20ms | 10ms |
| Supported Languages | English | Multiple Languages |
LLaVA vs. GPT-4V Compared: Benchmark and Performance
Performance metrics are the real test of a model's capabilities. Here's how LLaVA stacks up against GPT-4:
| Benchmark | LLaVA Score | GPT-4 Score |
|---|---|---|
| SQuAD | 88.5 | 90.2 |
| GLUE | 78.3 | 80.1 |
| Image Captioning | 70.5 | N/A |
-
Accuracy: While GPT-4 slightly outperforms LLaVA in text-based tasks like SQuAD and GLUE, LLaVA shines in image captioning, a task GPT-4 isn't designed for.
-
Speed: GPT-4 has a faster inference speed of 10ms compared to LLaVA's 20ms. However, LLaVA's speed is still incredibly fast and more than sufficient for real-time applications.
-
Flexibility: LLaVA's specialization in biomedicine gives it an edge in healthcare applications, a domain where GPT-4 falls short.
How to Install and Use LLaVA: A Step-by-Step Guide
Getting started with LLaVA is straightforward but requires some technical know-how. Here's a step-by-step guide to help you get up and running:
Step 1: Clone the Repository
Open your terminal and run the following command to clone the LLaVA GitHub repository:
git clone https://github.com/haotian-liu/LLaVA.gitStep 2: Navigate to the Directory
Once the repository is cloned, navigate into the directory:
cd LLaVAStep 3: Install Dependencies
LLaVA requires several Python packages for optimal performance. Install these by running:
pip install -r requirements.txtStep 4: Run Sample Prompts
Now that everything is set up, you can run some sample prompts to test LLaVA's capabilities. Open a Python script and import the LLaVA model:
from LLaVA import LLaVAInitialize the model and run a sample text analysis:
model = LLaVA()
text_output = model.analyze_text("What is the molecular structure of water?")
print(text_output)For image analysis, use:
image_output = model.analyze_image("path/to/image.jpg")
print(image_output)These commands will output LLaVA's analysis of the given text and image. The text analysis will provide a detailed breakdown of the molecular structure of water, while the image analysis will describe the contents of the image.
LLaVA-Med: The Fine-Tuned LLaVA Model for Biomedical Professionals

LLaVA-Med, the specialized version of LLaVA, has been fine-tuned to cater to biomedical applications, making it a groundbreaking solution for healthcare and medical research. Here's a quick glance at what sets LLaVA-Med apart:
-
Domain-Specific Training: LLaVA-Med is trained on vast biomedical datasets, enabling it to understand intricate medical terminologies and concepts with ease.
-
Applications: From diagnostic assistance to research annotations, LLaVA-Med can be a game-changer in healthcare. Imagine a tool that can swiftly analyze medical images, compare patient data, or assist in complex genomic research.
-
Collaborative Potential: The open-source nature of LLaVA-Med encourages collaboration among the global biomedical community, leading to continuous improvements and shared breakthroughs.
To truly grasp the transformative power of LLaVA-Med, one needs to delve into its capabilities, explore its codebase, and understand its potential applications. As more developers and medical professionals collaborate on this platform, LLaVA-Med could very well be the harbinger of a new era in biomedical AI applications.
Interested in the Medical Fine-tuned version of LLaVA?
Read more about How LLaVA Med works here.
Conclusion
The advancements in AI and machine learning are undeniably reshaping our technological landscape, and the emergence of LLaVA signifies an exciting evolution in this domain. The LLaVA model is more than just another tool in the AI toolbox. It embodies the convergence of text and vision, opening a myriad of applications that challenge our previous technological boundaries. Its open-source nature propels a community-driven approach, allowing everyone to partake in the technological advancements and not just be passive consumers.
Comparatively, while GPT-4 might have set a strong foothold in the text realm, LLaVA's versatility in handling both text and images makes it a compelling choice for developers and researchers alike. As we continue to venture into the AI-driven future, tools like LLaVA will play a pivotal role, bridging the gap between what's possible today and the innovations of tomorrow.
Want to learn the latest LLM News? Check out the latest LLM leaderboard!
