Zephyr-7b: The New Frontier in Language Models

If you've been keeping an eye on the advancements in artificial intelligence, then you've probably heard of Zephyr-7b. This isn't just another language model; it's a revolutionary step forward in the realm of AI. Designed to be more than just a chatbot, Zephyr-7b is setting new benchmarks in performance, efficiency, and utility.
In a world where AI is becoming increasingly integrated into our daily lives, Zephyr-7b stands out as a beacon of what's possible in the future of open-source artificial intelligence. Whether you're a developer, a tech enthusiast, or just someone curious about the state of the art in AI, this article is your comprehensive guide to understanding Zephyr-7b.
Want to learn the latest LLM News? Check out the latest LLM leaderboard!
What is Zephyr-7b?
Zephyr-7b is a language model that has been fine-tuned from its predecessor, Mistral-7B-v0.1. It's not just any model; it's designed to act as a helpful assistant. But what sets it apart from the rest? The answer lies in its training methodology—Direct Preference Optimization (DPO). This technique has given Zephyr-7b an edge in performance and made it more helpful than ever before.
- Model Type: It's a 7B parameter GPT-like model.
- Languages: Primarily designed for English.
- License: Operates under a CC BY-NC 4.0 license.
Zephyr-7b's Unique Features
What truly sets Zephyr-7b apart are its unique features that make it more than just a chatbot. It's designed to be helpful, efficient, and incredibly versatile.
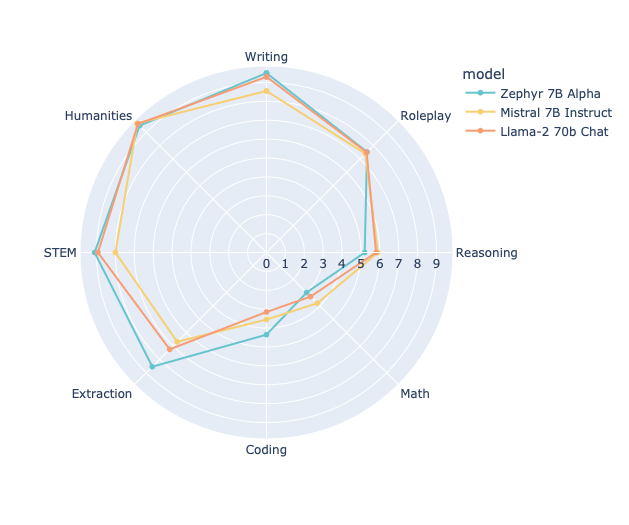
- Performance on MT Bench: Zephyr-7b has shown remarkable performance on MT Bench, outperforming other models like llama2-70b.
- Training Data: The model has been trained on a mix of publicly available and synthetic datasets, making it robust and versatile.
- Cost-Efficiency: With a total compute cost of around $500 for training, Zephyr-7b is not just powerful but also economically efficient.
The Role of Direct Preference Optimization (DPO)
DPO is a training methodology that has been instrumental in shaping Zephyr-7b. Unlike other training methods, DPO focuses on aligning the model's responses to be more in line with human preferences. This has resulted in a model that not only performs well on benchmarks but also excels in practical utility.
Here's a sample code snippet to give you an idea of how DPO works in Zephyr-7b:
import torch
from transformers import pipeline
pipe = pipeline("text-generation", model="HuggingFaceH4/zephyr-7b-alpha", torch_dtype=torch.bfloat16, device_map="auto")
messages = [
{
"role": "system",
"content": "You are a friendly chatbot who always responds in the style of a pirate",
},
{"role": "user", "content": "How many helicopters can a human eat in one sitting?"},
]
prompt = pipe.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])The Technical Specs of Zephyr-7b: What You Need to Know
When it comes to understanding the prowess of Zephyr-7b, the technical specifications are where the rubber meets the road. This section will delve into the nitty-gritty details that make this model a standout in the crowded landscape of language models.
Model Type and Parameters
Zephyr-7b is a GPT-like model with a whopping 7 billion parameters. In the world of language models, the number of parameters is often a good indicator of the model's complexity and capability.
- Model Type: GPT-like with 7B parameters
- Languages Supported: Primarily English
- License: CC BY-NC 4.0
Training Data and Methodology: The Backbone of Zephyr-7b
One of the most intriguing aspects of Zephyr-7b is its training data and methodology. Unlike many other models that rely solely on publicly available data, Zephyr-7b has been trained on a mix of public and synthetic datasets. This diverse training data has contributed to its robustness and versatility.
- Training Data: Mix of publicly available and synthetic datasets
- Training Methodology: Direct Preference Optimization (DPO)
Here's a quick look at some of the training hyperparameters used:
- Learning Rate: 5e-07
- Train Batch Size: 2
- Eval Batch Size: 4
- Seed: 42
- Optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
Evaluation Metrics: Numbers Don't Lie
Zephyr-7b has undergone rigorous evaluation to test its capabilities. The model has been evaluated on various metrics, and the numbers are quite impressive.
- Loss: 0.4605
- Rewards/Chosen: -0.5053
- Rewards/Rejected: -1.8752
- Rewards/Accuracies: 0.7812
- Rewards/Margins: 1.3699
These metrics not only validate the model's performance but also provide insights into areas where it excels and where there's room for improvement.
How to Get Started with Zephyr-7b: A Step-by-Step Guide
If you're as excited about Zephyr-7b as we are, you're probably wondering how to get your hands on it. Well, you're in luck! This section will guide you through the steps to get started with this groundbreaking model.
Repository and Demo: Your Starting Points
The first thing you'll want to do is check out the official repository and demo. These platforms provide all the resources you'll need to dive into Zephyr-7b.
- Repository: GitHub Repository (opens in a new tab)
- Demo: HuggingFace Demo (opens in a new tab)
Running Zephyr-7b: The Code You Need
Getting Zephyr-7b up and running is a straightforward process, thanks to the pipeline() function from Transformers. Below is a sample code snippet that demonstrates how to run the model.
from transformers import pipeline
import torch
# Initialize the pipeline
pipe = pipeline("text-generation", model="HuggingFaceH4/zephyr-7b-alpha", torch_dtype=torch.bfloat16, device_map="auto")
# Create a message prompt
messages = [
{"role": "system", "content": "You are a friendly chatbot."},
{"role": "user", "content": "Tell me a joke."},
]
# Generate a response
prompt = pipe.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
# Print the generated text
print(outputs[0]["generated_text"])Zephyr-7b in Action: Real-World Applications and Limitations
While it's easy to get lost in the technical details, the true test of any language model is its real-world application. Zephyr-7b is no exception, and it has been designed with practical utility in mind.
Chat and Conversational Interfaces
One of the primary applications of Zephyr-7b is in chat and conversational interfaces. The model has been fine-tuned on a variant of the UltraChat dataset, making it adept at handling a wide range of conversational scenarios. Whether you're building a customer service bot or an interactive game, Zephyr-7b has got you covered.
Text Generation and Content Creation
Another area where Zephyr-7b shines is text generation. Whether you're looking to auto-generate articles, create dynamic responses for a website, or even write code, Zephyr-7b's text generation capabilities are up to the task.
Limitations: What to Watch Out For
While Zephyr-7b is a powerful tool, it's important to be aware of its limitations. The model has not been aligned to human preferences with techniques like RLHF, which means it can produce problematic outputs if not properly managed. Always ensure you have adequate filtering mechanisms in place when deploying Zephyr-7b in real-world applications.
The Future of Zephyr-7b: What's Next?
As we look to the future, it's clear that Zephyr-7b is just the beginning. With ongoing research and development, we can expect even more advanced versions of this model, further pushing the boundaries of what's possible in the realm of language models.
Upcoming Features and Enhancements
While the current version of Zephyr-7b is impressive, there are several features and enhancements in the pipeline. These include but are not limited to:
- Improved alignment techniques for better human-like interaction
- Expansion into multiple languages beyond English
- More robust handling of complex queries and tasks
The Broader Impact: Setting a New Standard
Zephyr-7b is not just a model; it's a statement of what's possible in the world of open-source AI. By setting new benchmarks in performance, efficiency, and utility, Zephyr-7b is paving the way for future models and shaping the landscape of artificial intelligence.
Conclusion: Why Zephyr-7b Matters
In a world teeming with language models, Zephyr-7b stands out as a beacon of innovation and practical utility. From its unique training methodology to its diverse range of applications, this model is a game-changer in the field of AI.
Whether you're a developer looking to integrate advanced AI into your projects or a tech enthusiast eager to explore the latest advancements, Zephyr-7b offers something for everyone. Its technical prowess, real-world applications, and future potential make it a model worth exploring.
So, if you're ready to dive into the future of open-source AI, Zephyr-7b is your ticket. Don't miss out on the revolution; get started with Zephyr-7b today!
Want to learn the latest LLM News? Check out the latest LLM leaderboard!
