How to Run Mistral Models Locally - A Complete Guide

In the rapidly evolving landscape of artificial intelligence, Mistral AI has emerged as a beacon of innovation, charting new territories in the realm of large language models (LLMs). With the introduction of its groundbreaking models, Mistral AI not only advances the frontier of machine learning but also democratizes access to cutting-edge technology. This guide aims to elucidate the intricacies of Mistral AI's offerings and provide a comprehensive roadmap for harnessing their capabilities locally.
What Are These Mistral AI Models?
Mistral AI has unveiled a suite of language models that are not just iterations but leaps in computational linguistics. At the heart of this suite are Mistral 7B and Mixtral 8x7B, each designed to cater to diverse needs and computational capabilities.
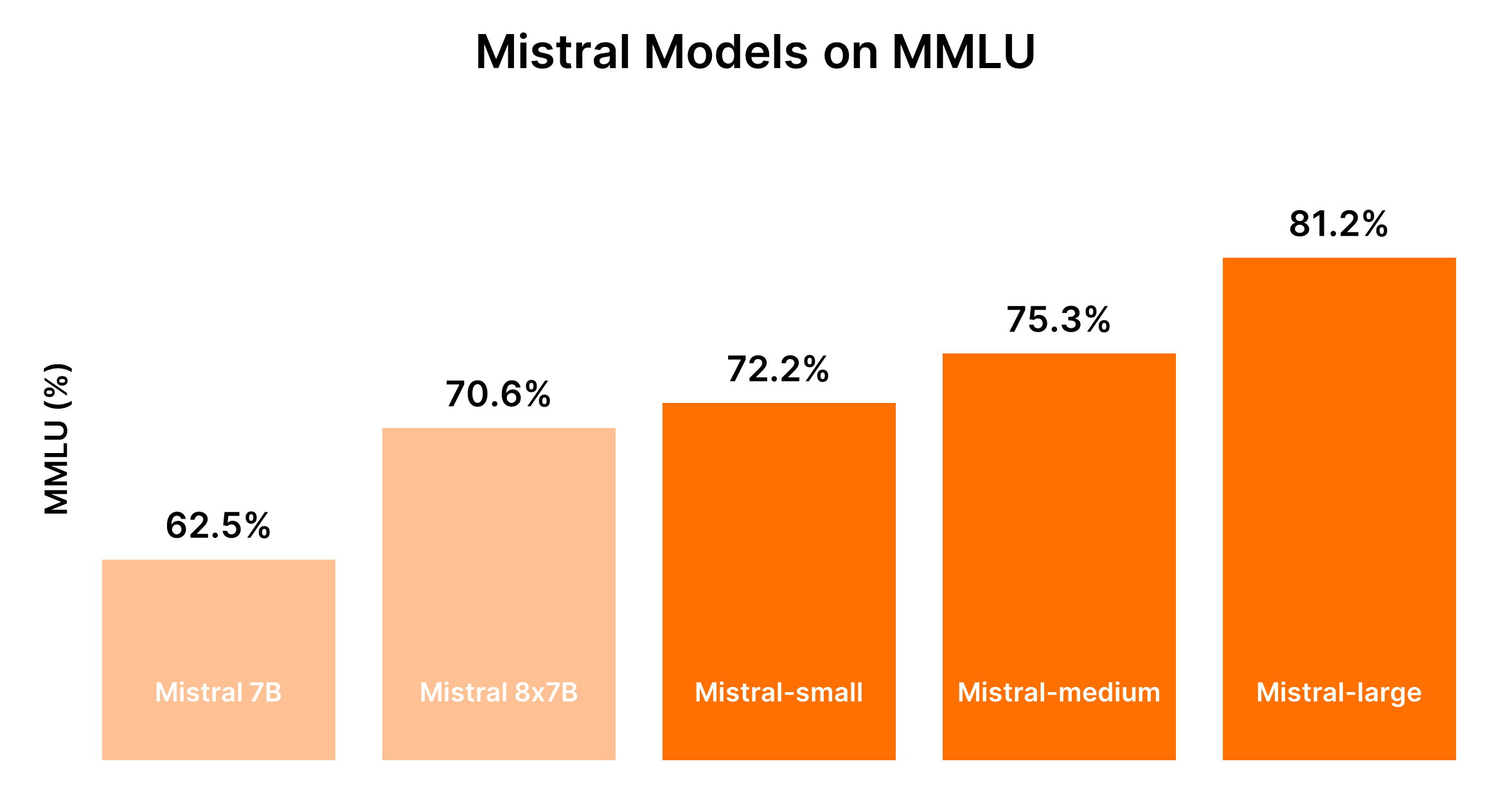
Comparing Mistral AI Models (Mistral 7B vs Mistral 8x7b vs Mistral Small vs Mistral Medium vs Mistral Large)
Understood. Based on the input provided and focusing on creating tables in markdown format for direct comparison, let's structure the comparative analysis of the Mistral AI models.
Comparative Analysis of Mistral AI Models
Mistral AI offers a range of models, each tailored for different use cases, from simple bulk tasks to complex reasoning capabilities. Below are comparative analyses and performance outputs in markdown format for a clear understanding.
Model Overview and Use Cases
| Model ID | Alias | Use Cases |
|---|---|---|
| open-mistral-7b | mistral-tiny-2312 | Simple bulk tasks like classification, customer support, or text generation |
| open-mixtral-8x7b | mistral-small-2312 | Similar to open-mistral-7b, suitable for simple bulk tasks |
| mistral-small-latest | mistral-small-2402 | Slightly advanced tasks requiring minimal reasoning |
| mistral-medium-latest | mistral-medium-2312 | Intermediate tasks such as data extraction, summarizing documents, writing emails |
| mistral-large-latest | mistral-large-2402 | Complex tasks requiring large reasoning capabilities, like synthetic text generation, code generation |
Performance and Cost Trade-offs
The performance of Mistral models is generally proportional to their size, with larger models providing enhanced capabilities but at higher costs. The following table encapsulates performance rankings based on the MMLU benchmark and generalized cost considerations.
| Model | Performance Ranking | Cost Consideration |
|---|---|---|
| Mistral 7B (tiny-2312) | 5th | Most cost-effective for simple tasks |
| Mixtral 8x7B (small-2312) | 4th | Cost-effective for simple tasks in bulk |
| Mistral Small (small-2402) | 3rd | Moderate cost, suited for tasks with minimal reasoning |
| Mistral Medium (medium-2312) | 2nd | Higher cost, balanced performance for intermediate tasks |
| Mistral Large (large-2402) | 1st | Highest cost, unparalleled performance for complex tasks |
Given the dynamic nature of LLM performance and associated costs, it is advised to refer to current benchmarks and pricing for the most accurate comparison. For up-to-date benchmarks and performance insights, platforms like Hugging Face's Chatbot Arena Leaderboard (opens in a new tab) and Artificial Analysis (opens in a new tab) can provide valuable information.
Decision Guidance: Which Mistral AI Model You Should Choose?
Selecting the right model depends on balancing performance needs against cost constraints, considering the complexity of tasks your application intends to handle.
- For Simple Tasks: Begin with Mistral Small or Mistral 7B for cost-efficiency.
- For Intermediate to Complex Tasks: Assess whether the improved performance of Mistral Medium or Mistral Large justifies the additional expense based on your specific application needs.
This structured comparison aims to facilitate informed decisions when selecting from Mistral AI's model offerings, ensuring the chosen model aligns with both the functional requirements and budgetary constraints of your project.

Part 1. How to Run Mistral Locally with Ollama (the Easy Way)
Running Mistral AI models locally with Ollama provides an accessible way to harness the power of these advanced LLMs right on your machine. This approach is ideal for developers, researchers, and enthusiasts looking to experiment with AI-driven text analysis, generation, and more, without relying on cloud services. Here's a concise guide to get you started:
Step 1: Download Ollama
- Visit the Ollama download page and choose the appropriate version for your operating system. For macOS users, you'll download a
.dmgfile. - Install Ollama by dragging the downloaded file into your
/Applicationsdirectory.
Step 2: Explore Ollama Commands
Open your terminal and enter ollama to see the list of available commands. You'll see options like serve, create, show, run, pull, and more.
Step 3: Install Mistral AI
To install a Mistral AI model, first, you need to find the model you want to install. If you're interested in the Mistral:instruct version, you can install it directly or pull it if it's not already on your machine.
- To directly run (and download if necessary):
ollama run mistral:instruct - To pre-download the model:
ollama pull mistral:instruct
Step 4: Interact with Mistral AI
Once the model is installed, you can interact with it in interactive mode or by passing inputs directly.
-
For interactive mode:
ollama run mistral --verboseThen follow the prompts to enter your queries.
-
For non-interactive mode (direct input): Suppose you have an article you want summarized saved in
bbc.txt. You can pass the article content directly to Mistral for summarization:ollama run mistral --verbose "Please can you summarise this article: $(cat bbc.txt)"Replace
"Please can you summarise this article: $(cat bbc.txt)"with any prompt relevant to your task.
Sample Output Analysis
Your terminal will display the model's output, including the summary or response to your prompt. It's fascinating to see how Mistral processes and understands complex queries, even offering corrections when prompted about inaccuracies.
Running Mistral AI from the HTTP API
Ollama also supports an HTTP API, allowing for programmatic interaction with the models.
- Sample
curlrequest:curl -X POST http://localhost:11434/api/generate -d '{ "model": "mistral", "prompt": "What is the sentiment of this sentence: The situation surrounding the video assistant referee is at crisis point." }'
This method outputs JSON responses that can be parsed programmatically, offering a flexible way to integrate Mistral AI's capabilities into applications.
Running Mistral AI with Ollama on a local machine opens up vast possibilities for leveraging AI in personal projects, development, and research. The ease of installation and use, combined with the power of Mistral's LLMs, makes this a compelling option for anyone interested in exploring the frontiers of AI technology.
Part 2. How to Run Mistral 7B Locally on Windows
Mistral 7B can be accessed through multiple platforms, including HuggingFace, Vertex AI, Replicate, Sagemaker Jumpstart, and Baseten. Kaggle’s "Models" feature also offers a streamlined approach, enabling you to start with inference or fine-tuning within minutes without the need for downloading the model or dataset.
Preliminaries for Accessing Mistral 7B
Before diving in, ensure your environment is up-to-date to avoid common errors such as KeyError: 'mistral':
!pip install -q -U transformers
!pip install -q -U accelerate
!pip install -q -U bitsandbytesImplementing 4-bit Quantization
To expedite model loading and reduce memory usage, 4-bit quantization is utilized:
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig, pipeline
import torch
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
)Loading Mistral 7B in Kaggle Notebooks
Kaggle Notebooks facilitate the addition of Mistral 7B through a simple UI interaction. After selecting the appropriate model variation and version, you can easily load the model and tokenizer for use:
model_name = "/kaggle/input/mistral/pytorch/7b-v0.1-hf/1"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
load_in_4bit=True,
quantization_config=bnb_config,
torch_dtype=torch.bfloat16,
device_map="auto",
trust_remote_code=True,
)Utilizing the pipeline function simplifies the response generation process based on the given prompt.
Sample Inference
By setting a prompt and invoking the pipeline, Mistral 7B generates coherent and contextually relevant responses, illustrating its understanding of complex concepts like regularization in machine learning:
prompt = "As a data scientist, can you explain the concept of regularization in machine learning?"
sequences = pipe(
prompt,
do_sample=True,
max_new_tokens=100,
temperature=0.7,
top_k=50,
top_p=0.95,
num_return_sequences=1,
)
print(sequences[0]['generated_text'])How to Fine-tune Mistral 7B
The fine-tuning process involves updating libraries, setting up modules, and adapting the model to your dataset. Using Kaggle Notebooks, API keys for services like Hugging Face and Weights & Biases are securely stored and accessed. This section details the essential steps and configurations for effective fine-tuning, ensuring you maximize the model's potential on your specific dataset.
- Update and Install Necessary Libraries: Ensures compatibility and access to the latest features for fine-tuning.
- Load Modules and Set Up API Access: Facilitates interaction with external services and model repositories.
- Configure and Train the Model: Tailors the model to fit the nuances of your dataset, leveraging the power of PEFT (Parameter-efficient Fine-tuning) for efficient training.
- Evaluate and Save Your Model: Assesses the model’s performance and saves the fine-tuned
The detailed walkthrough aims to equip you with the tools and knowledge to leverage the Mistral 7B model's capabilities effectively. From accessing the model to fine-tuning it on a specific dataset, each step is designed to enhance your project's natural language processing capabilities.
Part 3. How to Run Mixtral 8x7b Locally with LlamaIndex and Ollama

The European AI powerhouse Mistral AI recently unveiled its "mixture of experts" model, Mixtral 8x7b. This model, featuring eight experts each trained with 7 billion parameters, has sparked significant interest for matching or even surpassing the performance of GPT-3.5 and Llama2 70b across various benchmarks.
Step 1: Install Ollama
Ollama, an open-source tool available for MacOS, Linux, and Windows (via Windows Subsystem For Linux), simplifies the process of running local models. With Ollama, you can initiate Mixtral with a single command:
ollama run mixtralThis command downloads the model (which might take some time) and requires a significant amount of RAM (48GB) to run smoothly. For systems with lower specs, Mistral 7b is a viable alternative.
Step 2: Install Dependencies
To integrate Mixtral with LlamaIndex, you'll need several dependencies. Install them using pip:
pip install llama-index qdrant_client torch transformersStep 3: Smoke Test
Verify the setup with a "smoke test" using Ollama and LlamaIndex:
from llama_index.llms import Ollama
llm = Ollama(model="mixtral")
response = llm.complete("Who is Laurie Voss?")
print(response)Step 4: Load Data and Index It
Preparing Data:
Use any dataset for this example; here, we use a collection of tweets. Qdrant, an open-source vector database, stores the data. The following code snippets showcase the process of loading and indexing the data with Qdrant and LlamaIndex:
from pathlib import Path
import qdrant_client
from llama_index import VectorStoreIndex, ServiceContext, download_loader
from llama_index.llms import Ollama
from llama_index.storage.storage_context import StorageContext
from llama_index.vector_stores.qdrant import QdrantVectorStore
## Initialize Qdrant and load tweets
client = qdrant_client.QdrantClient(path="./qdrant_data")
vector_store = QdrantVectorStore(client=client, collection_name="tweets")
storage_context = StorageContext.from_defaults(vector_store=vector_store)
## Set up Service Context with Mixtral and embed locally
llm = Ollama(model="mixtral")
service_context = ServiceContext.from_defaults(llm=llm, embed_model="local")
## Index and query data
index = VectorStoreIndex.from_documents(documents, service_context=service_context, storage_context=storage_context)
query_engine = index.as_query_engine()
response = query_engine.query("What does the author think about Star Trek? Give details.")
print(response)Verifying the Index:
The final step involves using the pre-built index to answer queries. This process does not require reloading the data as it's already indexed in Qdrant:
import qdrant_client
from llama_index import VectorStoreIndex, ServiceContext
from llama_index.llms import Ollama
from llama_index.vector_stores.qdrant import QdrantVectorStore
## Load the vector store and Mixtral
client = qdrant_client.QdrantClient(path="./qdrant_data")
vector_store = QdrantVectorStore(client=client, collection_name="tweets")
llm = Ollama(model="mixtral")
service_context = ServiceContext.from_defaults(llm=llm, embed_model="local")
## Load index and query
index = VectorStoreIndex.from_vector_store(vector_store=vector_store, service_context=service_context)
query_engine = index.as_query_engine(similarity_top_k=20)
response = query_engine.query("Does the author like SQL? Give details.")
print(response)Part 4. How to Run Mistral 8x7B Locally with llama.cpp
Running Mistral AI models locally has become more accessible thanks to tools like llama.cpp and the llm-llama-cpp plugin. The release of the Mixtral 8x7B model, a high-quality sparse mixture of experts (SMoE) model, marked a significant advancement in the openly licensed AI landscape. Here's a brief guide on how you can run Mixtral 8x7B locally using llama.cpp and related tools.
Installing and Running Mixtral 8x7B Locally
-
Install the LLM Tool: First, ensure you have LLM installed on your machine. LLM acts as a bridge for running various AI models locally.
pipx install llm -
Install the
llm-llama-cppPlugin: This plugin is necessary to run Mixtral and other models supported byllama.cpp.llm install llm-llama-cpp -
Set Up
llama-cpp-python: For Apple Silicon Macs, the setup might include enabling support for Metal:CMAKE_ARGS="-DLLAMA_METAL=on" FORCE_CMAKE=1 llm install llama-cpp-pythonDetailed instructions can vary based on your platform, so refer to the
llm-llama-cppREADME for guidance. -
Download the Mixtral Model: You'll need the GGUF file for Mixtral 8x7B. Choose a suitable file size for your needs; for instance, the 36GB variant for the Instruct version of the model:
curl -LO 'https://huggingface.co/TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF/resolve/main/mixtral-8x7b-instruct-v0.1.Q6_K.gguf?download=true' -
Run the Model: With the model downloaded, you can run Mixtral 8x7B using the
llmtool:llm -m gguf -o path mixtral-8x7b-instruct-v0.1.Q6_K.gguf '[INST] Write a Python function that downloads a file from a URL[/INST]'This command specifies to use the GGUF model with the
-m ggufoption and provides the path to the downloaded GGUF file with-o path.
Additional Considerations
-
Interactive Mode: If you're looking to interact with the model in a more conversational manner, consider running
llmin interactive mode. This mode allows for a back-and-forth dialogue with the AI model. -
Prompt Construction: The
[INST]prefix in the command example above indicates the instruction-based nature of the prompt, suitable for instruct versions of models. Tailor your prompts to fit the model's expected input format for optimal results.
Part 5. Running Mistral 7B Locally on an iPhone

Running the Mistral 7B model on an iPhone involves a few technical steps, as iOS devices typically have more restrictions than desktop environments. Here's a simplified step-by-step guide:
-
Prerequisites:
- Ensure your iPhone is running the latest iOS version to avoid compatibility issues.
- Install an iOS app development environment, like Xcode, on your Mac, to compile and run the custom app that will use Mistral 7B.
-
Choosing the Execution Option: For iPhone deployment,
llm-llama-cppmight be the most suitable due to its compatibility with C++ environments, which can be integrated into iOS projects. -
Setting Up the Development Environment:
- Download the GGUF file for
llm-llama-cppfrom the official repository. - Open Xcode and create a new iOS project.
- Integrate the
llm-llama-cpplibrary into your project. This might require additional dependencies, so refer to the documentation.
- Download the GGUF file for
-
Coding:
- Write Swift or Objective-C code to interface with the C++ library. This could involve creating a bridging header to use C++ code in Swift projects.
- Initialize the model within your app, handling any required configuration, such as model path and parameters.
-
Testing and Deployment:
- Test the app on your iPhone, ensuring the model runs smoothly and performs as expected.
- Deploy the app through Xcode, either for personal use or, if compliant with Apple's guidelines, submit it to the App Store.
Part 6. Running Mistral AI Locally with API

To run Mistral AI locally using its API, follow these steps, ensuring you have an environment capable of HTTP requests, like Postman for testing or programming languages with HTTP request capabilities (e.g., Python with the requests library).
Prerequisites:
- Obtain an API key (opens in a new tab) by signing up for Mistral API access.
- Ensure your local environment has internet access to communicate with the Mistral API servers.
- Install the
llm-mistralplugin for your local environment. This could involve adding it to your project dependencies in case of a programming project. - Configure your project or tool to use your Mistral API key. Typically, this involves setting the key in a configuration file or as an environment variable.
Create Chat Completions
This API endpoint allows you to generate text completions based on a prompt. The request requires specifying the model, messages (prompts), and various parameters to control the generation process like temperature, top_p, and max_tokens.
Sample Python Code for Chat Completions:
import requests
url = "https://api.mistral.ai/chat/completions"
payload = {
"model": "mistral-small-latest",
"messages": [{"role": "user", "content": "How do I start using Mistral AI?"}],
"temperature": 0.7,
"top_p": 1,
"max_tokens": 512,
"stream": False,
"safe_prompt": False,
"random_seed": 1337
}
headers = {
"Authorization": "Bearer YOUR_API_KEY",
"Content-Type": "application/json"
}
response = requests.post(url, json=payload, headers=headers)
if response.status_code == 200:
print(response.json())
else:
print("Error:", response.text)Create Embeddings
The embeddings API endpoint is used for converting text into high-dimensional vectors. This can be useful for tasks like semantic search, clustering, or finding similar texts.
Sample Python Code for Creating Embeddings:
import requests
url = "https://api.mistral.ai/embeddings"
payload = {
"model": "mistral-embed",
"input": ["Hello", "world"],
"encoding_format": "float"
}
headers = {
"Authorization": "Bearer YOUR_API_KEY",
"Content-Type": "application/json"
}
response = requests.post(url, json=payload, headers=headers)
if response.status_code == 200:
print(response.json())
else:
print("Error:", response.text)List Available Models
This API call is straightforward and lets you retrieve a list of all models accessible to you. This can help in dynamically selecting models for various tasks based on their capabilities or your requirements.
Sample Python Code for Listing Available Models:
import requests
url = "https://api.mistral.ai/models"
headers = {
"Authorization": "Bearer YOUR_API_KEY"
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
print(response.json())
else:
print("Error:", response.text)These samples provide a foundation for interacting with Mistral AI's API, enabling the creation of sophisticated AI-driven applications. Remember to replace "YOUR_API_KEY" with your actual API key.
These steps offer a basic outline for integrating and utilizing the Mistral 7B AI model locally on an iPhone and through its API. Adaptations may be necessary based on specific project requirements or platform updates.