Introduction to Jamba, the Groundbreaking SSM-Transformer Model

AI21 Labs is proud to present Jamba, the world's first production-grade model based on the revolutionary Mamba architecture. By seamlessly integrating Mamba Structured State Space (SSM) technology with elements of the traditional Transformer architecture, Jamba overcomes the limitations of pure SSM models, delivering exceptional performance and efficiency.
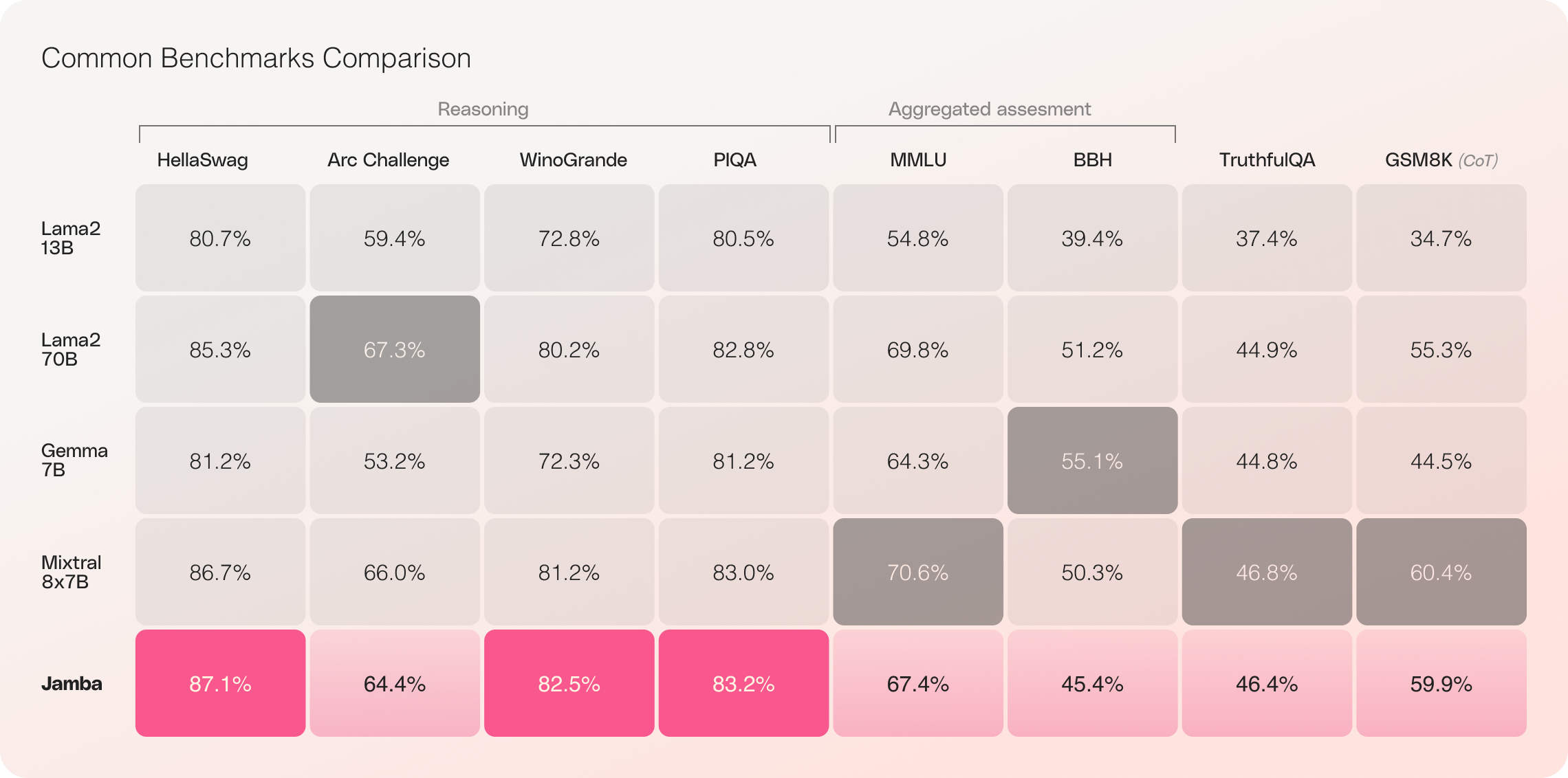
With its impressive 256K context window and remarkable throughput gains, Jamba is poised to reshape the AI landscape, opening up new possibilities for researchers, developers, and businesses alike. Jamba has already demonstrated outstanding results on a wide range of benchmarks, matching or surpassing other state-of-the-art models in its size class.
TLDR: Jamba does not have safety moderation mechanisms and guardrails, and uses Apache-2.0 Open Source License.

Key Features of Jamba
- First production-grade Mamba-based model: Jamba pioneers the use of the SSM-Transformer hybrid architecture at a production-grade scale and quality.
- Unparalleled throughput: Jamba achieves 3x throughput on long contexts compared to Mixtral 8x7B, setting new standards for efficiency.
- Massive context window: With a 256K context window, Jamba democratizes access to extensive context handling capabilities.
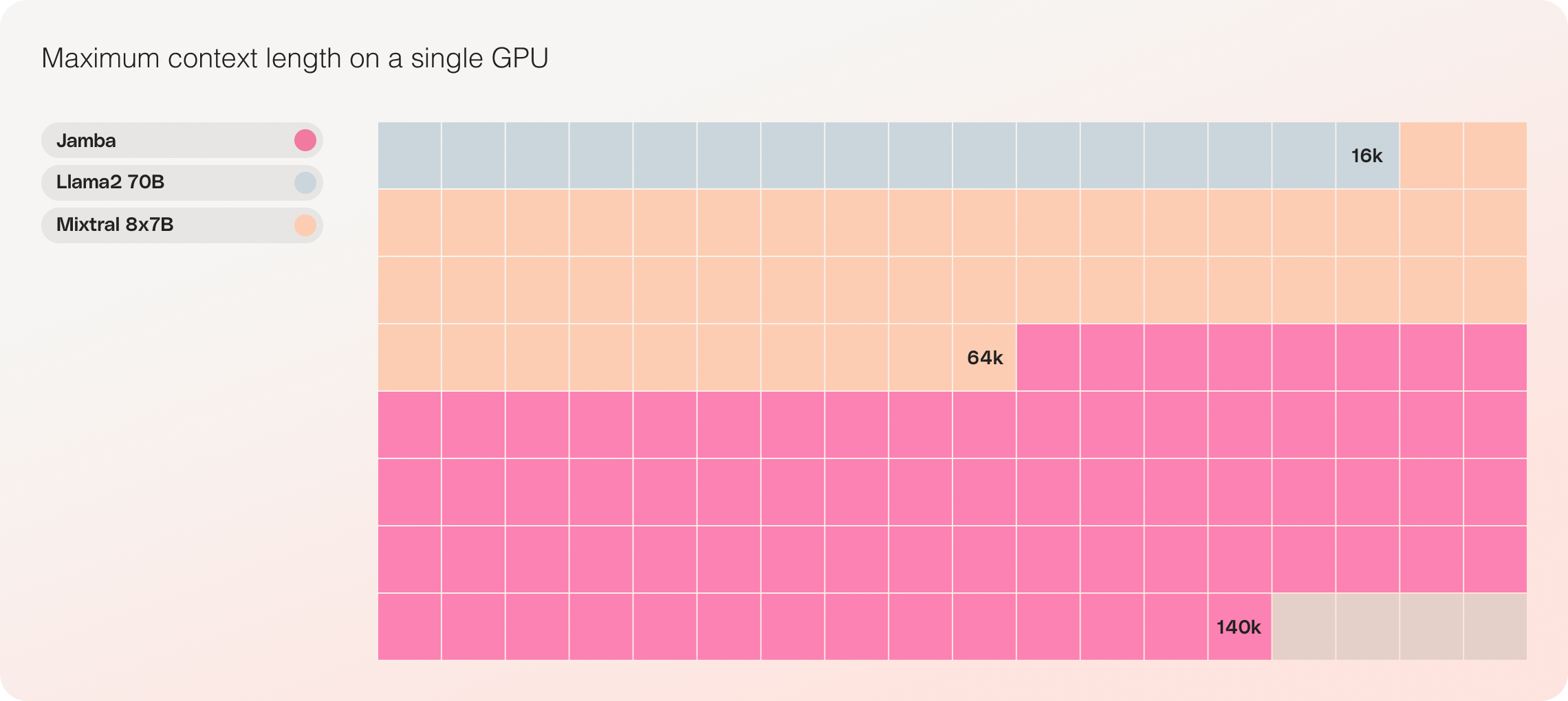
- Single GPU compatibility: Jamba is the only model in its size class that can fit up to 140K context on a single GPU, making it more accessible for deployment and experimentation.
- Open-source availability: Released with open weights under the Apache 2.0 license, Jamba invites further optimizations and discoveries from the AI community.
- Upcoming NVIDIA API catalog integration: Jamba will soon be accessible from the NVIDIA API catalog as an NVIDIA NIM inference microservice, enabling enterprise applications developers to deploy it using the NVIDIA AI Enterprise software platform.
Jamba: Combining the Best of Mamba and Transformer Architectures
Jamba represents a significant milestone in LLM innovation by successfully incorporating Mamba alongside the Transformer architecture and scaling the hybrid SSM-Transformer model to production-grade quality.
Traditional Transformer-based LLMs face two major challenges:
- Large memory footprint: Transformer's memory footprint increases with context length, making it difficult to run long context windows or numerous parallel batches without extensive hardware resources.
- Slow inference on long contexts: The attention mechanism in Transformers scales quadratically with sequence length, slowing down throughput as each token depends on the entire preceding sequence.
Mamba, proposed by researchers at Carnegie Mellon and Princeton Universities, addresses these shortcomings. However, without attention over the entire context, Mamba struggles to match the output quality of the best existing models, particularly on recall-related tasks.

Jamba vs Mamba vs Transformer
Jamba's hybrid architecture, composed of Transformer, Mamba, and mixture-of-experts (MoE) layers, optimizes for memory, throughput, and performance simultaneously. The MoE layers allow Jamba to utilize just 12B of its 52B parameters during inference, making those active parameters more efficient than a Transformer-only model of equivalent size.
Scaling Jamba's Hybrid Architecture
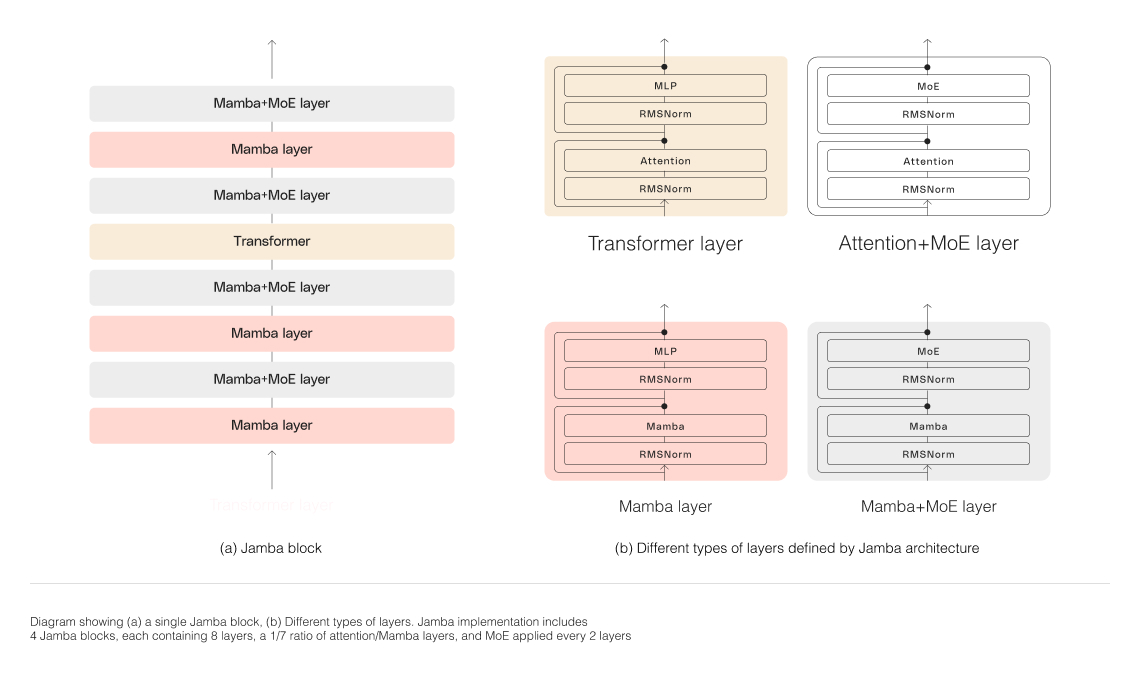
To successfully scale Jamba's hybrid structure, AI21 Labs implemented several core architectural innovations:
-
Blocks-and-layers approach: Jamba's architecture features a blocks-and-layers approach, allowing seamless integration of the Transformer and Mamba architectures. Each Jamba block contains either an attention or a Mamba layer, followed by a multi-layer perceptron (MLP), resulting in an overall ratio of one Transformer layer out of every eight layers.
-
Mixture-of-Experts (MoE) utilization: By employing MoE layers, Jamba increases the total number of model parameters while streamlining the number of active parameters used during inference. This results in higher model capacity without a corresponding increase in compute requirements. The number of MoE layers and experts has been optimized to maximize the model's quality and throughput on a single 80GB GPU while leaving sufficient memory for common inference workloads.
Jamba's Impressive Performance and Efficiency
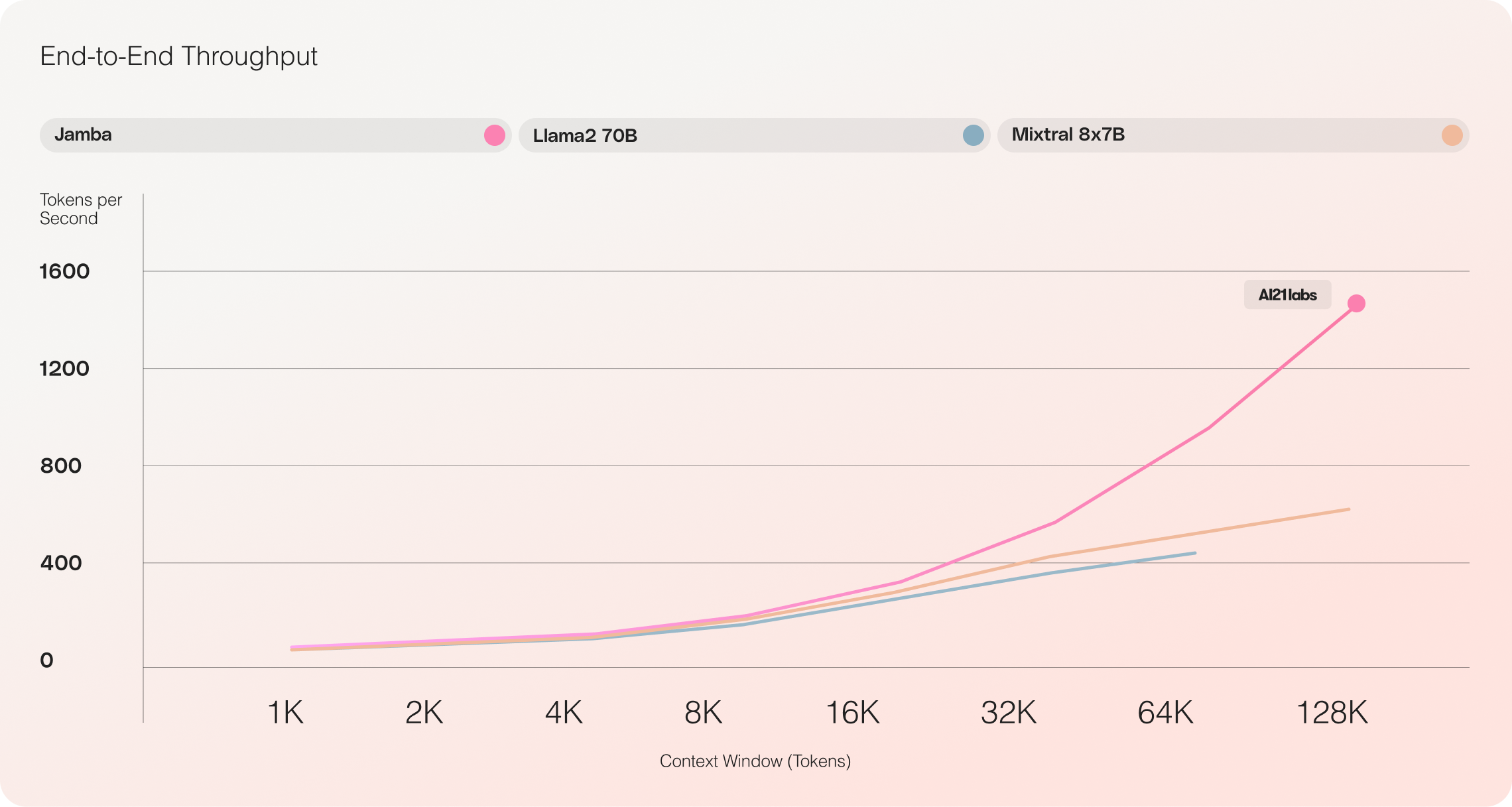
Jamba vs Llama 70B vs Mixtral 8x7B
Initial evaluations of Jamba have yielded impressive results across key metrics such as throughput and efficiency. These benchmarks are expected to improve further as the community continues to experiment with and optimize this groundbreaking technology.
- Efficiency: Jamba delivers 3x throughput on long contexts, making it more efficient than comparable Transformer-based models like Mixtral 8x7B.
- Cost-effectiveness: With its ability to fit 140K context on a single GPU, Jamba enables more accessible deployment and experimentation opportunities compared to other open-source models of similar size.
Future optimizations, such as enhanced MoE parallelism and faster Mamba implementations, are expected to further boost these already impressive gains.
Start Building with Jamba
Jamba is now available on Hugging Face, released with open weights under the Apache 2.0 license. As a base model, Jamba is intended to serve as a foundation for fine-tuning, training, and developing custom solutions. It is essential to add appropriate guardrails for responsible and safe use.
An instruct version of Jamba will soon be available in beta via the AI21 Platform. To share your projects, provide feedback, or ask questions, join the conversation on Discord.
Conclusion
Jamba's introduction marks a significant leap forward in AI technology, showcasing the immense potential of hybrid SSM-Transformer architectures. By combining the strengths of Mamba and Transformer while optimizing for efficiency and performance, Jamba sets new standards for AI models in its size class.
With its impressive context handling, throughput, and cost-effectiveness, Jamba is poised to revolutionize the AI landscape, enabling researchers, developers, and businesses to push the boundaries of what's possible. As the community continues to explore and build upon Jamba's innovations, we can anticipate a new wave of AI applications that will shape the future of artificial intelligence.