LLaVA-Med: The Next Big Leap in Biomedical Imaging

The world of medical imaging is witnessing a paradigm shift. Gone are the days when healthcare professionals solely depended on their keen eyesight and years of experience to interpret medical scans. Enter LLaVA-Med, a specialized variant of the renowned LLaVA model, designed exclusively for the biomedical sector. This powerful tool is not just another piece of tech; it represents the future of diagnosis and treatment planning. Whether it's X-rays, MRIs, or intricate 3D scans, LLaVA-Med offers unparalleled insights, bridging the gap between traditional practices and cutting-edge AI technology.
Imagine having an assistant that can provide an in-depth analysis of any medical image or text at your fingertips. That's LLaVA-Med for you. Offering a blend of accuracy and multi-modal capabilities, it’s set to be an indispensable companion for healthcare professionals worldwide. Let’s embark on a journey to discover what makes this tool so exceptional.
Want to learn the latest LLM News? Check out the latest LLM leaderboard!
What is LLaVA-Med?
LLaVA-Med is a unique variant of the LLaVA model, specifically fine-tuned for the biomedical sector. It's designed to interpret and analyze medical images and texts, making it an invaluable tool for healthcare professionals. Whether you're looking at X-rays, MRIs, or complex 3D scans, LLaVA-Med provides detailed insights that can aid in diagnosis and treatment planning.
Microsoft fine-tuned the open-source #LLaVA, creating LLaVA-Med, a vision-language model able to interpret biomedical images. Imagine fine-tuning this model to read studies from your institution, generating texts that are both accurate and tailored to your language and tone. pic.twitter.com/rnSOWITTLB
— Paulo Kuriki, MD (@kuriki) October 8, 2023
What Makes LLaVA-Med Unique?
-
Fine-Tuned for Medical Data: Unlike the general-purpose LLaVA model, LLaVA-Med is trained on a specialized dataset comprising medical journals, clinical notes, and a vast array of medical images.
-
High Accuracy: LLaVA-Med boasts impressive accuracy rates when interpreting medical images, often outperforming other medical imaging software.
-
Multi-Modal Capabilities: LLaVA-Med can analyze both text and images, making it ideal for interpreting patient records that often contain a mix of written notes and medical images.
Evaluating LLaVA-Med: How Good Is It?
Certainly, I'll integrate the information from the provided table into the text.
1. LLaVA-Med's Proficiency in Visual Biomedical Interpretations:
Rooted in the expansive LLaVA model, LLaVA-Med's excellence is distinctively emphasized on interpreting biomedical visual data.
-
Benchmark Datasets for Evaluation: LLaVA-Med, as well as other models, are gauged on various datasets, with specific benchmarks like VQA-RAD, SLAKE, and PathVQA that test the model's capability in visual question answering in radiology, pathology, and more.
-
Supervised Fine-Tuning Results: The table showcases the results from the supervised fine-tuning experiments with different methods:
| Method | VQA-RAD (Ref) | VQA-RAD (Open) | VQA-RAD (Closed) | SLAKE (Ref) | SLAKE (Open) | SLAKE (Closed) | PathVQA (Ref) | PathVQA (Open) | PathVQA (Closed) |
|---|---|---|---|---|---|---|---|---|---|
| LLaVA | 50.00 | 65.07 | 78.18 | 63.22 | 7.74 | 63.20 | |||
| LLaVA-Med (LLaVA) | 61.52 | 84.19 | 83.08 | 85.34 | 37.95 | 91.21 | |||
| LLaVA-Med (Vicuna) | 64.39 | 81.98 | 84.71 | 83.17 | 38.87 | 91.65 | |||
| LLaVA-Med (BioMed) | 64.75 | 83.09 | 87.11 | 86.78 | 39.60 | 91.09 |
Metrics Descriptions:
-
Method: This denotes the specific version or approach of the model that's being evaluated. It encompasses various iterations and sources of LLaVA and LLaVA-Med.
-
VQA-RAD (Ref, Open, Closed): Metrics for the Visual Question Answering in Radiology. 'Ref' refers to the reference score, 'Open' to the open-ended questions score, and 'Closed' to the closed-ended questions score.
-
SLAKE (Ref, Open, Closed): Metrics for the SLAKE benchmark. 'Ref' represents the reference score, 'Open' corresponds to the open-ended questions score, and 'Closed' is for the closed-ended questions score.
-
PathVQA (Ref, Open, Closed): Metrics related to Pathology Visual Question Answering. 'Ref' indicates the reference score, 'Open' stands for the open-ended questions score, and 'Closed' signifies the closed-ended questions score.
Reference: Research Source (opens in a new tab)
By juxtaposing LLaVA-Med's results derived from various methods, it's evident that the model exhibits formidable performance in visual biomedical interpretations, especially when evaluated against benchmarks like VQA-RAD and SLAKE. This proficiency underscores its potential in aiding medical professionals in making more informed decisions based on visual data.
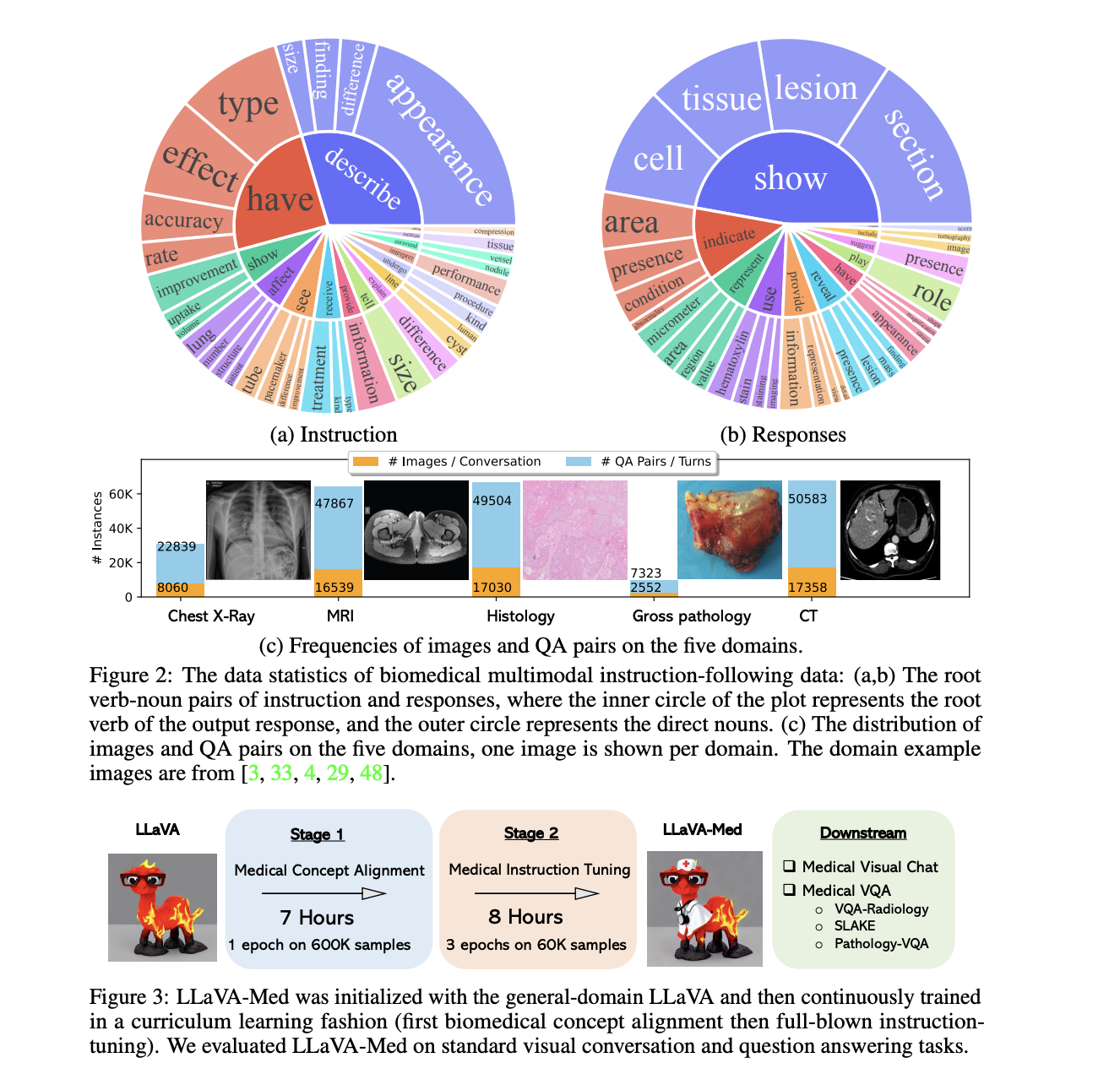
2. LLaVA-Med's Proficiency in Instruction-Following:
Originating from the extensive LLaVA model, LLaVA-Med's expertise is pronounced due to its tailored emphasis on biomedical nuances.
-
Dataset for Model Refinement: LLaVA-Med's enhancement utilized the Biomedical multimodal instruction-following dataset. Encompassing diverse real-world biomedical contexts, this dataset ensures LLaVA-Med's adeptness in medical knowledge articulation and comprehension.
-
Insights into the Dual-Phase Adaptation:
- Phase 1 (Biomedical Concept Integration): This foundational phase was crucial. It was directed at merging LLaVA's comprehensive knowledge with distinct biomedical concepts. This step ensured the subsequent refinement was in line with medical intricacies.
- Phase 2 (Comprehensive Instructional Tuning): A pivotal juncture, this stage subjected the model to intensive training on biomedical directives, fortifying its ability to intuitively understand, engage, and address medical contexts.
Comparative Performance of LLaVA versus LLaVA-Med:
| Model Iteration | Conversation (%) | Description (%) | CXR (%) | MRI (%) | Histology (%) | Gross (%) | CT (%) | Cumulative (%) |
|---|---|---|---|---|---|---|---|---|
| LLaVA | 39.4 | 26.2 | 41.6 | 33.4 | 38.4 | 32.9 | 33.4 | 36.1 |
| LLaVA-Med Phase 1 | 22.6 | 25.2 | 25.8 | 19.0 | 24.8 | 24.7 | 22.2 | 23.3 |
| LLaVA-Med Phase 2 | 52.4 | 49.1 | 58.0 | 50.8 | 53.3 | 51.7 | 52.2 | 53.8 |
Metric Descriptions:
-
Model Iteration: Designates the particular iteration or phase of the model being scrutinized. It includes the overarching LLaVA, LLaVA-Med post the primary phase, and post the secondary phase.
-
Conversation (%): A metric highlighting the model's proficiency in maintaining a contextual dialogue and offering relevant responses.
-
Description (%): A marker for the model's ability to thoroughly elucidate medical visuals, ensuring that conveyed details are precise.
-
CXR (%): Dedicated to evaluating LLaVA-Med's accuracy when interpreting Chest X-Rays, an indispensable tool in clinical diagnostics.
-
MRI (%): Measures the model's aptitude in analyzing and explaining Magnetic Resonance Imaging results. MRIs, with their detailed insights, are crucial in medical diagnosis and therapeutic decisions.
-
Histology (%): A reflection of the model's efficacy in scrutinizing microscopic tissue studies, essential for pinpointing cellular irregularities.
-
Gross (%): A measure of LLaVA-Med's capacity in elucidating gross anatomical structures, those visible without microscopic assistance.
-
CT (%): Rates the model's precision in interpreting Computerized Tomography scans, known for their comprehensive, cross-sectional body visuals.
-
Cumulative (%): A consolidated score, encapsulating the model's performance across varied categories.
Reference: Research Source (opens in a new tab)
3. LLaVA-Med Visual Chatbot, In Simple Words:
LLaVA-Med isn’t just good with words; it's great at understanding pictures too.
-
Good at Many Things: LLaVA-Med knows a lot about different medical images. It can look at pictures from X-Rays to MRIs and even tiny tissue images.
-
Lots of Data: What makes it so good? It has seen and learned from many pictures and text. So, it knows about things like X-Rays, body scans, and even simple body pictures.
-
Uses in the Real World: Think about doctors who look at hundreds of X-rays. LLaVA-Med can help by quickly checking these pictures, pointing out problems, and making the doctor's job easier.
-
How It Compares to GPT-4: GPT-4 is great with words. But when it comes to understanding medical pictures and talking about them, LLaVA-Med does a better job. It can look at a medical picture and talk about it in detail.
-
It’s Not Perfect: Like everything, LLaVA-Med has its limits. Sometimes, it might get confused if a picture is too different from what it knows. But as it sees more pictures, it can learn and get better.
You can test out an online version of LLaVA-Med here (opens in a new tab).
How to Install LLaVA-Med: A Step-by-Step
Getting LLaVA-Med up and running involves a few more steps than the general-purpose LLaVA model, given its specialized nature. Here's how to do it:
Step 1: Initiating the LLaVA-Med Repository
Cloning Made Easy:
Kick things off by cloning the LLaVA-Med Repository. Fire up your terminal and punch in:
git clone https://github.com/microsoft/LLaVA-Med.gitThis command fetches all the necessary files directly from Microsoft's repository to your machine.
Step 2: Diving into the LLaVA-Med Directory
Navigation Essentials:
Having cloned the repository, your next move is to switch your working directory. Here's how:
cd LLaVA-MedBy running this command, you position yourself in the heart of LLaVA-Med's directory, ready to proceed to the next phase.
Step 3: Setting Up the Foundation - Installing Packages
A Foundation Built on Dependencies:
Every intricate software comes with its set of dependencies. LLaVA-Med is no exception. With the following command, you'll install everything it needs to operate smoothly:
pip install -r requirements.txtRemember, this isn't just about installing packages. It's about creating a conducive environment for LLaVA-Med to showcase its capabilities.
Step 4: Engaging with LLaVA-Med
Running Sample Prompts to Witness the Magic:
Ready for some action? Start by integrating the LLaVA-Med model into your Python script:
from LLaVAMed import LLaVAMedGet the model running:
model = LLaVAMed()Dive into a sample medical text analysis:
text_output = model.analyze_medical_text("Describe the symptoms of pneumonia.")
print(text_output)And for those keen on medical image analysis:
image_output = model.analyze_medical_image("path/to/xray.jpg")
print(image_output)Executing these commands unveils LLaVA-Med's analytical prowess. For instance, the medical text analysis might illuminate symptoms, causative factors, and potential treatments for pneumonia. On the other hand, the image analysis could pinpoint any discrepancies or abnormalities in the X-ray. You can check out the LLaVA-Med GitHub Source Code (opens in a new tab).
Conclusion
While AI in medical imaging shows immense promise in terms of accuracy and efficiency, it is not yet at a stage where it can completely replace human doctors. The technology serves as a powerful tool for aiding diagnosis but requires the oversight and experience of a medical professional to provide the most reliable and holistic care. Therefore, the focus should be on creating a collaborative environment where AI and human expertise can coexist to provide the highest quality of healthcare.
Want to learn the latest LLM News? Check out the latest LLM leaderboard!
