How Groq AI Makes LLM Queries x10 Faster

Groq, a generative AI solutions company, is redefining the landscape of large language model (LLM) inference with its groundbreaking Language Processing Unit (LPU) Inference Engine. This purpose-built accelerator is designed to overcome the limitations of traditional CPU and GPU architectures, delivering unparalleled speed and efficiency in LLM processing.
Want to learn the latest LLM News? Check out the latest LLM leaderboard!

The LPU Architecture: A Deep Dive
At the core of Groq's LPU architecture lies a single-core design that prioritizes sequential performance. This approach enables the LPU to achieve exceptional compute density, with a peak performance of 1 PetaFLOP/s in a single chip. The LPU's unique architecture also eliminates external memory bottlenecks by incorporating 220 MB of on-chip SRAM, providing a staggering 1.5 TB/s of memory bandwidth.
The LPU's synchronous networking capabilities allow for seamless scalability in large-scale deployments. With a bi-directional bandwidth of 1.6 TB/s per LPU, Groq's technology can efficiently handle the massive data transfers required for LLM inference. Additionally, the LPU supports a wide range of precision levels, from FP32 down to INT4, enabling high accuracy even at lower precision settings.
Benchmarking Groq's Performance
Groq's LPU Inference Engine has consistently outperformed industry giants in various benchmarks. In internal tests conducted on Meta AI's Llama-2 70B model, Groq achieved a remarkable 300 tokens per second per user. This represents a significant leap forward in LLM inference speed, surpassing the performance of traditional GPU-based systems.
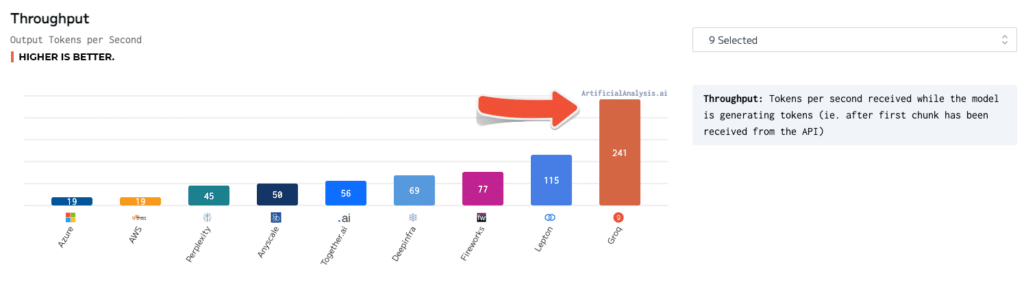
Independent benchmarks have further validated Groq's superiority. In tests conducted by ArtificialAnalysis.ai, Groq's Llama 2 Chat (70B) API achieved a throughput of 241 tokens per second, more than double the speed of other hosting providers. Groq also excelled in other key performance indicators, such as latency vs. throughput, total response time, and throughput variance.
To put these numbers into perspective, consider a scenario where a user interacts with an AI-powered chatbot. With Groq's LPU Inference Engine, the chatbot can generate responses at a rate of 300 tokens per second, enabling near-instantaneous conversations. In contrast, a GPU-based system might only achieve 50-100 tokens per second, resulting in noticeable delays and a less engaging user experience.
Groq vs. Other AI Technologies

When compared to NVIDIA's GPUs, Groq's LPU demonstrates a clear advantage in INT8 performance, which is crucial for high-speed LLM inference. In a benchmark comparing the LPU to NVIDIA's A100 GPU, the LPU achieved a 3.5x speedup on the Llama-2 70B model, processing 300 tokens per second compared to the A100's 85 tokens per second.
Groq's technology also stands out against other AI models like ChatGPT and Google's Gemini. While specific performance numbers for these models are not publicly available, Groq's demonstrated speed and efficiency suggest that it has the potential to outperform them in real-world applications.
Using Groq AI
Groq offers a comprehensive suite of tools and services to facilitate the deployment and utilization of its LPU technology. The GroqWare suite, which includes the Groq Compiler, provides a push-button experience for getting models up and running quickly. Here's an example of how to compile and run a model using the Groq Compiler:
# Compile the model
groq compile model.onnx -o model.groq
# Run the model on the LPU
groq run model.groq -i input.bin -o output.binFor those seeking more customization, Groq also allows hand-coding to the Groq architecture, enabling the development of tailored applications and maximum performance optimization. Here's an example of hand-coded Groq assembly for a simple matrix multiplication:
; Matrix multiplication on the Groq LPU
; Assumes matrices A and B are loaded into memory
; Load matrix dimensions
ld r0, [n]
ld r1, [m]
ld r2, [k]
; Initialize result matrix C
mov r3, 0
; Outer loop over rows of A
mov r4, 0
loop_i:
; Inner loop over columns of B
mov r5, 0
loop_j:
; Accumulate dot product
mov r6, 0
mov r7, 0
loop_k:
ld r8, [A + r4 * m + r7]
ld r9, [B + r7 * k + r5]
mul r10, r8, r9
add r6, r6, r10
add r7, r7, 1
cmp r7, r2
jlt loop_k
; Store result in C
st [C + r4 * k + r5], r6
add r5, r5, 1
cmp r5, r2
jlt loop_j
add r4, r4, 1
cmp r4, r0
jlt loop_iDevelopers and researchers can also leverage Groq's powerful technology through the Groq API, which provides access to real-time inference capabilities. Here's an example of how to use the Groq API to generate text using the Llama-2 70B model:
import groq
# Initialize the Groq client
client = groq.Client(api_key="your_api_key")
# Set up the model and parameters
model = "llama-2-70b"
prompt = "Once upon a time, in a land far, far away..."
max_tokens = 100
# Generate text
response = client.generate(model=model, prompt=prompt, max_tokens=max_tokens)
# Print the generated text
print(response.text)Potential Applications and Impact
The near-instantaneous response times enabled by Groq's LPU Inference Engine are unlocking new possibilities across industries. In the realm of finance, Groq's technology can be leveraged for real-time fraud detection and risk assessment. By processing vast amounts of transaction data and identifying anomalies in milliseconds, financial institutions can prevent fraudulent activities and protect their customers' assets.
In healthcare, Groq's LPU can revolutionize patient care by enabling real-time analysis of medical data. From processing medical images to analyzing electronic health records, Groq's technology can assist healthcare professionals in making rapid and accurate diagnoses, ultimately improving patient outcomes.
Autonomous vehicles can also benefit greatly from Groq's high-speed inference capabilities. By processing sensor data and making split-second decisions, Groq-powered AI systems can enhance the safety and reliability of self-driving cars, paving the way for a future of intelligent transportation.
Conclusion
Groq's LPU Inference Engine represents a significant leap forward in the field of AI acceleration. With its innovative architecture, impressive benchmarks, and comprehensive suite of tools and services, Groq is empowering developers and organizations to push the boundaries of what's possible with large language models.
As the demand for real-time AI inference continues to grow, Groq is well-positioned to lead the charge in enabling the next generation of AI-powered solutions. From chatbots and virtual assistants to autonomous systems and beyond, the potential applications of Groq's technology are vast and transformative.
With its commitment to democratizing AI access and fostering innovation, Groq is not only revolutionizing the technical landscape but also shaping the future of how we interact with and benefit from artificial intelligence. As we stand on the cusp of an AI-driven era, Groq's groundbreaking technology is poised to be a catalyst for unprecedented advancements and discoveries in the years to come.
Want to learn the latest LLM News? Check out the latest LLM leaderboard!