LlamaIndex: the LangChain Alternative that Scales LLMs

Introduction: What is LlamaIndex?
LlamaIndex is a high-performance indexing tool specifically engineered to augment the capabilities of Large Language Models (LLMs). It's not just a query optimizer; it's a comprehensive framework that offers advanced features like response synthesis, composability, and efficient data storage. If you're dealing with complex queries and require high-quality, contextually relevant responses, LlamaIndex is your go-to solution.
In this article, we'll take a technical deep-dive into LlamaIndex, exploring its core components, advanced features, and how to effectively implement it in your projects. We'll also compare it with similar tools like LangChain to give you a complete understanding of its capabilities.
Want to learn the latest LLM News? Check out the latest LLM leaderboard!
What is LlamaIndex, Anyway?
LlamaIndex is a specialized tool designed to augment the functionalities of Large Language Models (LLMs). It serves as a comprehensive solution for specific LLM interactions, particularly excelling in scenarios that demand precise queries and high-quality responses.
Querying: Optimized for quick data retrieval, making it ideal for speed-sensitive applications. Response Synthesis: Streamlined to produce concise and contextually relevant responses. Composability: Allows for building complex queries and workflows using modular and reusable components.
Now, let's get into the details about LlamaIndex, shall we?
What are Indexes in LlamaIndex?
Indexes are the core of LlamaIndex, serving as the data structures that hold the information to be queried. LlamaIndex offers multiple types of indexes, each optimized for specific tasks.

Types of Indexes in LlamaIndex
- Vector Store Index: Utilizes k-NN algorithms and is optimized for high-dimensional data.
- Keyword-based Index: Employs TF-IDF for text-based queries.
- Hybrid Index: A combination of Vector and Keyword-based indexes, offering a balanced approach.
Vector Store Index in LlamaIndex
The Vector Store Index is your go-to for anything related to high-dimensional data. It's particularly useful for machine learning applications where you're dealing with complex data points.
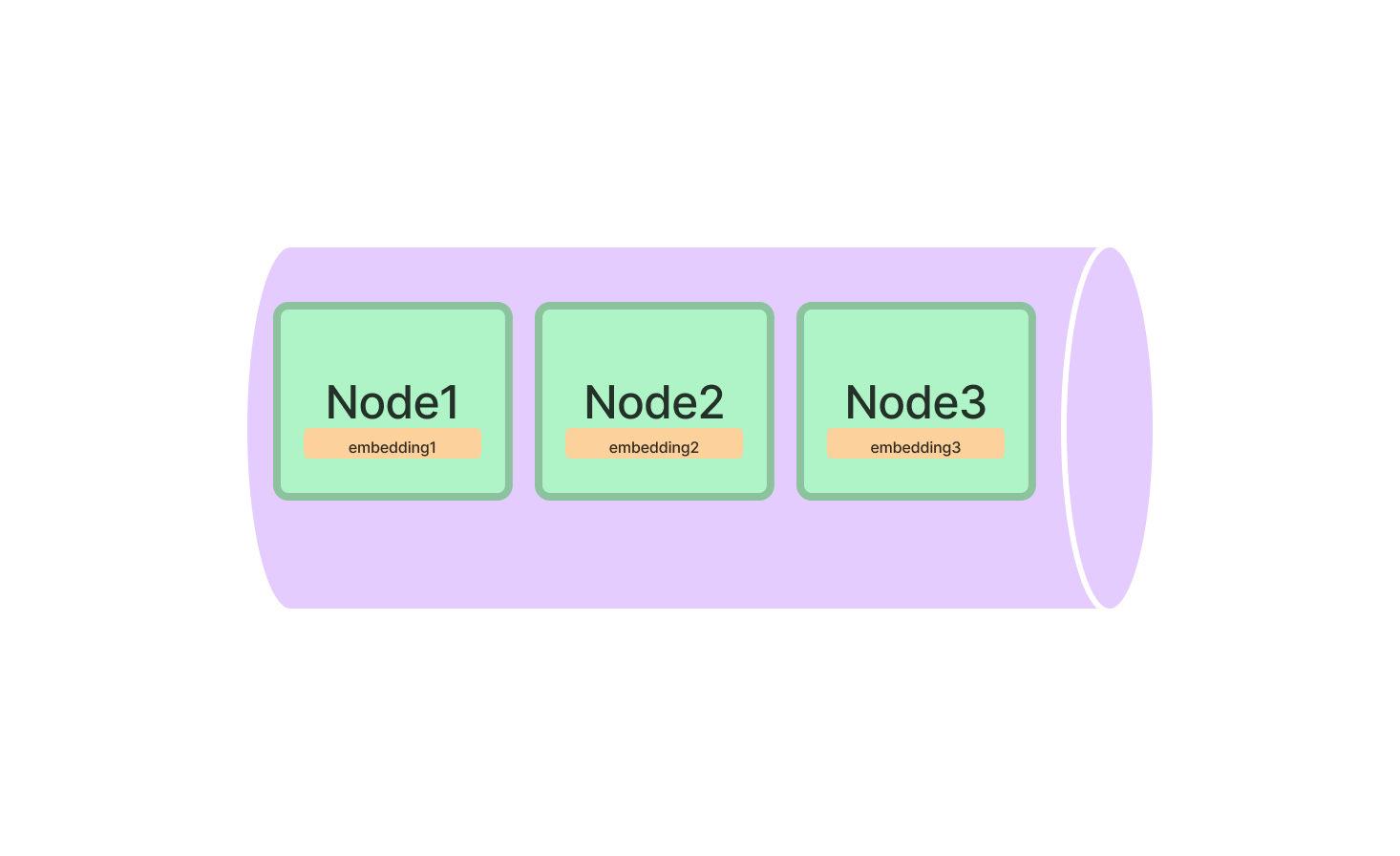
To get started, you'll need to import the VectorStoreIndex class from the LlamaIndex package. Once imported, initialize it by specifying the dimensions of your vectors.
from llamaindex import VectorStoreIndex
vector_index = VectorStoreIndex(dimensions=300)This sets up a Vector Store Index with 300 dimensions, ready to handle your high-dimensional data. You can now add vectors to the index and run queries to find the most similar vectors.
# Adding a vector
vector_index.add_vector(vector_id="vector_1", vector_data=[0.1, 0.2, 0.3, ...])
# Running a query
query_result = vector_index.query(vector=[0.1, 0.2, 0.3, ...], top_k=5)Keyword-based Index in LlamaIndex
If you're more into text-based queries, the Keyword-based Index is your ally. It uses the TF-IDF algorithm to sift through textual data, making it ideal for natural language queries.
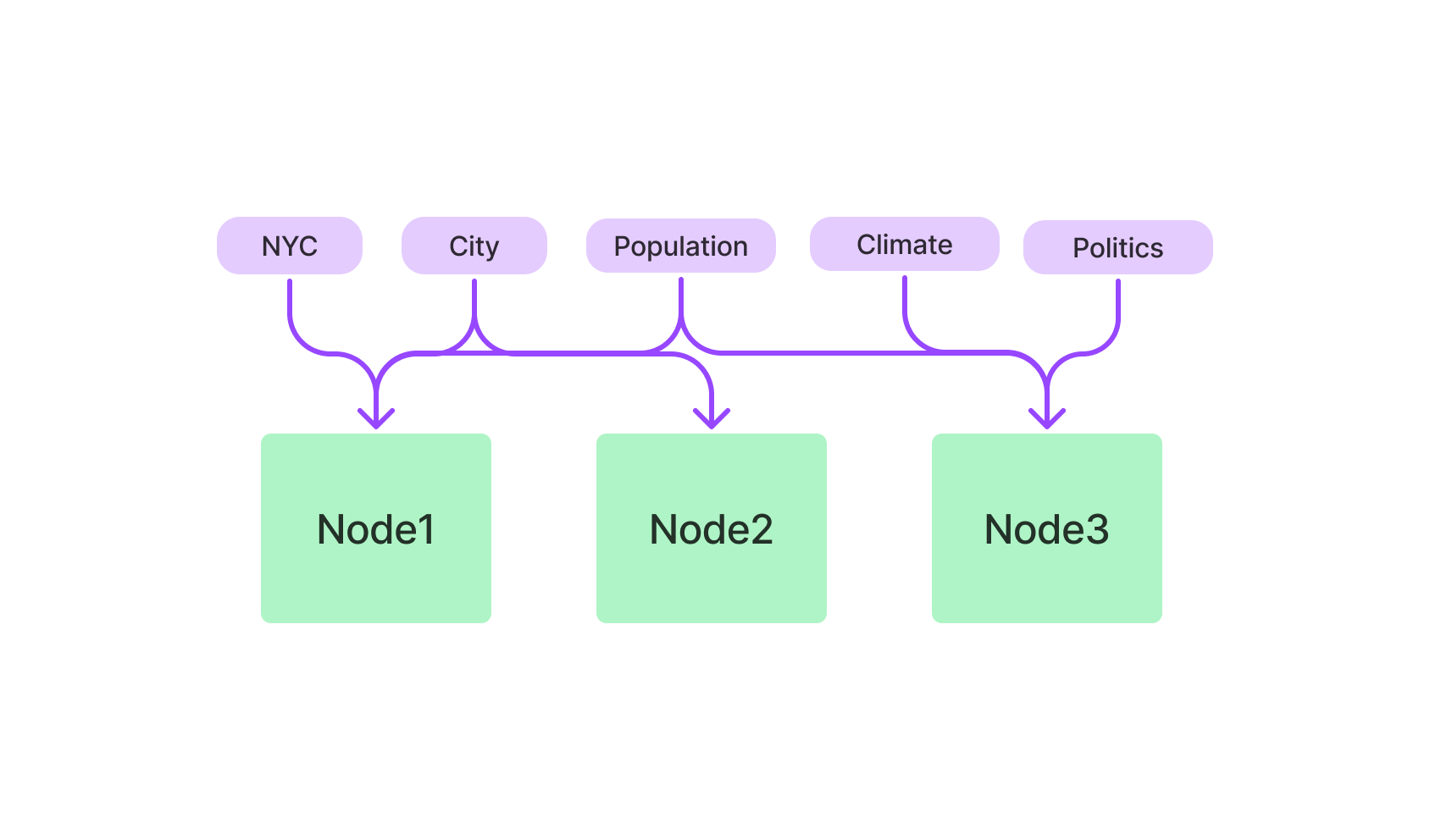
Kick off by importing the KeywordBasedIndex class from the LlamaIndex package. Once that's done, initialize it.
from llamaindex import KeywordBasedIndex
text_index = KeywordBasedIndex()You're now set to add text data to this index and run text-based queries.
# Adding text data
text_index.add_text(text_id="document_1", text_data="This is a sample document.")
# Running a query
query_result = text_index.query(text="sample", top_k=3)Quick Start with LlamaIndex: Step-by-Step Guide
Installing and initializing LlamaIndex is just the beginning. To truly harness its power, you need to know how to use it effectively.
Installing LlamaIndex
First, let's get it onto your machine. Open your terminal and run:
pip install llamaindexOr if you're using conda:
conda install -c conda-forge llamaindexInitializing LlamaIndex
After the installation is complete, you'll need to initialize LlamaIndex in your Python environment. This is where you set the stage for all the magic that follows.
from llamaindex import LlamaIndex
index = LlamaIndex(index_type="vector_store", dimensions=300)Here, index_type specifies what kind of index you're setting up, and dimensions is for specifying the size of the Vector Store Index.
How to Query with LlamaIndex's Vector Store Index
After successfully setting up LlamaIndex, you're poised to explore its powerful querying capabilities. The Vector Store Index is engineered to manage complex, high-dimensional data, making it a go-to tool for machine learning, data analysis, and other computational tasks.
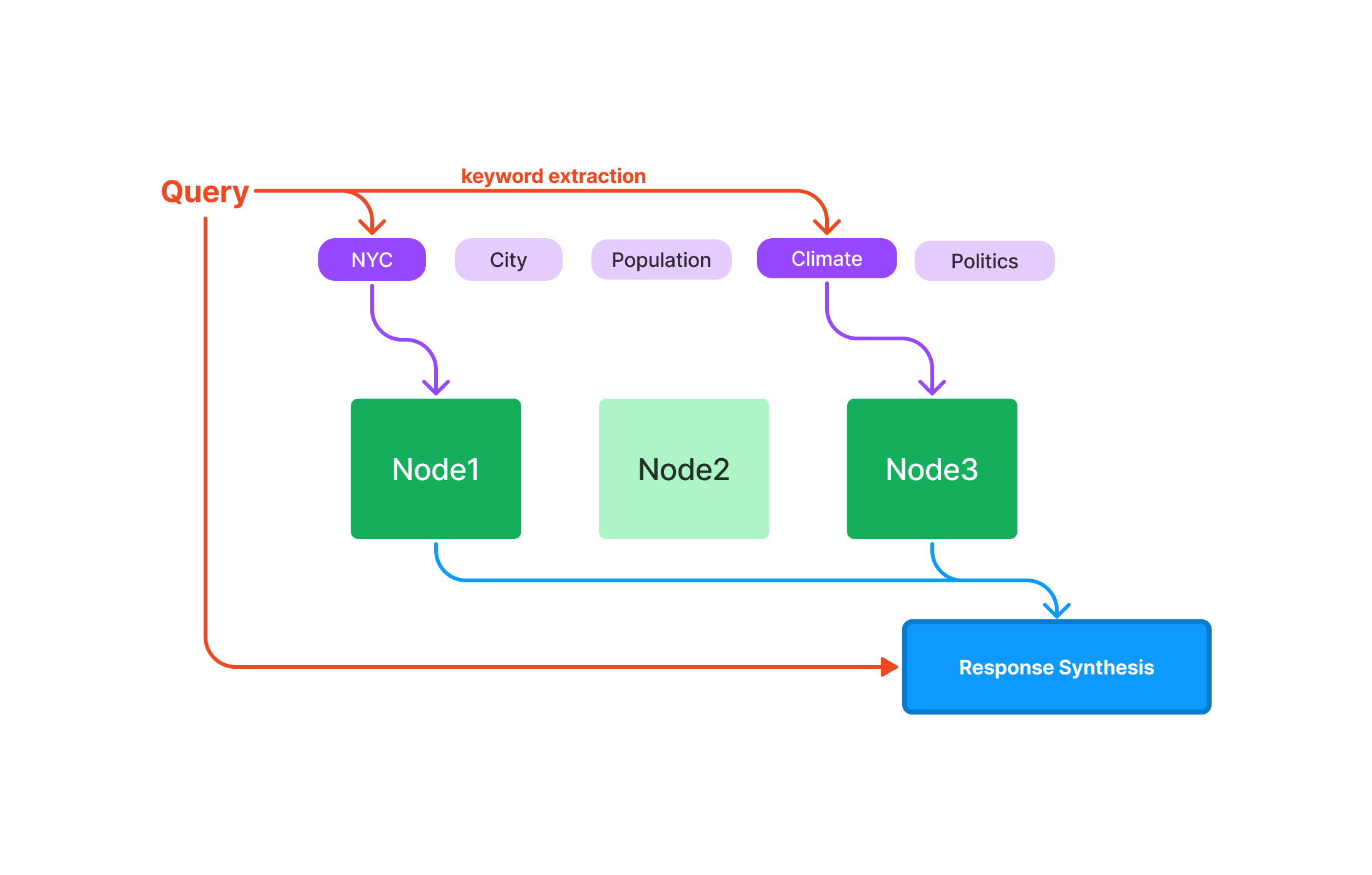
Make Your First Query in LlamaIndex
Before diving into the code, it's crucial to understand the basic elements of a query in LlamaIndex:
-
Query Vector: This is the vector you're interested in finding similarities for within your dataset. It should be in the same dimensional space as the vectors you've indexed.
-
top_kParameter: This parameter specifies the number of closest vectors to your query vector that you wish to retrieve. The "k" intop_kstands for the number of nearest neighbors you're interested in.
Here's a breakdown of how to make your first query:
-
Initialize Your Index: Make sure your index is loaded and ready for querying.
-
Specify the Query Vector: Create a list or array that contains the elements of your query vector.
-
Set the
top_kParameter: Decide how many of the closest vectors you want to retrieve. -
Execute the Query: Use the
querymethod to perform the search.
Here's a sample Python code snippet to illustrate these steps:
# Initialize your index (assuming it's named 'index')
# ...
# Define the query vector
query_vector = [0.2, 0.4, 0.1, ...]
# Set the number of closest vectors to retrieve
top_k = 5
# Execute the query
query_result = index.query(vector=query_vector, top_k=top_k)Fine-Tuning Your Queries in LlamaIndex
Why Fine-Tuning Matters?
Fine-tuning your queries allows you to adapt the search process to the specific requirements of your project. Whether you're dealing with text, images, or any other type of data, fine-tuning can significantly improve the accuracy and efficiency of your queries.
Key Parameters for Fine-Tuning:
-
Distance Metric: LlamaIndex allows you to choose between different distance metrics, such as 'euclidean' and 'cosine'.
-
Euclidean Distance: This is the "ordinary" straight-line distance between two points in Euclidean space. Use this metric when the magnitude of the vectors is important.
-
Cosine Similarity: This metric measures the cosine of the angle between two vectors. Use this when you're more interested in the direction of the vectors rather than their magnitude.
-
-
Batch Size: If you're dealing with a large dataset or need to make multiple queries, setting a batch size can speed up the process by querying multiple vectors at once.
Step-by-Step Guide to Fine-Tuning:
Here's how to go about fine-tuning your query:
-
Choose the Distance Metric: Decide between 'euclidean' and 'cosine' based on your specific needs.
-
Set the Batch Size: Determine the number of vectors you want to process in a single batch.
-
Execute the Fine-Tuned Query: Use the
querymethod again, but this time include the additional parameters.
Here's a Python code snippet to demonstrate:
# Define the query vector
query_vector = [0.2, 0.4, 0.1, ...]
# Set the number of closest vectors to retrieve
top_k = 5
# Choose the distance metric
distance_metric = 'euclidean'
# Set the batch size for multiple queries
batch_size = 100
# Execute the fine-tuned query
query_result = index.query(vector=query_vector, top_k=top_k, metric=distance_metric, batch_size=batch_size)By mastering these fine-tuning techniques, you can make your LlamaIndex queries more targeted and efficient, thereby extracting the most value from your high-dimensional data.
What Can You Make with LlamaIndex?
So you've got the basics down, but what can you actually build with LlamaIndex? The possibilities are vast, especially when you consider its compatibility with Large Language Models (LLMs).
LlamaIndex for Advanced Search Engines
One of the most compelling uses of LlamaIndex is in the realm of advanced search engines. Imagine a search engine that not only retrieves relevant documents but also understands the context of your query. With LlamaIndex, you can build just that.
Here's a quick example to demonstrate how you could set up a basic search engine using LlamaIndex's Keyword-based Index.
# Initialize the Keyword-based Index
from llamaindex import KeywordBasedIndex
search_index = KeywordBasedIndex()
# Add some documents
search_index.add_text("doc1", "Llamas are awesome.")
search_index.add_text("doc2", "I love programming.")
# Run a query
results = search_index.query("Llamas", top_k=2)LlamaIndex for Recommendation Systems
Another fascinating application is in building recommendation systems. Whether it's suggesting similar products, articles, or even songs, LlamaIndex's Vector Store Index can be a game-changer.
Here's how you could set up a basic recommendation system:
# Initialize the Vector Store Index
from llamaindex import VectorStoreIndex
rec_index = VectorStoreIndex(dimensions=50)
# Add some product vectors
rec_index.add_vector("product1", [0.1, 0.2, 0.3, ...])
rec_index.add_vector("product2", [0.4, 0.5, 0.6, ...])
# Run a query to find similar products
similar_products = rec_index.query(vector=[0.1, 0.2, 0.3, ...], top_k=5)LlamaIndex vs. LangChain
When it comes to developing applications powered by Large Language Models (LLMs), the choice of framework can significantly impact the project's success. Two frameworks that have gained attention in this space are LlamaIndex and LangChain. Both have their unique features and advantages, but they serve different needs and are optimized for specific tasks. In this section, we'll delve into the technical details and provide sample code to help you understand the key differences between these two frameworks, especially in the context of Retrieval-Augmented Generation (RAG) for chatbot development.
Core Features and Technical Capabilities
LangChain
-
General-Purpose Framework: LangChain is designed to be a versatile tool for a wide array of applications. It not only allows for data loading, processing, and indexing but also provides functionalities for interacting with LLMs.
Sample Code:
const res = await llm.call("Tell me a joke"); -
Flexibility: One of LangChain's standout features is its flexibility. It allows users to customize the behavior of their applications extensively.
-
High-Level APIs: LangChain abstracts most of the complexities involved in working with LLMs, offering high-level APIs that are simple and easy to use.
Sample Code:
const chain = new SqlDatabaseChain({ llm: new OpenAI({ temperature: 0 }), database: db, sqlOutputKey: "sql", }); const res = await chain.call({ query: "How many tracks are there?" }); -
Off-the-Shelf Chains: LangChain comes pre-loaded with off-the-shelf chains like
SqlDatabaseChain, which can be customized or used as a base for building new applications.
LlamaIndex
-
Specialized for Search and Retrieval: LlamaIndex is engineered for building search and retrieval applications. It offers a simple interface for querying LLMs and retrieving relevant documents.
Sample Code:
query_engine = index.as_query_engine() response = query_engine.query("Stackoverflow is Awesome.") -
Efficiency: LlamaIndex is optimized for performance, making it a better choice for applications that need to process large volumes of data quickly.
-
Data Connectors: LlamaIndex can ingest data from various sources, including APIs, PDFs, SQL databases, and more, allowing for seamless integration into LLM applications.
-
Optimized Indexing: One of LlamaIndex's key features is its ability to structure ingested data into intermediate representations that are optimized for quick and efficient querying.
When to Use Which Framework?
-
General-Purpose Applications: If you're building a chatbot that needs to be flexible and versatile, LangChain is the ideal choice. Its general-purpose nature and high-level APIs make it suitable for a broad range of applications.
-
Search and Retrieval Focus: If your chatbot's primary function is to search and retrieve information, LlamaIndex is the better option. Its specialized indexing and retrieval capabilities make it highly efficient for such tasks.
-
Combining Both: In some scenarios, it might be beneficial to use both frameworks. LangChain can handle general functionalities and interactions with LLMs, while LlamaIndex can manage specialized search and retrieval tasks. This combination can offer a balanced approach, leveraging the flexibility of LangChain and the efficiency of LlamaIndex.
Sample Code for Combined Use:
# LangChain for general functionalities res = llm.call("Tell me a joke") # LlamaIndex for specialized search query_engine = index.as_query_engine() response = query_engine.query("Tell me about climate change.")
So, Which One I Should Choose? LangChain or LlamaIndex?
Choosing between LangChain and LlamaIndex—or deciding to use both—should be guided by the specific requirements and objectives of your project. LangChain offers a broader range of capabilities and is ideal for general-purpose applications. In contrast, LlamaIndex specializes in efficient search and retrieval, making it suitable for data-intensive tasks. By understanding the technical nuances and capabilities of each framework, you can make an informed decision that best aligns with your chatbot development needs.
Conclusion
By now, you should have a solid grasp of what LlamaIndex is all about. From its specialized indexes to its wide range of applications and its edge over other tools like LangChain, LlamaIndex proves to be an indispensable tool for anyone working with Large Language Models. Whether you're building a search engine, a recommendation system, or any application that requires efficient querying and data retrieval, LlamaIndex has got you covered.
FAQs About LlamaIndex
Let's address some of the most common questions people have about LlamaIndex.
What is LlamaIndex Used For?
LlamaIndex is primarily used as an intermediary layer between users and Large Language Models. It excels in query execution, response synthesis, and data integration, making it ideal for a variety of applications like search engines and recommendation systems.
Is LlamaIndex Free to Use?
Yes, LlamaIndex is an open-source tool, making it free to use. You can find its source code on GitHub and contribute to its development.
What is GPT Index and LlamaIndex?
GPT Index is designed for text-based queries and is generally used with GPT (Generative Pre-trained Transformer) models. LlamaIndex, on the other hand, is more versatile and can handle both text-based and vector-based queries, making it compatible with a wider range of Large Language Models.
What is the LlamaIndex Architecture?
LlamaIndex is built on a modular architecture that includes various types of indexes like the Vector Store Index and Keyword-based Index. It's primarily written in Python and supports multiple algorithms like k-NN, TF-IDF, and BERT embeddings.
Want to learn the latest LLM News? Check out the latest LLM leaderboard!
